Unlocking Enterprise AI: Why are CPUs the Backbone!
May 30, 2025

Artificial Intelligence (AI) has long been part of IT industry research and deployment, but the rise of Generative AI has rapidly accelerated its integration into everyday life. The industry is now shifting focus from training large models to inference—deploying and running models efficiently at scale, from edge devices to data centers. As AI becomes increasingly commoditized, it holds the potential to significantly boost productivity and scale real-world applications like never before.
In today’s AI landscape, while GPUs often steal the spotlight, CPUs have been quietly powering AI inference for years. They excel in classical machine learning—supporting algorithms like linear regression, decision trees, and dynamic graph analysis—which are essential for real-world applications such as recommendation systems, fraud detection, and disease diagnosis.
As general-purpose computing engines, CPUs offer a powerful, cost-effective solution that seamlessly integrates with existing enterprise workloads. Beyond classical machine learning, CPUs are now vital for generative AI tasks, efficiently running small to medium language models and managing critical pre- and post-processing functions in AI pipelines.
With their broad deployment across enterprise applications, CPUs offer a natural and scalable path to AI integration. Their energy efficiency, affordability, and compatibility with existing infrastructure make them a compelling option for real-world AI deployments.
What’s Driving CPU-based AI Inference?
Three key advantages of driving CPU-based AI inference in the industry are:
- Broad Utilization – Server CPUs already exist in every data center as a highly flexible form of compute - handling general compute, and critical pre-and post- AI processing.
- Batch/Offline Processing – Efficient for high-volume workloads where response time is less critical.
- Cost & Energy Efficiency – Optimized for both capital and operational expenditure. Leveraging existing hardware for general purpose computing towards AI inference can result in cost savings.
AMD EPYC™ processors stand out in AI inference due to their distinctive combination of high performance, high memory bandwidth and exceptional scalability with high core count and broad spectrum of SKU options to address sectors of industry. The latest EPYC 9005 series feature up to 384 cores across dual sockets, enabling massive parallelism and balanced throughput for enterprise and AI workloads.
CPUs deliver exceptional value when AI workloads fall into the below set of characteristics:
- Workloads involve low-compute operations per inference
- Applications require large memory footprints for in-memory computation
- Models rely on coarse-grained experts or dynamic graph execution
- Work seamlessly alongside Enterprise workloads
These characteristics make AMD EPYC processors ideal for following categories of AI workloads for Inference.
Generative AI: Small & Medium Language Models
Small and medium-sized language models require comparatively lower compute resources than large language models and are ideally suited to run on AMD EPYC 9005 processors. With leadership core density and high memory bandwidth on x86, AMD EPYC processors deliver efficient performance for real-time inference while also supporting large-scale offline and batch workloads. The CPU’s ability to integrate directly into enterprise infrastructure without the need for additional accelerators makes it a highly cost-effective and scalable solution for AI deployments. This flexibility enables innovative deployment strategies such as running enterprise workloads during peak hours and scheduling AI inference during off-peak times, maximizing system utilization and optimizing data center efficiency.
Fig.i below demonstrates that the AMD EPYC 9965, dual core 192c per socket processor performs great for medium-sized models across various Generative AI use cases, such as Summarization and Translation, over 5th Gen 2P Intel® Xeon® 6980P , on open-source AI models like LLaMa3.1-8B1 and GPT-J-6B.2
Similar to its performance with medium-sized models, Fig. ii shows 2P AMD EPYC 9965 performs great across various generative AI use cases – Translation & Essay against 5th Gen 2P Intel® Xeon® 6980P on Small Language Models as well.3
To fully harness the AMD EPYC 9965 192 cores per socket (384 cores in total on a dual-socket system), multiple model instances can be deployed per socket. In this case we configured to utilize 32 cores per model instance and ran with a batch size of 32 on BF16 precision.


CPUs are an excellent choice for batch/offline inference across various industries, offering cost-effective solutions for SMBs and Edge deployments in sectors like Healthcare, Retail, and Manufacturing. For example: In Healthcare, CPUs can power AI-enhanced applications such as medical transcription, clinical decision support, and drug discovery by extracting insights from medical literature.
