Google ADK + AMD Instinct™ GPUs: The Dynamic Duo for AI Agents
Jul 30, 2025

“AI agents will become the primary way we interact with computers in the future. They will be able to understand our needs and preferences, and proactively help us with tasks and decision making.” – Satya Nadella, CEO of Microsoft
You may be reading this blog having heard that agentic AI is the next big thing. You may be right! Today, we briefly introduce you to how you could get the well-crafted Google Agent Developer kit (Google ADK) to run on the AMD developer cloud using your own models.
TLDR; here’s what you can expect throughout the rest of this blog article:
- Learn how to utilize Google ADK on AMD GPUs with your own models.
- Step-by-step instructions for setting up a Google ADK Agentic AI application locally.
- Explore next steps to leverage AMD Developer Cloud resources
Quick Primer on Google ADK:
Google ADK is a flexible and modular framework designed for developing and deploying AI agents. ADK is model-agnostic, deployment-agnostic, and is built for compatibility with other frameworks. ADK was designed to make agent development more similar to software development, simplifying the process for developers to create, deploy, and orchestrate agentic architectures that handle tasks ranging from simple to complex workflows.
Benefits of Using Your Own Hardware and Models
While the default path for Google ADK is to leverage Google Cloud Platform (GCP) and proprietary models like Gemini, this approach raises critical questions for developers seeking more flexibility and control:
- What if your use case requires greater control over the AI models, such as the ability to fine-tune them or run them locally to guarantee absolute data privacy?
- What if your strategy involves moving beyond a single cloud vendor to optimize for cost efficiency or to harness the raw power of specialized hardware?
This blog and tutorial address these challenges directly. We will provide a technical demonstration of how to port a Google ADK application to the AMD developer cloud, leveraging the power of AMD Instinct™ GPUs and giving you the blueprint to run powerful AI agents on your own terms, for example, using open-source Large Language Models (LLMs) served locally with vLLM or Ollama.
We'll deconstruct the "Purchasing Concierge" Codelab example and rebuild it to decouple the dependency on GCP and Gemini models.
The Purchasing Concierge example uses 3 agents:
- The purchasing agent (i.e, the root agent) – uses Google ADK
- A burger seller agent – uses CrewAI agents
- A pizza seller agent – uses LangChain agents
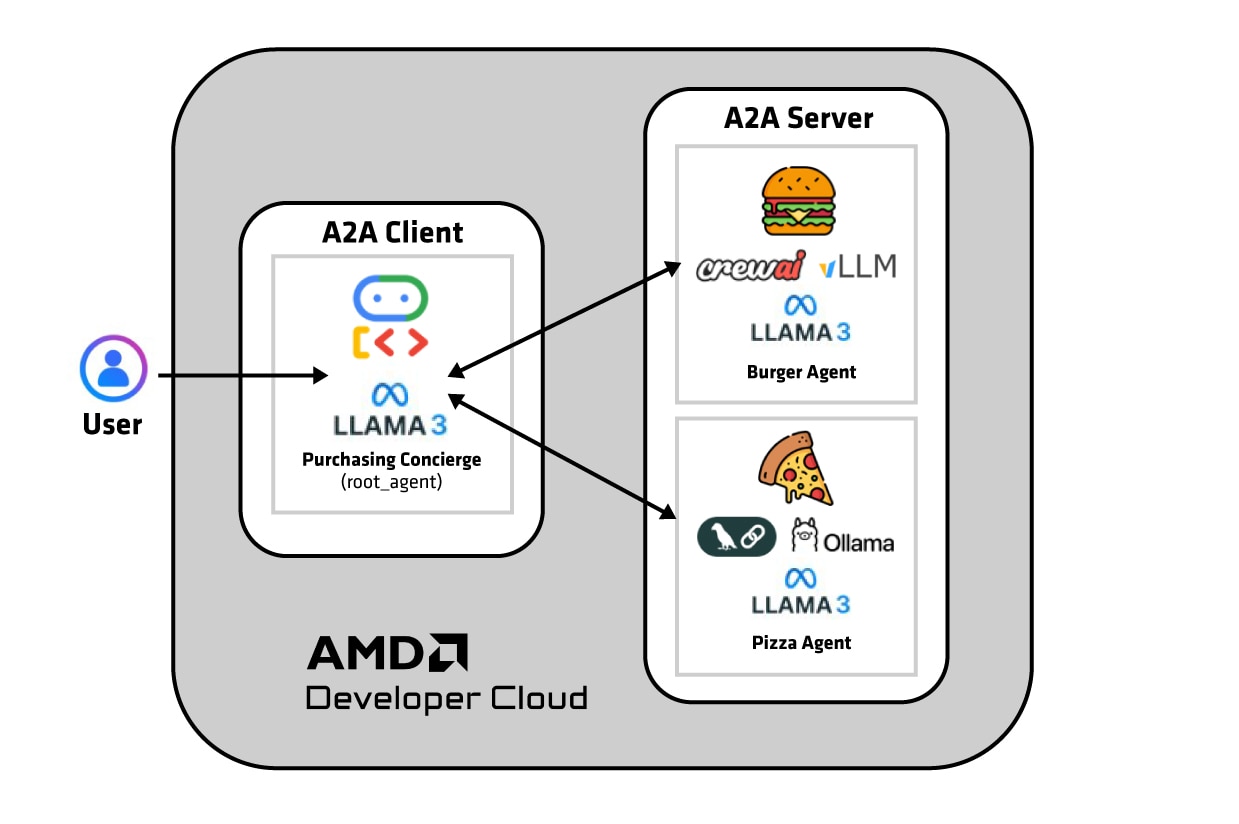
Figure 1: AI Agent Architecture -- Google ADK root agent orchestrates tasks with independent LangChain and CrewAI seller agents, all running on the AMD Developer Cloud.
