InferenceMAX™: Benchmarking Progress in Real Time
Oct 10, 2025

Living Benchmarks
Traditional benchmarks capture a single moment in time, but they can become outdated quickly if kernels, compilers, and frameworks improve at a rapid pace. InferenceMAX™ redefines benchmarking as a living process, tracking inference performance across vendors, models, and workloads continuously.
While SemiAnalysis runs InferenceMAX™ continuously, each published result represents a snapshot in time, such as last night’s run, within a steady cycle of optimization. The results, therefore, reflect the current state of kernel efficiency for specific model configurations, rather than the inherent capability of the hardware. Customers can see not only where kernel efficiency stands today but also how rapidly each platform advances. This shift from static claims to continuous measurement makes benchmarking more accurate, reliable, and forward-looking on AMD Instinct GPUs, in collaboration with the technical team at SemiAnalysis.
Accelerating AI with AMD Instinct MI350 Series GPUs
At the core of this transformation are the AMD Instinct™ MI350 Series GPUs, built on the 4th Gen AMD CDNA™ architecture, designed to accelerate generative AI workloads, modern ranking, and recommendation workloads. These GPUs enable advanced AI applications, including agent and chatbot workloads, content generation, summarization, and conversational AI, helping organizations scale AI capabilities efficiently.
AMD Instinct MI350 Series GPUs support the new lower-precision MXFP4 and MXFP6 datatypes for higher efficiency and throughput in large language models. An AMD Instinct MI355X GPU offers up to 10 petaFLOPS (MXFP4/MXFP6) for both training and inference. An 8x GPU MI355X platform scales this performance to up to 80 petaFLOPS (MXFP4/MXFP6), with up to 2.3 TB of HBM3E memory and 64 TB/s of memory bandwidth for high-capacity, high-bandwidth workloads. The UBB 2.0 form factor simplifies system validation and deployment and is offered in both air‑cooled and liquid‑cooled configurations to suit different thermal, power, and density requirements.

Software Optimizations Unlock Peak Hardware
While hardware defines the ceiling of performance, the true potential is realized only when software fully harnesses it. AMD Instinct GPUs already provide massive compute and memory capacity, but their utilization depends on better kernels, compilers, and scheduling.
This is where AMD invests heavily. Optimizations like MXFP4 packing, fused attention kernels, cache-aware memory tiling, and wavefront-aware scheduling push workloads closer to the theoretical peak. Over time, the same hardware delivers higher performance as AMD ROCm™ software improvements roll out.
The open-source approach of ROCm software accelerates this process. Developers worldwide can test, refine, and share optimizations. Once the individual optimization code is merged into the ROCm software, each improvement compounds across the ecosystem, raising performance for everyone.
InferenceMAX™ benchmarks from SemiAnalysis demonstrate strong results for AMD Instinct™ GPUs with ROCm 7, including a 5x generational improvement from the MI300X to the MI355X (Figure 1)
![Figure 1. Token Throughput per GPU vs Interactivity, GPT-OSS-120B, ISL/OSL: 1K/1K, MI355x vs MI300X [1]](/content/dam/amd/en/images/blogs/designs/technical-blogs/inferencemax--benchmarking-progress-in-real-time/Figure)
Figure 1. Token Throughput per GPU vs Interactivity, GPT-OSS-120B, ISL/OSL: 1K/1K, MI355x vs MI300X [1] Source: SemiAnalysis
While DeepSeek-R1 runs on SGLang by default, AMD’s joint work with customers on vLLM has yielded exceptional results (Figure 2). Performance under SGLang is improving quickly, and parity is expected soon.
Figure 2. Throughput vs. latency, DeepSeek-R1 FP8, MI355X with vLLM vs. B200 with TRTLLM [2] Source: SemiAnalysis
In general, AMD Instinct™ MI300X and MI325X GPUs offer leadership performance and cost advantages. MI355X GPU builds on this foundation, demonstrating exceptional efficiency across a wide range of InferenceMAX benchmarks. Only three months after launch, InferenceMax testing shows MI355X GPU is extremely competitive and ongoing compiler, kernel, and framework tuning are driving rapid gains that will further strengthen AMD performance and efficiency leadership.
ROCm software continues to advance rapidly, with frequent kernel and framework updates improving throughput and scalability. Current development priorities include an FP4xFP8 MoE kernel for GPT-OSS, SGLang parity with vLLM on MI355X GPU for DeepSeek, and fused operator optimizations for Llama 3.3 70B.
AMD Instinct™ MI355X GPU demonstrates strong, efficient performance across a wide range of workloads in InferenceMAX™ benchmarks. In some scenarios, competing platforms may edge ahead, but that only reflects the snapshot nature of performance today. With ROCm software evolving daily and new kernel optimizations landing continuously, the MI355X GPU improves at a rapid pace.
InferenceMAX™ highlights not only where the MI355X GPU excels now, but also where gains are arriving soon. It shows that the community can benefit from robust performance today and measurable improvements tomorrow.
Steps to run InferenceMAX
Getting started with InferenceMAX™ is straightforward. Follow the steps below to set up your environment and begin running the benchmarks.