In Retail & E-commerce, CPU-only servers can support summarization and content generation for product descriptions and marketing copy.
Classical Machine Learning & Recommender systems
CPUs are designed for sequential processing, rule-based control, and branching logic, making them well suited for seamless integration with enterprise datasets and applications like ERP and CRM. This makes CPUs the go-to choice for many Classical Machine Learning and Recommendation Systems. The low-latency memory access and efficient cache hierarchy enable the effective handling of large embedding tables and sparse data.
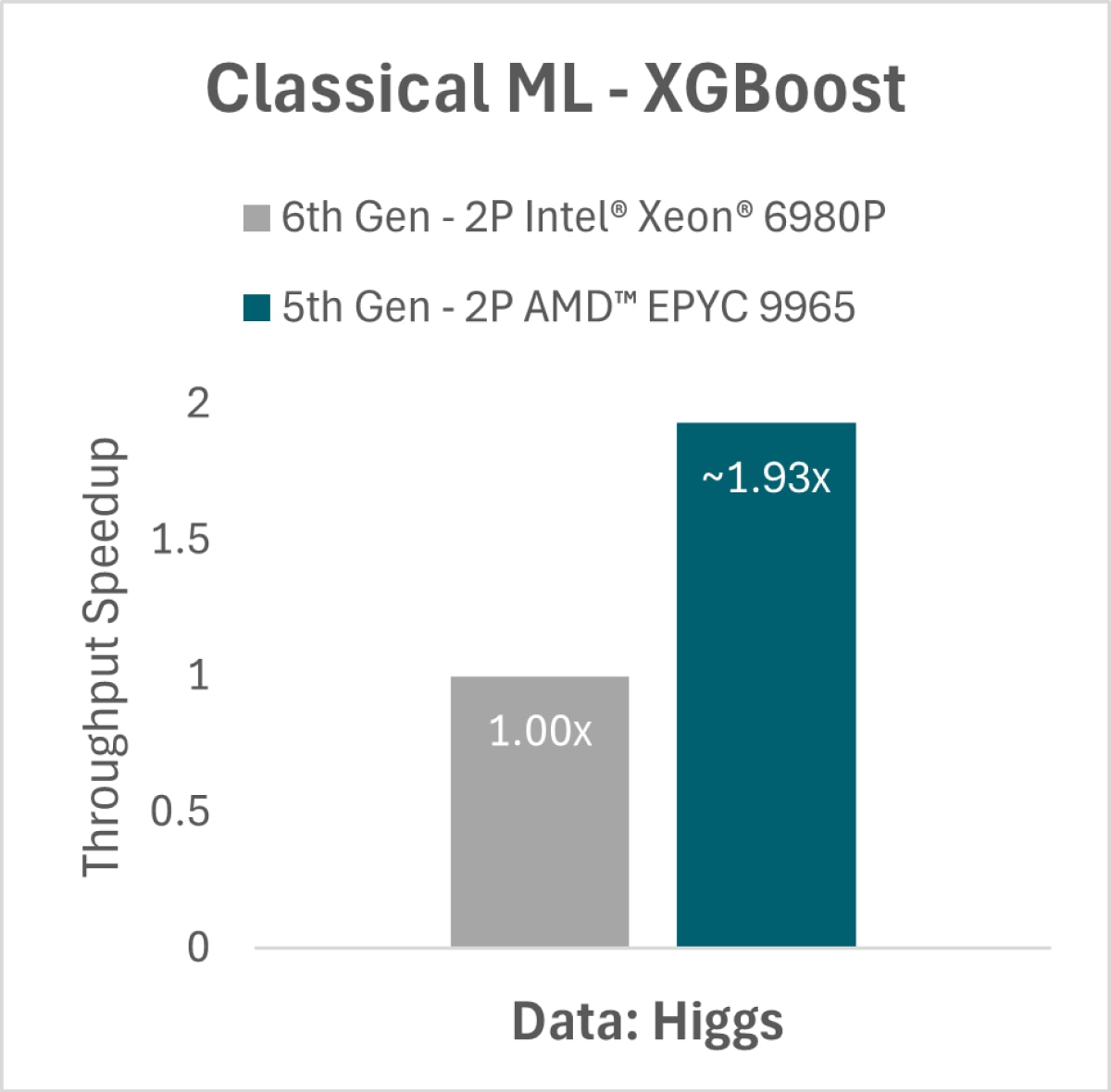
AMD EPYC processors stand out with algorithms like XGBoost (Extreme Gradient Boosting). Fig iii shows how the AMD EPYC 2P 9965 performs significantly better than Xeon® 2P when running multiple model instances per socket [32c/ model instance] to leverage its high core count. This setup optimizes processor utilization and maximizes memory bandwidth and capacity.4
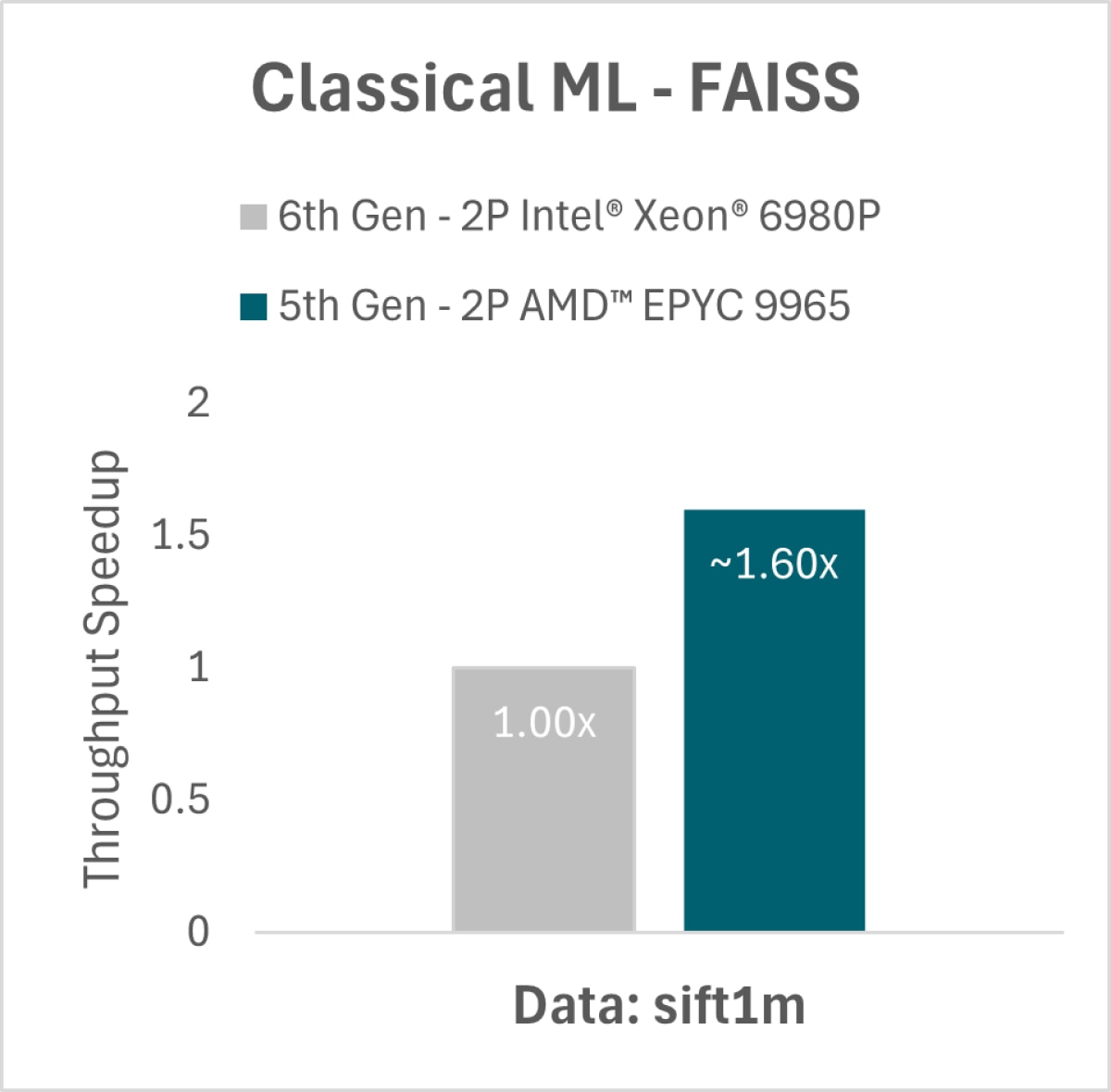
