Empowering Local Industrial Compute: AMD and XMPro Deliver Autonomous Intelligence at the Edge using AMD Ryzen AI Software
Jul 15, 2025

AMD and XMPro have partnered to deliver next-generation Al capabilities to the industrial edge. This collaboration combines the cutting-edge hardware from AMD with an intelligent business operations suite from XMPro. They leverage the AMD open-source Lemonade Server to support local, private, and efficient AI workloads at the edge for industrial enterprises.
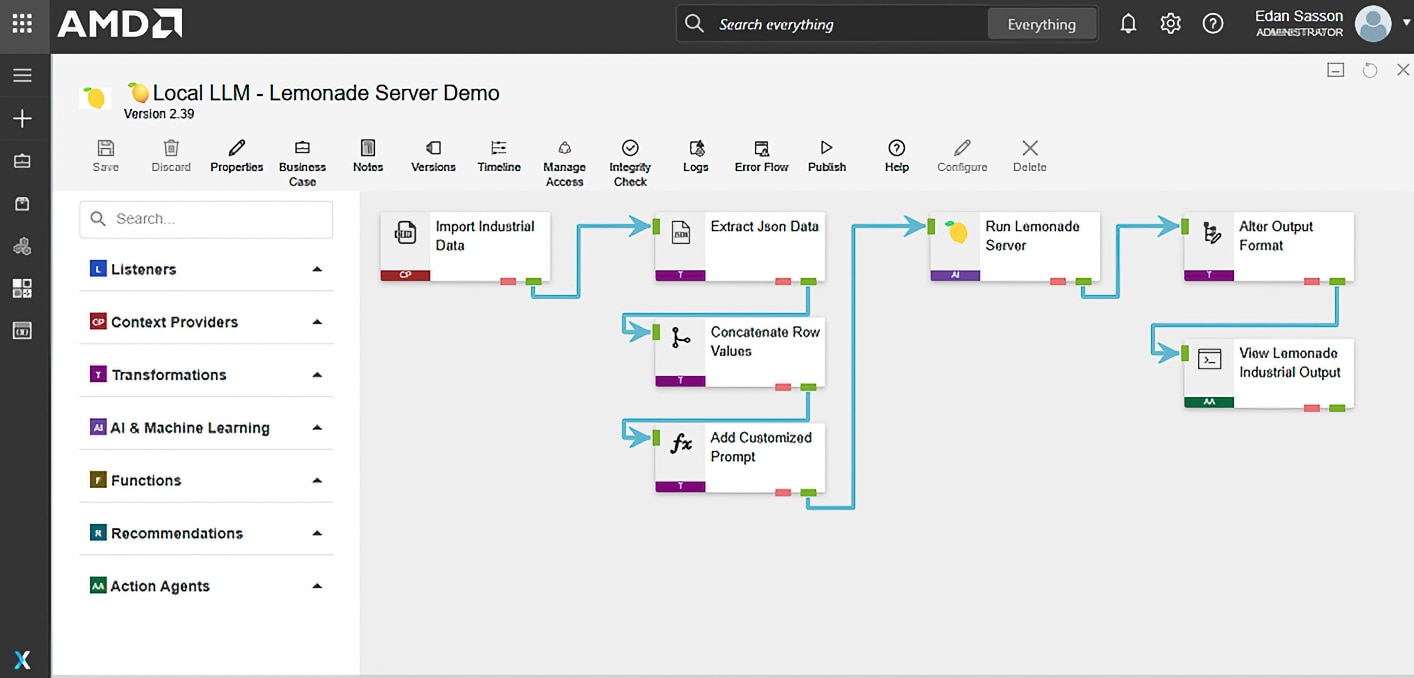
Figure 1. Demonstrating an example of how to use the newly integrated "Lemonade Server" component in XMPro. In this example, we analyze data from a pump and feed it into a local LLM running on Ryzen™ AI.
Empowering Industrial AI at the Edge: AMD and XMPro Combine Efforts
Industrial operations generate enormous volumes of sensor and system data every minute, yet most manufacturers still struggle to turn that data into real-time decisions. Organizations prioritizing cost efficiency may find that while cloud AI provides flexibility, edge solutions may offer more controlled spending with the added benefits of reduced latency and increased security for mission-critical environments. For example, a typical automotive plant processing 50,000 sensor readings per minute can cost over $15,000 per month in cloud AI API costs[1].
