AMD Instinct™ GPUs Deliver Breakthrough Performance, Multi-node Scale and Ecosystem Validation in MLPerf® Training 6.0
Jun 16, 2026

Why the AMD MLPerf Training 6.0 Submission Matters
Training platforms are tested in two places: the benchmark run and the deployment that follows. MLPerf™ Training 6.0 gave AMD a way to show progress in both. In this submission, AMD delivered its most comprehensive MLPerf training entry to date, expanding beyond single-node benchmark results into multi-node training while showing continued progress on the core generative AI workloads customers care about most.
Three technical milestones help explain what changed in this round:
- The debut of a production-ready MXFP4 (FP4) training recipe across both LLM benchmarks.
- The first-ever use of AMD Primus in an AMD MLPerf Training submission.
- The first multi-node submissions from AMD, marking a critical step toward large-scale training, the natural operating mode for production AI workloads.
That breadth matters because AI training infrastructure is no longer judged on one result or one system configuration. Training teams need platforms that shorten time-to-train, keep scaling when work moves beyond one server and behave predictably outside a reference lab.
Just as important, this submission shows AMD moving from benchmark performance toward broader platform readiness. AMD Instinct™ GPUs, AMD ROCm™ software, AMD Primus and a growing ecosystem of cloud and systems partners all helped show a platform that can move from benchmark results toward repeatable customer deployment.
AMD Instinct™ MI350 Series GPUs: Built for Modern AI Training
AMD Instinct™ MI350 Series GPUs provide the hardware foundation for the latest MLPerf Training 6.0 results from AMD. Built on AMD CDNA™ 4 architecture, the AMD Instinct MI350X and MI355X GPUs combine a 3nm process node, 185 billion transistors and 288GB of HBM3E memory capacity to help address the growing demands of large-model training.
Image Zoom

Image Zoom

The platform is designed for the performance, memory capacity and deployment flexibility required by modern AI infrastructure. With up to 10 PF of MXFP4 performance, support for AI models up to 520 billion parameters on a single GPU, and compatibility with the industry-standard UBB8 node in both air-cooled and direct liquid-cooled configurations, AMD Instinct MI350 Series GPUs are built to support high-performance training across a range of data center environments.
Those capabilities matter because training performance depends on more than peak compute. Customers need enough memory for larger models, efficient low-precision execution, optimized software support and platforms that can move from benchmark validation into real deployment environments. The MLPerf™ Training 6.0 results that follow show how AMD translated that platform foundation into measurable gains across key generative AI training workloads.
Defining Moments from the AMD MLPerf Training 6.0 Submission
The submission tells the training story across three proof points: faster results across benchmark rounds, competitive performance on core LLM workloads, and the first MLPerf Training multi-node submission from AMD. Together, they show AMD moving from faster single-node results toward larger, more repeatable training deployments. The Llama 2-70B and Llama 3.1-8B results below are MLPerf Training Closed submissions, providing a consistent basis for comparing performance across systems. This section moves from round-to-round AMD performance gains and competitive positioning versus NVIDIA B200 to the first AMD MLPerf Training multi-node submission with FLUX.1.
1. AMD Instinct™ MI355X GPUs Deliver a 3.5X Generational Leap on Llama 2-70B
One of the clearest proof points in this round is progress on Llama 2-70B fine-tuning. In just over one year, AMD improved performance by 3.5X from its first AMD Instinct MI300X GPU submission using MXFP8 in MLPerf Training 5.0 to the AMD Instinct MI355X GPU submission using MXFP4 in MLPerf Training 6.0.

That gain reflects full-stack advancement rather than a single change. Hardware upgrades from AMD Instinct MI300X to MI355X, AMD ROCm™ software optimization across benchmark rounds and MXFP4 datatype support all contributed to faster time-to-train on a key large language model fine-tuning workload.
Image Zoom

Image Zoom

The momentum continued inside the AMD Instinct MI350 Series as well. Across the last seven months, AMD delivered double-digit uplift across both MI355X and MI350X platforms:
- Llama 2-70B fine-tuning: MI355X improved by 19%, while MI350X improved by 16%.
- Llama 3.1-8B pre-training: MI355X improved by 13%, while MI350X improved by 11%.
For customers, continued tuning can shorten training runs, improve GPU utilization and make it easier to move from early experiments to optimized workloads.
2. AMD Instinct™ MI355X GPUs Show Competitive Performance on Core LLM Training Workloads
AMD Instinct MI355X GPUs also demonstrated competitive performance against NVIDIA B200 platforms on two important MLPerf Training 6.0 workloads: Llama 2-70B fine-tuning and Llama 3.1-8B pre-training.