Facebook AI Similarity Seach (FAISS) is a popular library for similarity search algorithms, used for efficient retrieval of context from vector databases to feed into an LLM (as referred in the section on RAG below as one of the common use case scenarios). Fig iv shows how the AMD EPYC 2P 9965 outperforms the Intel® Xeon® 2P 6980P running multiple model instances per socket [32c/ model instance].5
CPUs are extensively deployed across many industries. In cybersecurity, it powers spam detection (Naïve Bayes), intrusion detection, and malware classification (decision trees). In manufacturing, CPUs drive predictive maintenance and demand forecasting using decision trees and regression models. CPUs are also pivotal in retail, e-commerce, and streaming services, where they support recommendation systems using collaborative filtering, ranking, and other machine learning techniques.
CPU for AI Inference Pre & Post Processing
CPUs are the cornerstone of AI inference, handling crucial data pre- and post-processing tasks. Most enterprise and cloud environments already have the necessary infrastructure, such as front-end web applications and systems (ERP, CRM, etc.), to seamlessly extend to AI inference. This enables efficient execution of small to medium-sized models, batch processing, or real-time inference, on existing data center systems. For compute-heavy models and large datasets, inference can be offloaded to GPUs.
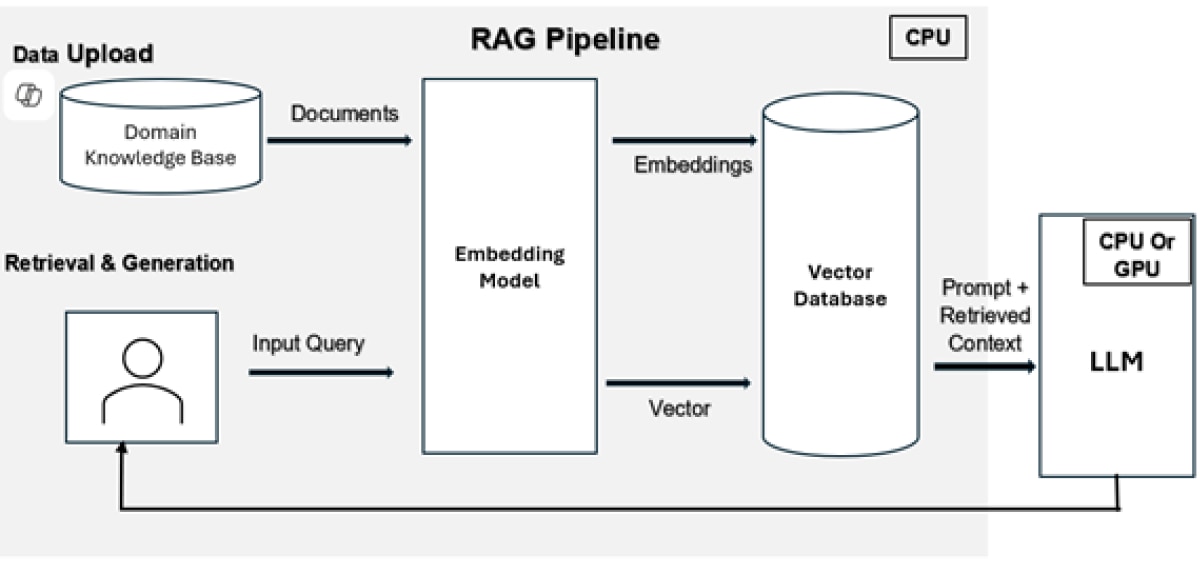
Retrieval Augmented Generation (RAG) pipeline is a commonly deployed AI solution pattern designed to improve LLM efficiency by integrating domain-specific intelligence. By accessing and incorporating external sources, RAG enables LLMs to generate highly accurate, up-to-date, and contextually relevant responses. Fig v shows RAG pipeline, encompassing data ingestion, retrieval, and generation, can be deployed entirely on CPUs including the embedding model, Vector Database upload & retrieval as well as LLM. Alternately hybrid approaches deploying LLMs on GPUs while keeping all the other components on CPUs.