As you can see, the above agent applications are quite heterogeneous. Yet, they all work well together through agentic communication, where the agents expose their capabilities using agent cards and talk to each other through tasks. Google ADK makes it easy to build an agentic AI application by plugging pieces together like Lego blocks. The Google ADK documentation site is a great place to learn more about agentic AI – this topic is outside the scope of this blog.
The Porting Process: A Step-by-Step Guide
Step 1: Set Up Your AMD Developer Cloud Environment
First, you'll need access to the AMD developer cloud. It provides ready-to-use virtual machines equipped with AMD Instinct GPUs and pre-installed AMD ROCm™ software, making setup a breeze.
A detailed blog on this topic is available here, but here’s a quick primer:
Launch a VM: Choose an instance with an AMD Instinct MI300X GPU. For serving powerful LLMs, having ample VRAM (the MI300X GPU comes with 192GB) is crucial. Select a pre-configured image with Docker and ROCm software to save time and effort.
SSH into your instance: Once your VM is running, connect to it using SSH. You'll find yourself in a powerful, GPU-accelerated Linux environment, ready for action.
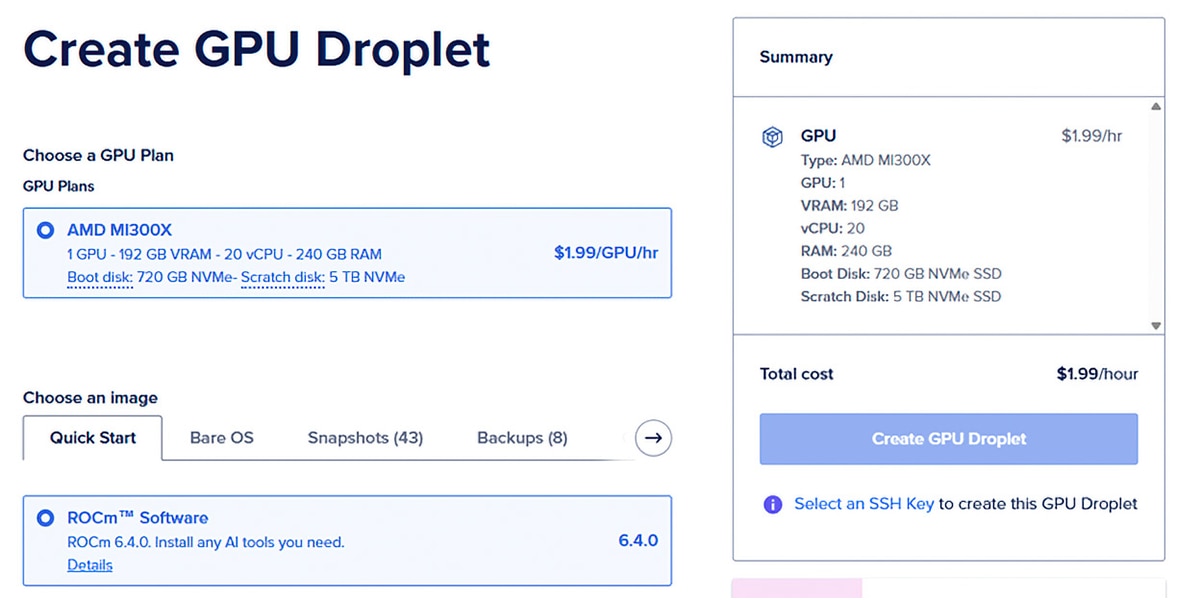
Figure 2: AMD Developer Cloud GPU VM Creation Page
Step 2: Clone the Original Project
Run the following command to clone the original project:
git clone https://github.com/alphinside/purchasing-concierge-intro-a2a-codelab-starter.git purchasing-concierge-a2a
If you want a quick shortcut and checkout the fully-ported code, then clone this repository.