The AMD Instinct MI355X platform using MXFP4 delivered competitive performance versus the NVIDIA B200 platform using NVFP4, coming within 5% on Llama 2-70B fine-tuning and within 6% on Llama 3.1-8B pre-training.
The breadth of the comparison is important. Fine-tuning reflects how teams adapt a large model for a specific task, domain or application. Pre-training puts more pressure on sustained compute, data movement and long-running utilization. Showing strength across both workloads gives customers a more balanced view of AMD Instinct GPU-based infrastructure for the training lifecycle.
For organizations evaluating large-scale AI training platforms, these results reinforce that AMD Instinct GPUs are not limited to one benchmark scenario. They are designed to compete on the core LLM workflows that matter for modern generative AI development.
3. Multi-Node FLUX.1 Training Extends AMD into Scale-Out MLPerf Training
A major step for AMD in MLPerf Training 6.0 is the first submission that includes multi-node training. This expands AMD training from single-node benchmark performance into the scale-out environments required for larger models, higher-resolution workloads and production AI development.

For this round, AMD added FLUX.1 as a first-time MLPerf Training workload and scaled it across AMD Instinct GPU platforms. AMD submitted FLUX.1 at 64 Instinct MI325X GPUs, while Oracle Cloud Infrastructure, in collaboration with AMD, submitted FLUX.1 at 512 GPUs. The 512-GPU result represents a 64-node cluster with eight GPUs per node, demonstrating production-scale training across AMD Instinct infrastructure.
That scale point matters because training cannot remain bound by a single server as models and datasets grow. Customers need systems that can coordinate work across many nodes while maintaining predictable performance, efficient communication and reliable orchestration.
The 512-GPU OCI result is also a strong infrastructure proof point. With the 512-GPU OCI result, AMD matched NVIDIA’s largest scale with a 512-GPU Training submission. Together, the AMD and OCI submissions show FLUX.1 running across AMD Instinct MI300X and MI325X platforms, reinforcing broader scale-out readiness across the AMD Instinct portfolio.
Ecosystem Scale and Reproducibility Across Partner Submissions
Another major milestone for the AMD MLPerf Training 6.0 submission was ecosystem validation. This round included a record 10 ecosystem partners submitting MLPerf Training results on AMD Instinct GPU-based platforms, showing that AMD training performance is not dependent on one internal reference configuration.
Confirmed partner participants included Oracle Cloud Infrastructure, Dell, HPE, Cisco, Supermicro, MiTAC, MiTAC + Akash, KRAI, Vultr, and GigaComputing. Across the partner submissions, results landed within 6% of official AMD submissions across both major LLM training workloads: Llama 2-70B LoRA fine-tuning and Llama 3.1-8B pre-training.

When partner submissions closely track AMD submissions, it gives customers more confidence that the results can be repeated across the ecosystem and not only in a single benchmark lab. The partner results also point back to AMD ROCm software maturity. Consistent partner results are difficult without predictable kernels, tuned libraries and a software path partners can reproduce.
How AMD ROCm™ Software Helps Drive Training Performance and Scale
AMD ROCm™ software is the software foundation connecting the results across the MLPerf Training 6.0 submission. It helps translate AMD Instinct GPU capability into optimized training throughput, scale-out efficiency and reproducible performance across AMD and partner systems.
Training workloads rely on more than raw GPU throughput. Large-model training requires efficient kernels, strong compiler support, high-bandwidth memory utilization, communication efficiency across GPUs and nodes, and readiness for the frameworks and models customers already use.