Make Your AI Infrastructure Future-Ready
CPUs excel as AI accelerators, ideal for large datasets and complex models. AMD Instinct™ Accelerators deliver leading-edge Generative AI performance with support for all major AI frameworks. Meanwhile, CPUs remain the backbone of enterprise AI, offering a smart, cost-effective choice for inference on small to mid-sized models, particularly in batch processing scenarios.
High-performance AMD EPYC™ 9005-based servers offer significant energy efficiency and economy, while leveraging existing infrastructure and IT expertise. By upgrading to next-gen CPU systems with high core counts and memory capacity, enterprises can optimize AI performance and future-ready their infrastructure.
Unlock the full potential of your AI workloads with AMD EPYC CPUs—maximize efficiency, drive lower costs, and scale seamlessly. Get started today and power your business for tomorrow’s AI-driven future!
Footnotes:
1. 9xx5-156: Llama3.1-8B throughput results based on AMD internal testing as of 04/08/2025. Llama3.1-8B configurations: BF16, batch size 32, 32C Instances, Use Case Input/Output token configurations: [Summary = 1024/128, Chatbot = 128/128, Translate = 1024/1024, Essay = 128/1024]. 2P AMD EPYC 9965 (384 Total Cores), 1.5TB 24x64GB DDR5-6400, 1.0 Gbps NIC, 3.84 TB Samsung MZWLO3T8HCLS-00A07, Ubuntu® 22.04.5 LTS, Linux 6.9.0-060900-generic, BIOS RVOT1004A, (SMT=off, mitigations=on, Determinism=Power), NPS=1, ZenDNN 5.0.1 2P AMD EPYC 9755 (256 Total Cores), 1.5TB 24x64GB DDR5-6400, 1.0 Gbps NIC, 3.84 TB Samsung MZWLO3T8HCLS-00A07, Ubuntu® 22.04.4 LTS, Linux 6.8.0-52-generic, BIOS RVOT1004A, (SMT=off, mitigations=on, Determinism=Power), NPS=1, ZenDNN 5.0.1 2P Xeon 6980P (256 Total Cores), AMX On, 1.5TB 24x64GB DDR5-8800 MRDIMM, 1.0 Gbps Ethernet Controller X710 for 10GBASE-T, Micron_7450_MTFDKBG1T9TFR 2TB, Ubuntu 22.04.1 LTS Linux 6.8.0-52-generic, BIOS 1.0 (SMT=off, mitigations=on Performance Bias), IPEX 2.6.0 Results: CPU 6980P 9755 9965 Summary 1 n/a1.093 Translate 1 1.062 1.334 Essay 1 n/a 1.14 Results may vary due to factors including system configurations, software versions, and BIOS settings.
