Introduction to Paiton by ElioVP
Oct 10, 2025

ElioVP is a Belgium-based company with an engineering team focusing on performance tooling, agents and industrial AI applications with AMD platforms. ElioVP started Paiton in 2023 after identifying substantial optimization headroom on AMD GPUs. Building on years of experience and collaboration with AMD, including open-source work such as Eliovp’s AMD Mem Tweak, Paiton was designed as a framework that translates a model's architecture into highly optimized fused kernels, delivering consistent double-digit gains in throughput and cost efficiency. Paiton also aligns with our broader practice of building agentic-AI solutions that train and serve on customer-owned AMD infrastructure, keeping data local by design. With more than 250,000 GPUs deployed across customer environments worldwide, the focus remains clear: predictable performance, operational reliability, and time-to-value at scale.
If you’re new to Paiton and aren’t sure what it does, we recommend reading the first blog: AI Model Optimization with Paiton. In short: Paiton translates an AI model's architecture into highly optimized kernels, enabling much faster and more efficient inference compared to traditional implementations.
How Paiton Works Under the Hood
- Compile the Model – Paiton compiles an existing AI model into a .so file with optimized kernels.
- Load into vLLM –
paiton-runtimeensures that vLLM can leverage this .so file that contains the optimized kernels. - Run Inference – LLMs (e.g., Llama 3, Qwen 3) models run at peak performance.
Visualizing the Process
Compile process (done by ElioVP servers)
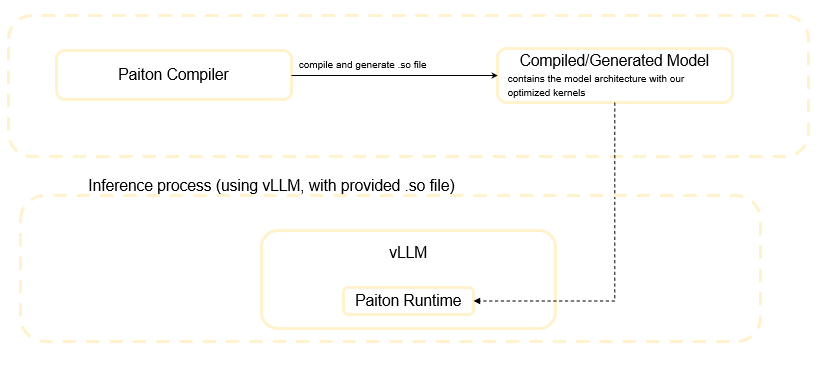
Running Paiton with our Docker Image
To make things simple, ElioVP provides a ready-to-use Docker image that comes preloaded with the optimized model amd/Llama-3.1-8B-Instruct-FP8-KV.
Note: this model is just one of the many models optimized with Paiton. They are including it for a limited evaluation period to help users test and explore Paiton’s performance. The framework also supports a wide range of LLMs.
This way, you don’t need to worry about compilation or setup, everything is packaged and ready for immediate use.
Step 1: Pull the Docker Image
docker pull ghcr.io/eliovp-bv/paiton-eval:latest
Note: This Docker image includes the amd/Llama-3.1-8B-Instruct-FP8-KV model, eliminating the need for a separate HuggingFace download. The model is ready-to-use within the Docker image, though users can still download the original weights if preferred.
Step 2: Run the Container
docker run -it --network=host --device=/dev/kfd --device=/dev/dri --group-add=video --ipc=host --cap-add=SYS_PTRACE --security-opt seccomp=unconfined ghcr.io/eliovp-bv/paiton-eval:latest
This will launch the container with the available GPUs.
What You Can Expect Before Testing
If you need to see some results before testing it out, here’s what can be achieved with our optimized models.
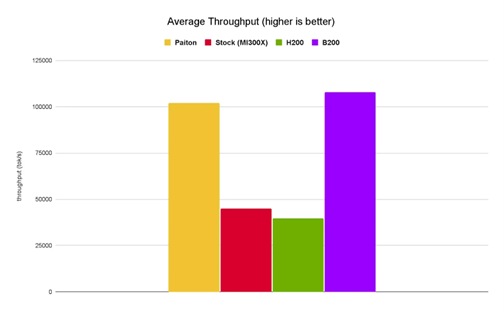
In the previous benchmarks, Paiton-compiled models consistently outperformed stock implementations in both throughput and cost efficiency. For example, on AMD GPUs we demonstrated significant improvements in tokens/sec and reduced cost per 1M tokens1.