In this submission, AMD ROCm™ software helped support several practical training requirements:
- Optimized training throughput through high-efficiency precision support and model convergence work.
- Kernel and compiler optimization through tuned GEMM, attention and compiler stacks for higher throughput.
- Memory and communication efficiency through better bandwidth utilization and improved compute and communication overlap.
- Day-0 model support for leading training frameworks and models on AMD Instinct GPU-based systems.
These optimizations show up across the MLPerf Training 6.0 results. AMD ROCm software tuning contributed to the double-digit uplift on AMD Instinct MI350 Series platforms, supported competitive AMD Instinct MI355X results versus NVIDIA B200, and helped partners reproduce results within 6% of AMD submissions.
AMD Primus Converts Benchmark Workflows into a Customer-Ready Training Path
MLPerf Training 6.0 also marks the first AMD MLPerf Training submission using AMD Primus, a lightweight, unified training framework for large models on AMD Instinct GPUs. Primus turns optimized benchmark workflows into more repeatable paths for customers.
Primus was used across both Llama 2-70B and Llama 3.1-8B workloads. It brings together a single CLI, YAML configuration templates, preflight validation and rank-structured debug logs to help teams configure, validate, launch and debug large training runs.
Image Zoom
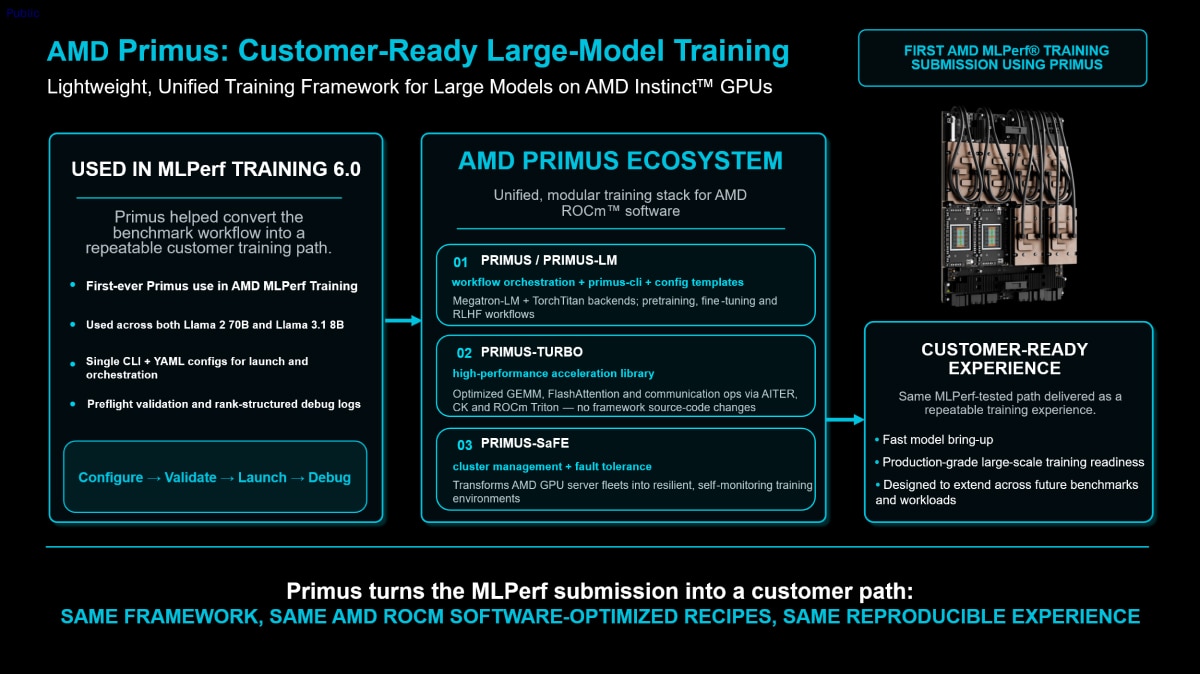
The broader Primus ecosystem adds three layers to the customer path:
- Primus and Primus-LM provide workflow orchestration, primus-cli, configuration templates and support for Megatron-LM and TorchTitan backends across pre-training, fine-tuning and RLHF workflows.
- Primus-Turbo provides optimized GEMM, FlashAttention and communication operations through AITER, CK and AMD ROCm Triton without requiring framework source-code changes.
- Primus-SaFE adds cluster management and fault tolerance to help transform AMD GPU server fleets into resilient, self-monitoring training environments.
On top of strong benchmark results, AMD is also showing repeatability. This framework path helps customers bring up models faster, use AMD ROCm software-optimized recipes, and prepare for production-grade large-scale training.
Annual Cadence Builds Toward the Next Era of AMD Instinct Training Infrastructure
The broader context behind these results is the annual cadence for AMD Instinct GPUs. That cadence matters because AI training requirements are moving quickly, from LLM fine-tuning and pre-training to multimodal workloads, larger scale-out clusters and AI factory deployments.