2. 9xx5-158: GPT-J-6B throughput results based on AMD internal testing as of 04/08/2025. GPT-J-6B configurations: BF16, batch size 32, 32C Instances, Use Case Input/Output token configurations: [Summary = 1024/128, Chatbot = 128/128, Translate = 1024/1024, Essay = 128/1024]. 2P AMD EPYC 9965 (384 Total Cores), 1.5TB 24x64GB DDR5-6400, 1.0 Gbps NIC, 3.84 TB Samsung MZWLO3T8HCLS-00A07, Ubuntu® 22.04.5 LTS, Linux 6.9.0-060900-generic, BIOS RVOT1004A, (SMT=off, mitigations=on, Determinism=Power), NPS=1, ZenDNN 5.0.1, Python 3.10.12 2P AMD EPYC 9755 (256 Total Cores), 1.5TB 24x64GB DDR5-6400, 1.0 Gbps NIC, 3.84 TB Samsung MZWLO3T8HCLS-00A07, Ubuntu® 22.04.4 LTS, Linux 6.8.0-52-generic, BIOS RVOT1004A, (SMT=off, mitigations=on, Determinism=Power), NPS=1, ZenDNN 5.0.1, Python 3.10.12 2P Xeon 6980P (256 Total Cores), AMX On, 1.5TB 24x64GB DDR5-8800 MRDIMM, 1.0 Gbps Ethernet Controller X710 for 10GBASE-T, Micron_7450_MTFDKBG1T9TFR 2TB, Ubuntu 22.04.1 LTS Linux 6.8.0-52-generic, BIOS 1.0 (SMT=off, mitigations=on, Performance Bias), IPEX 2.6.0, Python 3.12.3 Results: CPU 6980P 9755 9965 Summary 1 1.034 1.279 Chatbot 1 0.975 1.163 Translate 1 1.021 0.93 Essay 1 0.978 1.108 Caption 1 0.913 1.12 Overall 1 0.983 1.114 Results may vary due to factors including system configurations, software versions, and BIOS settings.
3. 9xx5-166: Llama3.2-1B throughput results based on AMD internal testing as of 04/08/2025. Llama3.3-1B configurations: BF16, batch size 32, 32C Instances, Use Case Input/Output token configurations: [Summary = 1024/128, Chatbot = 128/128, Translate = 1024/1024, Essay = 128/1024]. 2P AMD EPYC 9965 (384 Total Cores), 1.5TB 24x64GB DDR5-6400, 1.0 Gbps NIC, 3.84 TB Samsung MZWLO3T8HCLS-00A07, Ubuntu® 22.04.5 LTS, Linux 6.9.0-060900-generic, BIOS RVOT1004A, (SMT=off, mitigations=on, Determinism=Power), NPS=1, ZenDNN 5.0.1, Python 3.10.2 2P Xeon 6980P (256 Total Cores), AMX On, 1.5TB 24x64GB DDR5-8800 MRDIMM, 1.0 Gbps Ethernet Controller X710 for 10GBASE-T, Micron_7450_MTFDKBG1T9TFR 2TB, Ubuntu 22.04.1 LTS Linux 6.8.0-52-generic, BIOS 1.0 (SMT=off, mitigations=on, Performance Bias), IPEX 2.6.0, Python 3.12.3 Results: CPU 6980P 9965 Summary 1 1.213 Translation 1 1.364 Essay 1 1.271 Results may vary due to factors including system configurations, software versions, and BIOS settings.
4. 9xx5-162: XGBoost (Runs/Hour) throughput results based on AMD internal testing as of 04/08/2025. XGBoost Configurations: v1.7.2, Higgs Data Set, 32 Core Instances, FP32 2P AMD EPYC 9965 (384 Total Cores), 1.5TB 24x64GB DDR5-6400 (at 6000 MT/s), 1.0 Gbps NIC, 3.84 TB Samsung MZWLO3T8HCLS-00A07, Ubuntu® 22.04.5 LTS, Linux 5.15 kernel, BIOS RVOT1004A, (SMT=off, mitigations=on, Determinism=Power), NPS=1 2P AMD EPYC 9755 (256 Total Cores), 1.5TB 24x64GB DDR5-6400 (at 6000 MT/s), 1.0 Gbps NIC, 3.84 TB Samsung MZWLO3T8HCLS-00A07, Ubuntu® 22.04.4 LTS, Linux 5.15 kernel, BIOS RVOT1004A, (SMT=off, mitigations=on, Determinism=Power), NPS=1 2P Xeon 6980P (256 Total Cores), 1.5TB 24x64GB DDR5-8800 MRDIMM, 1.0 Gbps Ethernet Controller X710 for 10GBASE-T, Micron_7450_MTFDKBG1T9TFR 2TB, Ubuntu 22.04.1 LTS Linux 6.8.0-52-generic, BIOS 1.0 (SMT=off, mitigations=on, Performance Bias) Results: CPU Throughput Relative 2P 6980P 400 1 2P 9755 436 1.090 2P 9965 771 1.928 Results may vary due to factors including system configurations, software versions and BIOS settings.
