Kog Reaches 3.5× Breakthrough Inference Speed on AMD Instinct MI300X GPUs
Jul 14, 2025
Author: Kog AI
The information contained in this blog represents the opinion of Kog AI as of the date presented. AMD and/or Kog AI have no obligation to update any forward-looking content in the blog. AMD is not responsible for the content of this third-party blog and does not necessarily endorse the comments/claims/information presented therein.
Kog Inference Engine sets a new standard for AI Inference speed with up to 3.5× faster token generation with the AMD Instinct™ MI300X GPU when compared to other inference engines.
As AI models continue to scale, inference, not training, has become the critical frontier. Generating more tokens faster during inference is now the main driver of real performance gains. Agents, deep research, experts' orchestration, and reasoning models all need fast sequential token outputs. However, most existing GPU inference engines are primarily optimized for aggregated throughput and chatbot use cases, failing to address sequential decoding speed per request.
Additionally, industry-wide challenges are limiting AI application scalability, including:
● Latency bottlenecks killing user experience in voice and gaming applications, (time-to-first-token issues)
● Sequential processing limitations blocking advanced agentic workflows
● Infrastructure costs spiraling out of control for high-volume inference
● Vendor lock-in limiting deployment flexibility and cloud sovereignty
These aren't just technical challenges. They are business blockers preventing companies from scaling their AI applications profitably.
The root cause? Current inference engines were designed for yesterday's AI workloads. The solution requires abandoning incremental improvements and reimagining inference optimization entirely to achieve performance that current frameworks simply can't match.
A New State-Of-The-Art For Speed
Across all tested model sizes, from 1B to 32B active parameter models, Kog consistently outperforms leading inference solutions running on industry top-tier GPUs, including vLLM and TensorRT-LLM on MI300X, H100, H200 and B200 GPUs.
This first benchmark focuses on maximizing token generation speed per individual request, with efficient parallelization of model inference on the 8 GPUs of a single server node.
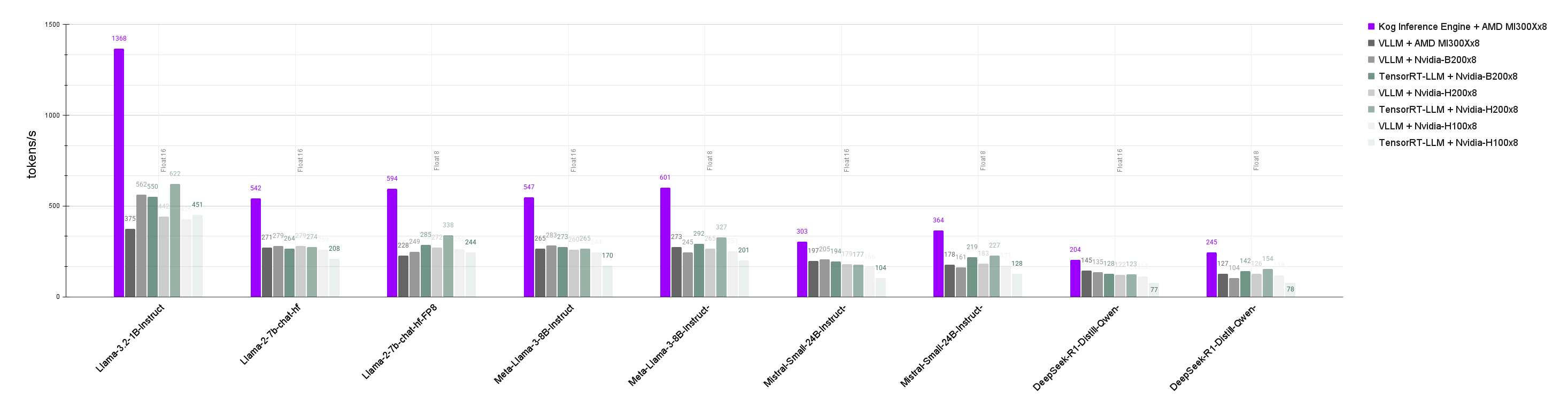
Key results:
● Up to 3.5× faster token generation vs vLLM and TensorRT-LLM on AMD Instinct MI300X GPUs versus the competition
● Consistent leadership across all model sizes tested (1B to 32B active parameters) for a variety of Llama, Mistral, and Qwen models
● Lowest cross-GPU latency achieved: 4μs, up to 4× faster than existing communication libraries
Kog excels particularly in small models (1B-7B parameters) that can be specialized and fine-tuned to match the accuracy of much bigger models on specific tasks at a fraction of the cost, while performing ten times faster.