The above repository also contains a Docker-compose script which you could use to launch all agents and respective frameworks at once.
Step 3: Serve Local LLMs for our Agents
The key to making Google ADK work with a local model is to expose that model through an OpenAI-compatible API endpoint. Both vLLM and Ollama excel in this area. In our example, we will demonstrate the use of two different serving frameworks for our two agents implemented with completely different agentic frameworks (Pizza Seller: LangChain, Burger Seller: CrewAI). This way, we are simulating two different independent companies that want to expose their digital services using their own agentic implementation but using a common language.
Burger seller: Using vLLM as model-serving framework
vLLM is a high-performance serving engine. To serve a model like Llama 3 with an OpenAI-compatible API. We recommend using the ROCm-optimized vLLM Docker:
docker run -d -p 8088:8088 -it --ipc=host --network=host --privileged --cap-add=CAP_SYS_ADMIN --device=/dev/kfd --device=/dev/dri --device=/dev/mem --group-add render --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -e HF_TOKEN=$HF_TOKEN --name vllm_latest rocm/vllm:latest
We then enter the Docker and serve our Llama3 model. Notice how I used llama3_json as a tool-call-parser and adopted a chat-template. This helps to use the Llama3 model in our agentic AI use-case.
docker attach vllm_latest
export HF_TOKEN=<Your_HF_Token>
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--enable-auto-tool-choice \
--tool-call-parser llama3_json \
--port 8088 \
--chat-template /work/projects/vllm_setup/vllm/examples/tool_chat_template_llama3.1_json.jinja
The vLLM server is now serving Llama3 model on port 8088 and is ready to receive requests.
Pizza Seller: Using Ollama (for simplicity and model management)
Ollama makes it incredibly easy to download and run a wide variety of LLMs.
# Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Pull and run the model (this also starts the server)
ollama run llama3
By default, Ollama exposes an OpenAI-compatible API at http://localhost:11434/v1. It's that simple.
Step 4: Adapt the ADK Code to Use the Local Model
Step 4a: Adapting the purchasing_concierge agent (i.e the root agent)
This is the core of the porting process. Google ADK is designed to be model-agnostic through its use of LiteLLM, a library that provides a unified interface for over 100 LLMs. Instead of initializing a Gemini model, we will initialize a LiteLLM model object and point it to our local server(s) – in this case, vLLM and Ollama.
Adapting the purchasing agent (the root agent):
We first import LiteLLM and instead of calling gemini-2.0-flash-001, we make a call to our Ollama model:
from google.adk.models.lite_llm import LiteLlm
[…]
# model=#"gemini-2.0-flash-001",
model=LiteLlm(model=os.getenv("OLLAMA_MODEL")),
[…]
You will notice that I have defined my model in an environment variable called OLLAMA_MODEL here. As a best practice in software engineering, you should have variables or data that can change in an external file. uv projects use a convenient .env file for environment variables. We will use that to store our model name.
Therefore, I add the following lines in the .env file in the root purchasing_concierge folder.
OLLAMA_MODEL="ollama_chat/llama3.1:latest"
OLLAMA_BASE_URL=http://localhost:11434
Now, you will notice that I actually don’t use the OLLAMA_BASE_URL in my purchasing_agent.py agent implementation code, although I have left it there for reusability with non-LiteLLM frameworks. LiteLLM uses the following format -for the model: <provider/model_name>. Here, LiteLLM knows that I am using an Ollama model, having defined the provider to be ollama_chat, and therefore already knows that the default URL is http://localhost:11434. For more information on LiteLLM providers, consult this documentation: https://docs.litellm.ai/docs/providers
This concludes adapting the root agent.
Step 4b: Adapting the burger_seller agent
The burger seller will demonstrate the use of vLLM as the model serving framework. In the .env file within the remote_seller_agents/burger_agent folder, we will add the following new environment variables:
OPENAI_API_BASE="http://localhost:8088/v1" # vLLM serve URL (we used port 8088 here)
VLLM_MODEL="hosted_vllm/meta-llama/Llama-3.1-8B-Instruct"
We can comment the GCLOUD_* variables as they won’t be used.
CrewAI, by default, uses LiteLLM; therefore, the porting is relatively straightforward. At the time of testing LiteLLM with Ollama models in CrewAI, we got several internal bugs related to CrewAI. However, we did not see these issues with vLLM models.
Instead of using VertexAI, which is also Google-Cloud-centric, we adapt the code accordingly and comment all pieces of the litellm.vertex_* definitions.
Was:
[…]
# model = LLM(
# model="vertex_ai/gemini-2.0-flash",
# )
Now:
[…]
model = LLM(
model=os.getenv("VLLM_MODEL"), #VLLM_MODEL
api_base=os.getenv("OPENAI_API_BASE") # OPENAI_API_BASE
)
[…]
And voilà – we are done with the burger seller agent. Now up to the pizza seller agent.