5. 9xx5-164: FAISS (Runs/Hour) throughput results based on AMD internal testing as of 04/08/2025. FAISS Configurations: v1.8.0, sift1m Data Set, 32 Core Instances, FP32 2P AMD EPYC 9965 (384 Total Cores), 1.5TB 24x64GB DDR5-6400 (at 6000 MT/s), 1.0 Gbps NIC, 3.84 TB Samsung MZWLO3T8HCLS-00A07, Ubuntu® 22.04.5 LTS, Linux 5.15 kernel, BIOS RVOT1004A, (SMT=off, mitigations=on, Determinism=Power), NPS=1 2P AMD EPYC 9755 (256 Total Cores), 1.5TB 24x64GB DDR5-6400 (at 6000 MT/s), 1.0 Gbps NIC, 3.84 TB Samsung MZWLO3T8HCLS-00A07, Ubuntu® 22.04.4 LTS, Linux 5.15 kernel, BIOS RVOT1004A, (SMT=off, mitigations=on, Determinism=Power), NPS=1 2P Xeon 6980P (256 Total Cores), 1.5TB 24x64GB DDR5-8800 MRDIMM, 1.0 Gbps Ethernet Controller X710 for 10GBASE-T, Micron_7450_MTFDKBG1T9TFR 2TB, Ubuntu 22.04.1 LTS Linux 6.8.0-52-generic, BIOS 1.0 (SMT=off, mitigations=on, Performance Bias) Results: Throughput Relative 2P 6980P 36.63 1 2P 9755 46.86 1.279 2P 9965 58.6 1.600 Results may vary due to factors including system configurations, software versions and BIOS settings.

Contributors

Related Blogs
-
Kimi Code in MXFP4 on AMD GPUs
Discover how ATOM accelerates Kimi K2.5, K2.6, and K2.7-Code inference with optimized serving on AMD Instinct™ GPUs.
July 21, 2026
-
AMD Data Intelligence Platform: Open Modular Blueprint
See how AMD built OPTIMA, an open data intelligence platform that connects enterprise data for AI agents, analytics, and automation.
July 21, 2026
-
Rebuilding Agentic AI for AMD GPU
AMD and Moonshot AI built an agentic AI serving stack that optimizes KV cache, scheduling, and GPU performance on AMD Instinct™ GPUs
July 21, 2026
-
Efficient MiniMax-M3 Inference on AMD Instinct GPUs with ATOM and ATOMesh — ROCm Blogs
Serve and benchmark MiniMax-M3 on AMD Instinct MI355X GPUs using ATOM and ATOMesh with EAGLE3 speculative decoding.
July 20, 2026
-
Scaling MiniMax-M3 Inference with Distributed Serving and Operator Co-Design on AMD Instinct MI355X GPUs — ROCm Blogs
Optimize MiniMax-M3 inference on AMD Instinct™ MI355X GPUs with ATOM online quantization, AITER sparse attention, FP8 KV cache, and EAGLE3.
July 20, 2026
-
Train and Run Models on AMD GPUs with Unsloth
Train, fine-tune, run AI models with Unsloth on AMD GPUs across Windows, WSL and Linux, with native inference for leading models.
July 20, 2026
-
Ideogram Scales Open Image Model with AMD Instinct™ GPU-Powered Inference
Ideogram 4.0 Releases Best Open Image Model AMD Instinct GPUs Power Production-scale Inference End-to-End Enterprise Capabilities Built to Scale
July 20, 2026
-
Microsoft Azure Expanding AI Infra Choice with AMD Helios™
Microsoft and AMD expand Azure AI infrastructure with AMD Instinct MI455X and Helios, delivering more choice, scale, and efficiency.
July 20, 2026