AMD Instinct MI300X GPUs established a foundation for generative AI leadership in 2023. AMD Instinct MI325X GPUs extended that foundation in 2024 with HBM3E memory and increased compute capability. In 2025, AMD Instinct MI350 Series GPUs advanced the platform again with AMD CDNA 4 architecture, stronger compute capability, expanded memory capacity and lower-precision training paths such as MXFP4.
Looking ahead, the AMD Instinct MI400 Series is positioned as the next step in the roadmap, built on AMD CDNA 5 architecture and designed as an AI factory infrastructure building block. It also helps set the foundation for the AMD Helios Rackscale Solution, extending the roadmap from GPU platform innovation toward rack-scale AI infrastructure. The broad direction is clear: AMD is advancing training infrastructure through GPU architecture, memory capacity, AMD ROCm software maturity, ecosystem reproducibility and system-level scale.
Final Takeaway
The AMD MLPerf Training 6.0 submission marks a major step forward for AMD AI training. AMD delivered a 3.5X generational gain on Llama 2-70B, competitive AMD Instinct MI355X results versus NVIDIA B200 on two core LLM training workloads, the first MLPerf Training submission with multi-node scale from AMD and a record level of partner participation.
The results also show a broader platform coming together. AMD Instinct GPUs provide the hardware foundation. AMD ROCm software helps unlock performance, scale and reproducibility. AMD Primus helps turn benchmark workflows into customer-ready training paths. A growing partner ecosystem helps validate that performance across real deployment choices.
For readers interested in the deeper technical story behind these results, two new AMD ROCm™ blogs provide additional detail on the MLPerf™ Training 6.0 submission. “AMD Instinct™ GPUs MLPerf Training v6.0 Submission” explores the hardware, software and optimization work behind the submission, while “Reproducing the AMD MLPerf Training v6.0 submission result” walks through how to reproduce the benchmarks on AMD Instinct™ hardware. Together, the blogs give readers a closer look at the ROCm software-optimized training path behind the results and reinforce our commitment to openness, transparency and reproducibility in AI training.
Footnotes
- For additional information about MLPerf Training 6.0 results, visit: https://mlcommons.org/benchmarks/training/ .
- MI350-021 - Calculations by AMD Performance Labs in May 2025, based on the published memory capacity specifications of AMD Instinct™ MI350X / MI355X OAM 8xGPU platform vs. an NVIDIA Blackwell B200 8xGPU platform. Server manufacturers may vary configurations, yielding different results. MI350-021.
- MI350-012 - Based on calculations by AMD as of April 17, 2025, using the published memory specifications of the AMD Instinct MI350X / MI355X GPUs (288GB) vs MI300X (192GB) vs MI325X (256GB). Calculations performed with FP16 precision datatype at (2) bytes per parameter, to determine the minimum number of GPUs (based on memory size) required to run the following LLMs: OPT (130B parameters), GPT-3 (175B parameters), BLOOM (176B parameters), Gopher (280B parameters), PaLM 1 (340B parameters), Generic LM (420B, 500B, 520B, 1.047T parameters), Megatron-LM (530B parameters), LLaMA (405B parameters) and Samba (1T parameters). Results based on GPU memory size versus memory required by the model at defined parameters, plus 10% overhead. Server manufacturers may vary configurations, yielding different results. Results may vary based on GPU memory configuration, LLM size, and potential variance in GPU memory access or the server operating environment. All data based on FP16 datatype. For FP8 = X2. For FP4 = X4. MI350-012.
- The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.
GENERAL DISCLAIMER
The information contained herein is for informational purposes only and is subject to change without notice. While every precaution has been taken in the preparation of this document, it may contain technical inaccuracies, omissions and typographical errors, and AMD is under no obligation to update or otherwise correct this information. Advanced Micro Devices, Inc. makes no representations or warranties with respect to the accuracy or completeness of the contents of this document, and assumes no liability of any kind, including the implied warranties of noninfringement, merchantability or fitness for particular purposes, with respect to the operation or use of AMD hardware, software or other products described herein. No license, including implied or arising by estoppel, to any intellectual property rights is granted by this document. Terms and limitations applicable to the purchase or use of AMD products are as set forth in a signed agreement between the parties or in AMD's Standard Terms and Conditions of Sale. GD-18u.
© 2026 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, AMD Instinct, and combinations thereof are trademarks of Advanced Micro Devices, Inc. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners. Certain AMD technologies may require third-party enablement or activation. Supported features may vary by operating system. Please confirm with the system manufacturer for specific features. No technology or product can be completely secure.
Footnotes
- For additional information about MLPerf Training 6.0 results, visit: https://mlcommons.org/benchmarks/training/ .
- MI350-021 - Calculations by AMD Performance Labs in May 2025, based on the published memory capacity specifications of AMD Instinct™ MI350X / MI355X OAM 8xGPU platform vs. an NVIDIA Blackwell B200 8xGPU platform. Server manufacturers may vary configurations, yielding different results. MI350-021.
- MI350-012 - Based on calculations by AMD as of April 17, 2025, using the published memory specifications of the AMD Instinct MI350X / MI355X GPUs (288GB) vs MI300X (192GB) vs MI325X (256GB). Calculations performed with FP16 precision datatype at (2) bytes per parameter, to determine the minimum number of GPUs (based on memory size) required to run the following LLMs: OPT (130B parameters), GPT-3 (175B parameters), BLOOM (176B parameters), Gopher (280B parameters), PaLM 1 (340B parameters), Generic LM (420B, 500B, 520B, 1.047T parameters), Megatron-LM (530B parameters), LLaMA (405B parameters) and Samba (1T parameters). Results based on GPU memory size versus memory required by the model at defined parameters, plus 10% overhead. Server manufacturers may vary configurations, yielding different results. Results may vary based on GPU memory configuration, LLM size, and potential variance in GPU memory access or the server operating environment. All data based on FP16 datatype. For FP8 = X2. For FP4 = X4. MI350-012.
- The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.
GENERAL DISCLAIMER
The information contained herein is for informational purposes only and is subject to change without notice. While every precaution has been taken in the preparation of this document, it may contain technical inaccuracies, omissions and typographical errors, and AMD is under no obligation to update or otherwise correct this information. Advanced Micro Devices, Inc. makes no representations or warranties with respect to the accuracy or completeness of the contents of this document, and assumes no liability of any kind, including the implied warranties of noninfringement, merchantability or fitness for particular purposes, with respect to the operation or use of AMD hardware, software or other products described herein. No license, including implied or arising by estoppel, to any intellectual property rights is granted by this document. Terms and limitations applicable to the purchase or use of AMD products are as set forth in a signed agreement between the parties or in AMD's Standard Terms and Conditions of Sale. GD-18u.
© 2026 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, AMD Instinct, and combinations thereof are trademarks of Advanced Micro Devices, Inc. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners. Certain AMD technologies may require third-party enablement or activation. Supported features may vary by operating system. Please confirm with the system manufacturer for specific features. No technology or product can be completely secure.