To solve this, AMD and XMPro are working together to bring advanced AI inferencing directly to the industrial edge. This collaboration integrates the AMD open-source Lemonade Server, built to run local large language models (LLM) on AMD Ryzen AI processors, with the composable industrial intelligence platform from XMPro. The result is that industrial enterprises can now deploy AI-powered decision support, automation, and predictive insights securely and efficiently on-site without sending sensitive data to the cloud.
Why This Collaboration Matters
Industrial leaders face a fundamental question: How can you harness AI's power while maintaining control over your data and costs? The answer lies in operationalizing local AI inference at the industrial edge.
AI has shown a direct impact in several key industrial areas such as predictive maintenance, quality control, supply chain optimization, and real-time suggestions. While AI and cloud services have revolutionized data analysis, the next leap forward for cost and data security comes from edge inferencing: running AI models directly at the source of data such as machines, sensors, and gateways.
AMD and XMPro are making this practical by enabling smaller, efficient AI models to run locally on AI-enabled devices, such as AMD Ryzen AI processor-based systems, leveraging both the neural processing unit (NPU) and integrated graphical processing unit (iGPU).
This approach has these three critical advantages:
Lower Total Cost of Ownership: Cloud systems incur recurring fees on a per-token basis. On-premises setups require substantial upfront investment in GPU clusters and ongoing maintenance costs. In contrast, the edge systems powered by AMD offer lower total cost of ownership (TCO), with one-time hardware investments at a fraction of the cost.
Complete Data Sovereignty: All inferencing and analytics are performed locally, enabling secure industrial sites to harness the power of large language model (LLM) inferencing. This approach ensures that sensitive data remains on-site and never leaves the facility.
Performance at the Edge: Deploy LLMs and other AI tools directly on-site, leveraging hybrid hardware acceleration that uses both the NPU and iGPU.
Figure 2 below illustrates the benefits of using this AMD Ryzen AI approach, featuring speedups in both time to first token (TTFT) and token generation per second (Tokens/s).
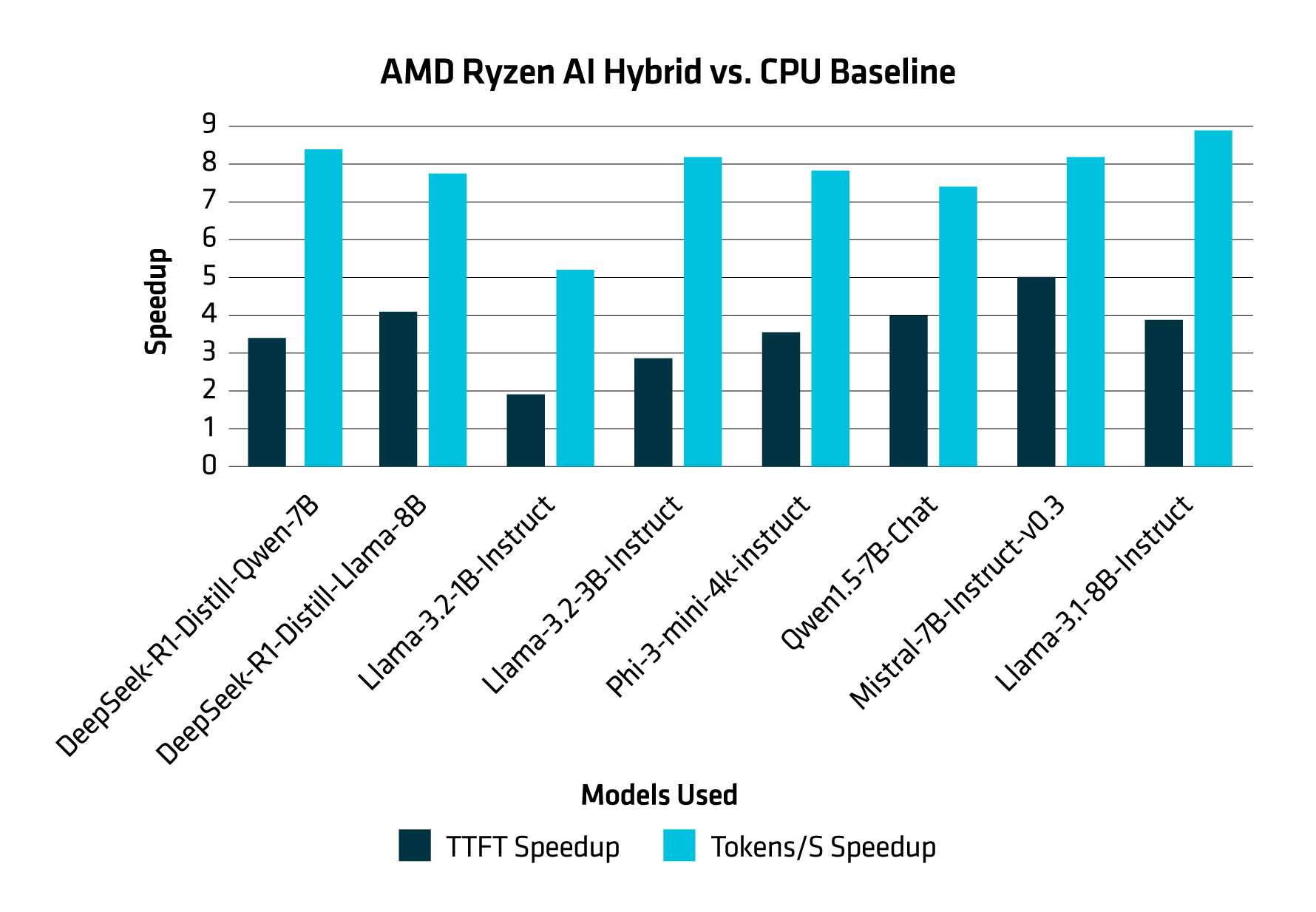