Kog’s Radical Approach to Inference
Instead of relying on general-purpose frameworks, we engineered Kog Inference Engine at the lowest level, using optimized C++ and assembly code to remove inefficiencies and overcome a wide variety of hardware and software bottlenecks.
One critical innovation was reducing cross-GPU communication latency, an area where standard frameworks struggle. To solve this, Kog crafted KCCL (Kog Collective Communications Library) to achieve record-low latencies.
Kog architectural principles enable the co-construction of optimized inference capabilities for any GPU infrastructure, with teams facing specific latency, throughput, or voice-processing needs,including use cases in agentic, STT and real-time speech applications, with packaging in API or Docker formats to support rapid evaluation.
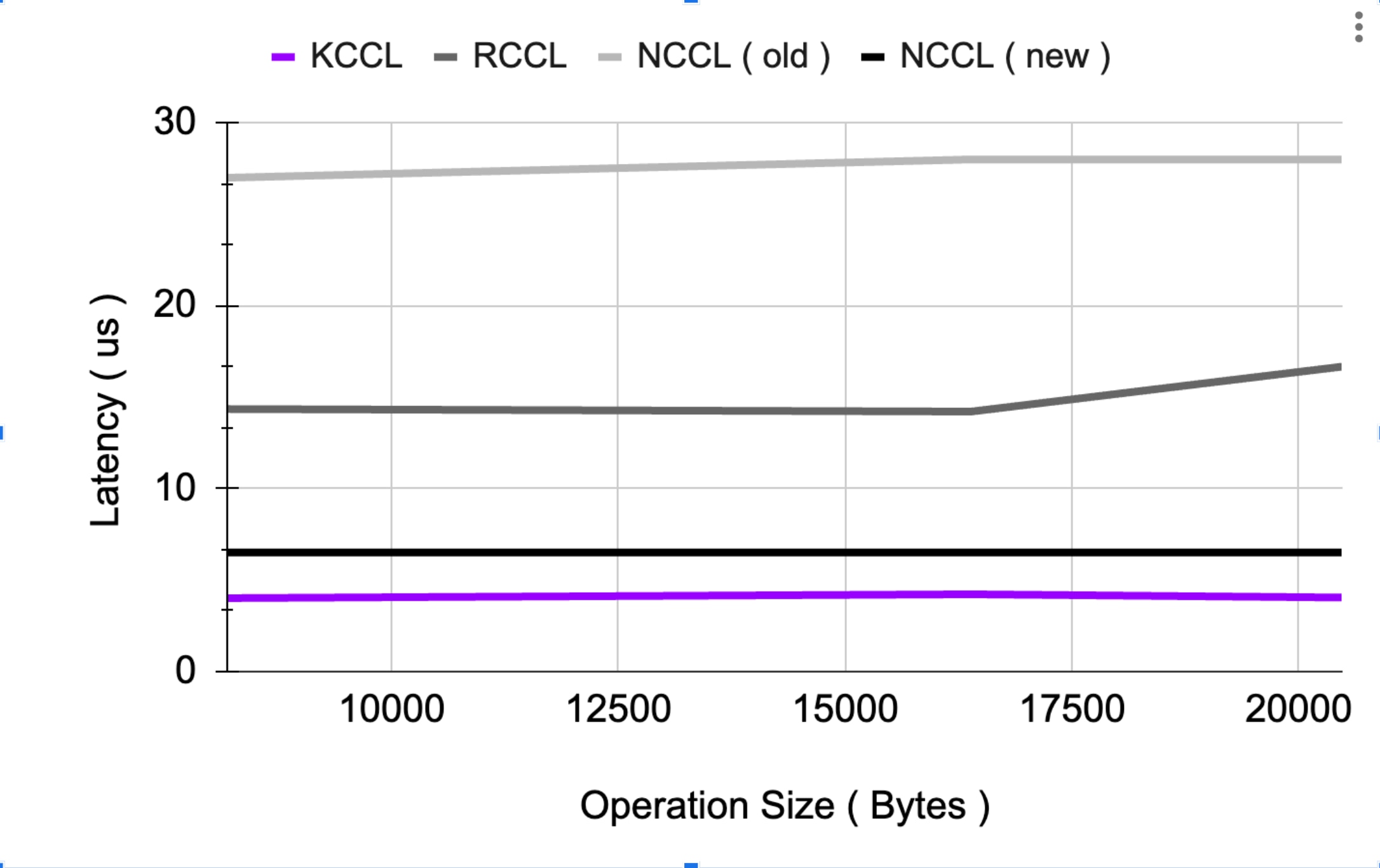
Benchmark Set-up:
AMD
Benchmark were conducted on 8×MI300X GPUs (Infinity Fabric) via Nscale using Lenovo ThinkSystem SR685a V3 servers : GPU AMD Instinct MI300X OAM | 8xGPUs 384 vCPU • 2200 GB , 192x8 GB VRAM with Ubuntu 22.04 + ROCm 6.3.1, Python 3.10.12, and vLLM v0.8.3 (PyPl).