Step 4c: Adapting the pizza_seller agent
The pizza seller agent is built with LangChain, and we will use a Llama3 model served by Ollama. LangChain does not use LiteLLM; therefore, the Ollama model name format will differ slightly from what we have seen earlier, i.e., we do not specify a <provider> here.
As we did previously, we add the model details in the .env file located in the remote_seller_agents/pizza_agent folder.
OLLAMA_MODEL="llama3.1:latest"
OLLAMA_BASE_URL=http://localhost:11434
The pizza seller also uses Google VertexAI, so in the code, we comment this import and use ChatOllama from langchain_ollama instead:
# from langchain_google_vertexai import ChatVertexAI
from langchain_ollama import ChatOllama
Finally, the code adaptation boils down to the following. We comment the usage of ChatVertexAI and Gemini models and use ChatOllama:
Was:
[…]
# self.model = ChatVertexAI(
# model="gemini-2.0-flash",
# location=os.getenv("GCLOUD_LOCATION"),
# project=os.getenv("GCLOUD_PROJECT_ID"),
# )
[…]
Now:
[…]
self.model = ChatOllama(
model= os.getenv("OLLAMA_MODEL")
)
[…]
We are now done with our code porting, and we can simply test all our work by:
- Starting the pizza and burger agents (for example, in two different terminals, so you can see the responses from the agents)
This is done by simply calling uv run . from each seller’s root folder.
The above command should start the two servers exposing the capabilities of each agent through what we call “agent cards”. In each of the root seller folders, there is a Dockerfile which you could also use to run the agents in docker containers. - Starting the main application by executing:
uv run purchasing_concierge_demo.py
Bonus: The quick shortcut repository in Step 2 above provides a convenient Docker-compose script which you could also use to start all services at one go.
The above steps will start a server on http://localhost:8080
If everything works well, you should be able to interact with our agents like this:

Summary and Next Steps
In this blog post, you have learned how to locally port a Google cloud / Gemini-centric agentic AI example that uses Google ADK and a number of other frameworks to run on your local infrastructure with your own models of choice. The possibilities are limitless!
Next steps you can take:
1) Leverage the AMD Developer Cloud: Access compute resources on AMD Developer Cloud with AMD Instinct GPUs and claim your free hours as a developer. (T&Cs apply.)
2) Explore open-source tools: Dive deeper with open-source software like Google ADK, LiteLLM, vLLM and Ollama. Be creative as you experiment with building your own agentic AI applications to meet your needs and ideas.
The journey into agentic AI is just beginning. Get started on your applications today!


Related Blogs
-
Open Standards, Real Solutions: AMD at SIGGRAPH 2026
AMD heads to DigiPro and SIGGRAPH 2026 to discuss open standards, production technology, and the fine art of Gaussian splatting.
July 17, 2026
-
FastFlowLM Joins AMD to Advance AI Inference
The FastFlowLM team has joined AMD, marking another key step in AMD’s strategy to advance AI performance and efficiency across the stack.
July 17, 2026
-
Running Cloud Agents? Your Most Important Upgrade Could be an AMD Zen 5 CPU
As agents begin navigating applications, coordinating tools and completing real work, the local CPU is becoming a critical part of the AI execution pipeline.
July 16, 2026
-
From Vector Search to Agentic RAG: Building an Enterprise Research Analyst with hipVS — ROCm Blogs
Learn how to build an agentic RAG research assistant using hipVS GPU-accelerated vector search on AMD Instinct GPUs, with multi-query decomposition, parallel retrieval, and cited sources synthesis.
July 14, 2026
-
When a Faster Kernel Doesn’t Speed Up Serving: Profiling FP8 KV Cache on AMD Instinct MI308X — ROCm Blogs
Learn how a 34% faster FP8 KV cache kernel delivered 0% E2E speedup, and how profiling attribution exposed the hidden dtype-cast cost on MI308X.
July 14, 2026
-
What to Expect at AMD Advancing AI 2026
Get a preview of AMD Advancing AI 2026, including key themes, sessions, and innovations shaping the future of AI. Discover how industry leaders are coming together to explore real-world use cases and strategies for scaling AI across the enterprise.
July 14, 2026
-
Local Image and Video Generation on AMD Ryzen™ AI Max+ Processor (Windows) — ROCm Blogs
Run ComfyUI natively on Windows on AMD Ryzen AI Max+ with ROCm 7.2.1—SDXL, Flux, and video workflows on the Radeon 8060S, no WSL.
July 13, 2026
-
Announcing the ROCm Certification Program
Build AI and HPC expertise on AMD Instinctt™ GPUs. Earn the ROCmt™ Certification with hands-on, production-ready skills.
July 13, 2026