We’ve documented the full step-by-step process in this earlier blog post: MI300X FP8 Data‑Parallel Benchmarks (8–64 GPUs): H200 Left Behind, B200 Within Reach
Model Serving
Once inside the container, you can start serving the AMD/Llama-3.1-8B-Instruct-FP8-KV model with:
python3 /app/wrap_vllm_entrypoint.py \
--model /app/Llama-3.1-8B-Instruct-FP8-KV/ \
--served-model-name amd/Llama-3.1-8B-Instruct-FP8-KV \
--num-scheduler-steps 10 \
--compilation-config '{"use_cudagraph": false, "cudagraph_capture_sizes": []}' \
--max-model-len 4096 \
--kv-cache-dtype fp8
● --model: Path to the model files
● --served-model-name: Name identifier for the served model
● --num-scheduler-steps: Number of scheduler steps for request processing
● --compilation-config: JSON config for CUDA graph optimization (disabled for Paiton compatibility)
● --max-model-len: Maximum sequence length (4096 tokens)
● --kv-cache-dtype fp8: Use FP8 precision for key-value cache (memory optimization)
Features
● FP8 Key-Value Cache – reduces memory usage while maintaining accuracy.
● Paiton Integration – AMD-optimized inference kernels.
● vLLM Backend – high-performance serving with efficient request handling.
● Custom Entry Point – seamless integration of Paiton models with vLLM.
Benchmarking Performance
You can benchmark the model using the ShareGPT dataset:
python3 /app/vllm/benchmarks/benchmark_serving.py \
--backend vllm \
--model amd/Llama-3.1-8B-Instruct-FP8-KV \
--dataset-name sharegpt \
--dataset-path /app/vllm/benchmarks/ShareGPT_V3_unfiltered_cleaned_split.json \
--num-prompts 1024 \
--random-range-ratio 1.0 \
--percentile-metrics ttft,tpot,itl,e2el \
--sharegpt-output-len 256
This will provide metrics such as:
● Throughput: requests per second
● Latency: response time (TTFT, TPOT, ITL, E2EL)
● Memory usage: GPU memory footprint
● Token generation speed: tokens per second
Troubleshooting
Common Issues
- Out of Memory → reduce --
max-model-len. - Model Loading Errors → verify model path.
- Performance Issues → confirm
--num-scheduler-steps 10and monitor GPU utilization.
Health Endpoints
● GET /health: basic health check
● GET /v1/models: list models
● GET /metrics: performance metrics (if enabled)
Final Notes
With Paiton and our Docker image, you can get state-of-the-art inference speed and efficiency with minimal setup. Just pull, run, and serve.
Keep in mind: amd/Llama-3.1-8B-Instruct-FP8-KV is provided only for a short evaluation period. For long-term deployments and access to other optimized models, please contact us.
For more details, benchmarks, or enterprise support, contact ElioVP.
1. Unless stated otherwise, AMD has not tested or verified the third-party claims found herein. GD-182a.


Related Blogs
-
The Importance of Open Ecosystems for Agentic AI Deployment
Enterprise agents need access to applications and data across the business. Open ecosystems help prevent AI vendor lock-in from standing in their way
July 30, 2026
-
Advancing AI 2026 Developer Sessions
See how Advancing AI 2026 brought together 2,000+ developers for workshops, technical sessions, and hands-on demos.
July 30, 2026
-
Closing the GPU Cluster Validation Gap: A Kubernetes-Native Approach with CVF — ROCm Blogs
Learn how to validate AMD GPU clusters end-to-end with CVF: hardware acceptance, mesh bandwidth, RDMA, and RCCL testing in one pipeline.
July 28, 2026
-
AMD GPU Operator v1.5.0: DRA Support, Automated GPU Node Recovery, and Expanded Kubernetes Infrastructure Control — ROCm Blogs
Discover how AMD GPU Operator v1.5.0 improves GPU scheduling, automates node recovery, and expands Kubernetes control.
July 27, 2026
-
For Creators Performance Is Creative Freedom
Artist Peter Neill uses AMD Ryzen processors, Ryzen AI-powered mobile performance, and Affinity by Canva to keep large-image editing fast, fluid, and creative.
July 27, 2026
-
Kimi-K3 on AMD Instinct GPUs
Day 0 support for Kimi-K3 on AMD Instinct MI355X GPUs with validated TP8 setups.
July 27, 2026
-
Attention Decode on AMD MI450 GPUs: A Gluon Kernel Optimization Guide — ROCm Blogs
Learn how to design a high-performance attention decode kernel on AMD MI450 GPUs using Gluon.
July 26, 2026
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026