NVIDIA
Benchmark were conducted on 8× H100 / H200 GPUs (NVLink, SXM5 interconnect) via Nebius using Shadeform VMs and 8x B200 GPUs via RunPod containers.
● H100 (Gpu H100 Sxm | 8xGPUs 128 vCPU • 1600 GB RAM • 640 GB VRAM) with Ubuntu 22.04 + CUDA 12.4 ML, Python 3.10.12, PyTorch 2.6, and vLLM v0.8.3 (PyPI),TensorRT-LLM v0.20.0rc0.
● H200 (Gpu H200 sxm | 8xGPUs 128 vCPU • 1600 GB RAM • 1128 GB VRAM) with Ubuntu 22.04 + CUDA 12.4 ML, Python 3.10.12, PyTorch 2.6, and vLLM v0.8.3 (PyPI),TensorRT-LLM v0.20.0rc0.
● B200 (Gpu B200 | 8xGPUs 288 vCPU • 2264 GB RAM • 1440 GB VRAM) with Ubuntu 22.04 + CUDA 12.8.1 ML, Python 3.11, PyTorch 2.8, and vLLM v0.8.3 (build from source),TensorRT-LLM v0.20.0rc0(build from source).
Methodology : Generation speed was measured using vLLM, TensorRT-LLM, and Kog Inference Engine with a custom script (also official benchmark scripts when its available) generating 4096 tokens from 100-token random prompts (batch size = 1, TP= 8, 10 warm-up + 1 benchmark iteration.)
Kog AI is a European startup building a real-time AI platform, driven by the conviction that it will be the foundation of new human-machine interactions. This vision unlocks a wide variety of AI use cases requiring instant intelligence and seamless experiences. Built in France with independent innovation in AI infrastructure, supporting European competitiveness and digital sovereignty.


Related Blogs
-
Train and Run Models on AMD GPUs with Unsloth
Train, fine-tune, run AI models with Unsloth on AMD GPUs across Windows, WSL and Linux, with native inference for leading models.
July 20, 2026
-
Microsoft Azure Expanding AI Infra Choice with AMD Helios™
Microsoft and AMD expand Azure AI infrastructure with AMD Instinct MI455X and Helios, delivering more choice, scale, and efficiency.
July 20, 2026
-
Open Standards, Real Solutions: AMD at SIGGRAPH 2026
AMD heads to DigiPro and SIGGRAPH 2026 to discuss open standards, production technology, and the fine art of Gaussian splatting.
July 17, 2026
-
How Pixar and AMD Scale Rendering for Artists
See how Pixar, Ranch Computing, and AMD brought production-grade RenderMan workflows, mentorship, and cloud rendering to creators worldwide.
July 17, 2026
-
FastFlowLM Joins AMD to Advance AI Inference
The FastFlowLM team has joined AMD, marking another key step in AMD’s strategy to advance AI performance and efficiency across the stack.
July 17, 2026
-
From Pixels to Predictions: Edge AI Pipeline Acceleration
Learn how AMD Vitis™ AI & AMD Vitis Video Analytics SDK (VVAS) use Gstreamer to build real-time Edge AI pipelines on AMD Versal™ AI Edge Series Gen 2.
July 16, 2026
-
Running Cloud Agents? Your Most Important Upgrade Could be an AMD Zen 5 CPU
As agents begin navigating applications, coordinating tools and completing real work, the local CPU is becoming a critical part of the AI execution pipeline.
July 16, 2026
-
Multi-Accelerator Support for AIMs and AMD Solution Blueprints — ROCm Blogs
Deploy and run AIMs and AMD Solution Blueprints across AMD Instinct™ GPUs, AMD EPYC™ CPUs, and AMD Radeon™ GPUs
July 15, 2026