Contributors

Related Blogs
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026
-
Introducing Instella-MoE: A State-of-the-Art Fully Open Mixture-of-Experts Language Model — ROCm Blogs
Explore Instella-MoE-16B-A3B, AMD’s fully open 16B MoE LLM with 2.8B active params per token, trained on AMD Instinct™ MI300 & MI325 GPUs.
July 23, 2026
-
Enabling Language-specific Reasoning in Multilingual Models with Reinforcement Learning — ROCm Blogs
Learn how to train multilingual reasoning models with reinforcement learning and extend context windows on AMD Instinct GPUs.
July 23, 2026
-
Agentic AI Workflows Simplified
Rocm.AI simplifies how developers build and serve with ROCm on AMD GPU’s
July 23, 2026
-
AMD Launches Helios™: The Highest Performing Rackscale AI Infrastructure Solution
AMD launches Helios, an open rack-scale AI platform connecting 72 AMD Instinct™ MI455X GPUs for frontier AI inference and training
July 23, 2026
-
Agentic AI: AMD EPYC™ 9005 CPUs Wins Today, EPYC 9006, formerly code-named “Venice”, Takes It to a New Level
AMD EPYC 9006 Series Server CPUs deliver up to 256 cores, faster memory and I/O, and a strong foundation for enterprise AI workloads, helping advance your data center for the agentic era.
July 23, 2026
-
AI Networking Built for Scale
AMD AI networking unifies front-end, scale-up, and scale-out infrastructure to accelerate training, inference, and agentic AI.
July 23, 2026
-
AMD Helios™: Resilient Scale-Up Networking for AI
Discover how AMD Helios™ delivers resilient scale-up networking for production AI with UALoE, AFM, AFOS, and vPods.
July 23, 2026