Figure 2. A graph showcasing the speed multiplier of AMD Ryzen AI iGPU + NPU approach vs. a CPU Baseline (HF bfloat16) for TTFT speedup and tokens/s speedup on an HP OmniBook Ultra Laptop 14z. The CPU baseline represents the “Speed Multiplier” 1 in the graph above. [2]
What the Numbers Mean for Industrial AI
This performance benchmark illustrates how hybrid AI acceleration with AMD Ryzen™ AI processors significantly improve the speed and efficiency of running local LLMs.
Compared to a CPU-only setup, the Ryzen AI configuration achieves up to 8–9 times faster token generation and a 3–4 times faster initial response time across several industry-relevant models. This translates into:
- Faster AI decision-making on the factory floor
- Real-time responsiveness for AI-powered operational guidance
- Reduced hardware load and energy use during AI inferencing
- Improved user experience for engineers and operators using AI assistants
Deploying AI at the Industrial Edge
The collaboration between AMD and XMPro focuses on making edge AI practical and accessible for industrial teams. Rather than requiring extensive AI expertise, the integrated solution allows engineers and operators to deploy AI capabilities using familiar tools and workflows.
The benefits include:
- Scalable AI Deployment
Manufacturers can run lightweight or complex models across a range of AMD-powered devices, from rugged edge nodes to operator workstations, without having to redesign their architecture. - Energy-efficient Processing
The hybrid NPU and iGPU architecture in the AMD Ryzen AI processor supports high-performance AI workloads while reducing power consumption, an important factor for maintaining continuous industrial operations. - Secure, Localized Intelligence
All data and AI decision-making remain on-site, helping organizations meet compliance requirements and protect sensitive operational insights from external exposure. - Integration with Existing Systems
The XMPro platform connects with existing industrial systems such as:- Enterprise resource planning (ERP): Business management software for inventory, production, etc.
- Supervisory control and data acquisition (SCADA): Real-time monitoring and control systems for industrial equipment.
- Internet of things (IoT): Network of connected sensors and devices that send/receive industrial data.
This collaboration helps industrial teams move beyond early AI experimentation. It provides a composable, scalable infrastructure that supports evolving operational needs without dependence on cloud ecosystems or rigid, single-purpose solutions.
Who is XMPro?
XMPro is an industrial intelligence platform that enables asset-intensive organizations to transform real-time data into decisions and actions. Its composable architecture allows engineering, operations, and IT teams to rapidly build and scale AI-powered solutions tailored to their environment without custom coding or disrupting existing systems. Designed for manufacturing, energy, mining, utilities, and logistics, XMPro supports a wide range of use cases, including condition monitoring, predictive maintenance, process optimization, and decision automation.
Key capabilities include:
- Digital Twins
Create real-time models of assets, processes, and systems to monitor performance, simulate scenarios, and identify opportunities for improvement. - Data Stream Composition
Unify data within enterprises for monitoring and analytics by connecting systems such as ERP, SCADA, and IoT. - AI Insights and Automation
Deploy embedded AI models that detect anomalies, predict failures, and trigger automated or guided actions based on live data. This uses LLM-powered assistants for context-aware support - Composable, Reusable, and Secure Architecture
Design and deploy solutions using drag-and-drop tools that support rapid configuration, reuse across sites, and easy adaptation to changing business needs. This directly integrates with enterprise IT environments, adheres to cybersecurity controls, and supports governance across all AI-enabled decision logic.
How does Lemonade Server Play into This?
Lemonade Server is designed for easy integration and rapid deployment of local LLMs, something that is very valuable in industrial environments. It is optimized to run efficiently on AMD Ryzen AI hardware, using both the NPU and iGPU for fast, power-efficient inferencing.
In industrial environments where low latency, data sovereignty, and reliability are essential, Lemonade Server provides a secure and scalable foundation for bringing advanced AI capabilities to the edge. Within XMPro, it enables local deployment of LLMs that support intelligent automation and real-time operational decision-making.
This integration allows LLMs to:
- Interpret and respond to complex industrial data with millisecond-level latency
- Operate entirely on-premise, keeping sensitive data within secure facilities
- Generate contextual recommendations, instructions, or alerts without requiring cloud access
- Support human-in-the-loop and autonomous workflows across critical processes
Its key features include:
- OpenAI API Compatibility
Lemonade Server is built using the industry standard API from OpenAI for easy integration with new and existing applications for local inferencing. - Hybrid iGPU + NPU
Lemonade Server distributes AI workloads across the iGPU and NPU on AMD Ryzen AI processors. This delivers fast, power-efficient inferencing using Ryzen AI software. - Secure, Private, and Local
All data and AI processing remain on-device, ensuring privacy and security, with no cloud interactions required. - Open-Source
Lemonade Server is fully open source, allowing for rapid innovation and custom features.
By combining Lemonade Server with XMPro’s platform, enterprises gain the ability to run real-time, context-aware AI agents directly at the edge, enabling intelligent automation, faster response to events, and greater operational resilience.
Looking Ahead
This collaboration between AMD and XMPro creates a practical foundation for industrial AI that prioritizes security, cost-effectiveness, and real-world applicability. This architecture supports the safe deployment of AI in environments where uptime, data control, and decision accountability are non-negotiable.
AMD and XMPro plan to expand model compatibility and performance while supporting additional industrial AI use cases. Future developments will build upon this foundation, introducing more advanced capabilities.
For organizations exploring edge AI, this collaboration offers a practical and extensible path to move from experimentation to real-world outcomes.
Getting Started
Ready to bring practical, reliable, and cost-effective AI to your edge operations? Contact the AMD team at lemonade@amd.com to discuss your deployment needs.
Check out XMPro to see how you can leverage Lemonade integration in XMPro using Ryzen AI software.
More Resources
To learn more and contribute to Lemonade, check out our Lemonade GitHub page or install it here from the Lemonade Server Website.
We are continuously updating and improving Lemonade, and we’d love your input. If you have feedback, fixes, or questions, create an issue on the Lemonade repository and assign eddierichter-amd or edansasson, or email us at lemonade@amd.com


Related Blogs
-
For Creators Performance Is Creative Freedom
Artist Peter Neill uses AMD Ryzen processors, Ryzen AI-powered mobile performance, and Affinity by Canva to keep large-image editing fast, fluid, and creative.
July 27, 2026
-
AMD Ryzen™ AI Embedded X100 Series: Consolidating Compute, Graphics and AI at the Edge
Explore AMD Ryzen™ AI Embedded X100 Series processors for edge AI, imaging, signal processing, graphics and workload consolidation.
July 23, 2026
-
From Benchmarks to Behavior: Rethinking Performance in Autonomous Robotics
See how AMD Ryzen™ AI Embedded X100 processors help autonomous robotics sustain AI, control and sensor workloads in real time.
July 23, 2026
-
Understanding Attention Algorithms and Their Backends for Image and Video Generation — ROCm Blogs
Practical guide to attention backends in ComfyUI on AMD describing how to optimize performance, memory, and stability with the right configuration.
July 19, 2026
-
How Pixar and AMD Scale Rendering for Artists
See how Pixar, Ranch Computing, and AMD brought production-grade RenderMan workflows, mentorship, and cloud rendering to creators worldwide.
July 17, 2026
-
Efficient Hyperparameter Optimization for Autonomous Driving Models with AMD Instinct GPU Partitioning — ROCm Blogs
Accelerate HPO for autonomous driving models using AMD MI300X GPU partitioning for higher throughput, efficiency, and parallelism.
July 07, 2026
-
AMD Ryzen™ AI Halo Now Available at Micro Center
Ryzen AI Halo launches at Micro Center, powering agentic PCs for developers building larger, next-generation local AI applications.
July 06, 2026
-
AMD Named Current Company to Beat in Gartner® AI Vendor Race
In a new report, Gartner positions AMD as the current front-runner for enterprise AI server CPUs.
June 24, 2026








Footnotes
1. Estimate based on 50,000 sensor readings per minute × 60 minutes × ~30 days = 72 million readings per month. This is at common cloud AI inference rates of $0.20 to $1.25 per 1,000 predictions (as published by AWS, Azure, and Google Cloud), monthly costs range from $14,400 to $90,000. Sources: Google Cloud Vertex AI Pricing, AWS SageMaker Pricing, Azure Machine Learning Pricing
2. Figure 2 Data collection details:
All validation, performance, and accuracy metrics are collected on the same system configuration:
Collected on March 28, 2025
System: HP OmniBook Ultra Laptop 14z
Processor: AMD Ryzen™ AI 9 HX 375 W/ Radeon 890M
Memory: 32GB of RAM
Software: ONNX TurnkeyML v6.1.1
The Hugging Face transformers framework is used as the baseline implementation for speedup and accuracy comparisons. The baseline checkpoint is the original safetensors Hugging Face checkpoint in the bfloat16 data type.
All speedup numbers are the measured performance of the model with input sequence length (ISL) of 1024 and output sequence length (OSL) of 64, on the specified backend, divided by the measured performance of the baseline.
The Ryzen AI OGA Featured LLMs table was compiled using validation, benchmarking, and accuracy metrics as measured by the ONNX TurnkeyML v6.1.1 lemonade commands in each example link. After this table was created, the Lemonade SDK moved to the new location found here.
Footnotes
1. Estimate based on 50,000 sensor readings per minute × 60 minutes × ~30 days = 72 million readings per month. This is at common cloud AI inference rates of $0.20 to $1.25 per 1,000 predictions (as published by AWS, Azure, and Google Cloud), monthly costs range from $14,400 to $90,000. Sources: Google Cloud Vertex AI Pricing, AWS SageMaker Pricing, Azure Machine Learning Pricing
2. Figure 2 Data collection details:
All validation, performance, and accuracy metrics are collected on the same system configuration:
Collected on March 28, 2025
System: HP OmniBook Ultra Laptop 14z
Processor: AMD Ryzen™ AI 9 HX 375 W/ Radeon 890M
Memory: 32GB of RAM
Software: ONNX TurnkeyML v6.1.1
The Hugging Face transformers framework is used as the baseline implementation for speedup and accuracy comparisons. The baseline checkpoint is the original safetensors Hugging Face checkpoint in the bfloat16 data type.
All speedup numbers are the measured performance of the model with input sequence length (ISL) of 1024 and output sequence length (OSL) of 64, on the specified backend, divided by the measured performance of the baseline.
The Ryzen AI OGA Featured LLMs table was compiled using validation, benchmarking, and accuracy metrics as measured by the ONNX TurnkeyML v6.1.1 lemonade commands in each example link. After this table was created, the Lemonade SDK moved to the new location found here.