Prerequisites
MI355X GPU installed machine(s) with Docker installed
Step 1: Fork the Repository and Configure Secrets
- Fork the repository to your GitHub account
- Navigate to Settings → Secrets and variables → Actions in your forked repository
- Add the following repository secrets:
HF_TOKEN- HuggingFace token for model accessREPO_PAT- GitHub personal access token with repo and workflow permissions
Step 2: Install and Register Self-Hosted Runners
- On your GPU machine(s), navigate to your repository’s Settings → Actions → Runners → New self-hosted runner
- Follow GitHub’s installation instructions to download and configure the runner agent
- Register each runner with a label matching the workflow patterns:
- Format: {
gpu-type}-{provider}_{index} - Examples: mi300x-amd_0,mi355x-amd_0
- These labels must match the runs-on values in .github/workflows/runner-test.yml:11-48
- Format: {
- Ensure Docker is accessible by the runner user (no sudo required):
sudo usermod -aG docker $USER - Create HuggingFace cache directory (required by workflows):
sudo mkdir -p /mnt/hf_hub_cache/
sudo chown -R $USER:$USER /mnt/hf_hub_cache/
Step 3: Launch Your First Benchmark
- Navigate to Actions tab in your forked repository
- Select “Test - Runner” workflow from the left sidebar
- Click “Run workflow” and configure:
- Runner: Select your registered runner label (e.g.,
mi355x-amd) - Docker Image: Choose framework image (e.g., rocm/7.0:rocm7.0_ubuntu_22.04_vllm_0.10.1_instinct_20250927_rc1)
- Model: Select model to benchmark (e.g.,
deepseek-ai/DeepSeek-R1-0528, openai/gpt-oss-120b) - Framework: Choose
vllm,sglang - Precision: Select fp8 or fp4
- Experiment Name: Use
70b_test, dsr1_test, or gptoss_test
- Runner: Select your registered runner label (e.g.,
- Click “Run workflow” - your self-hosted runner will execute the benchmark
Continuous Improvement: Case Study GPT-OSS
We tracked the performance of GPT-OSS 120B over a 2-month window and observed a pattern of steady software-driven improvement.
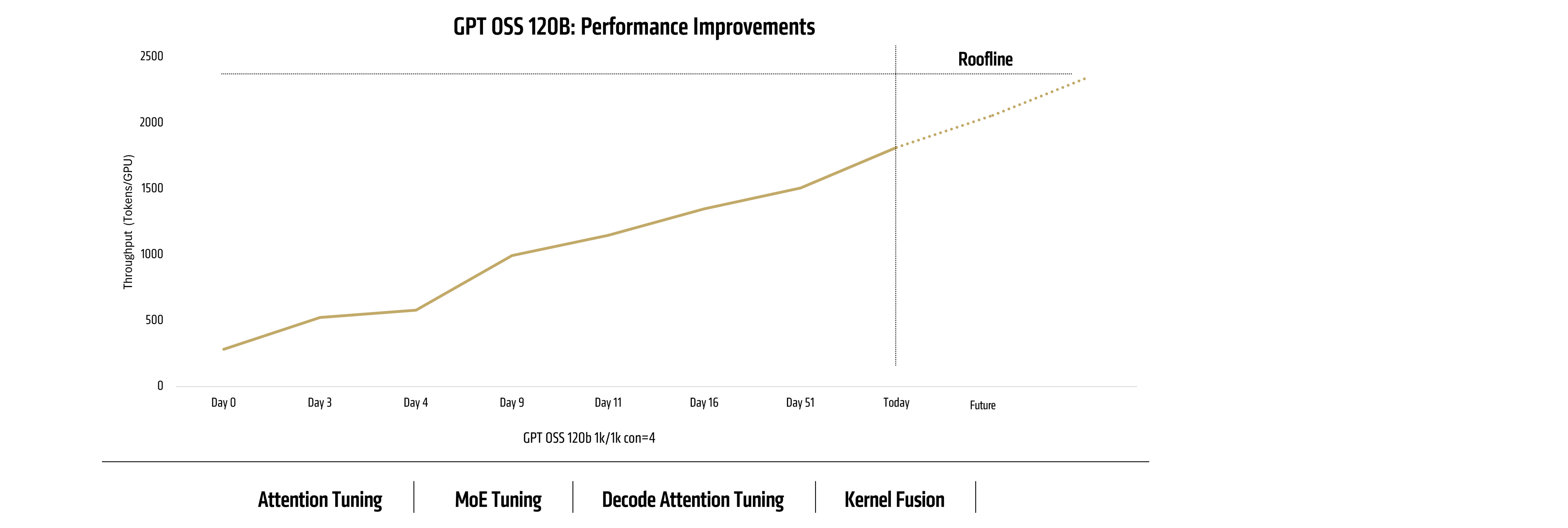
The trajectory shows the dynamic progression of performance improvement, making it clear that seeing continuous improvement can be better than relying merely on static benchmarks.
Conclusion
InferenceMAX™ makes this progress visible and accountable. Benchmarks are open and reproducible, allowing customers to validate claims on their own hardware. Performance measurement becomes an ongoing endeavor, not merely a static one-time assessment.
With ROCm software, nightly builds deliver fused kernels, improved frameworks, and community-driven enhancements. As adoption grows, the rate of improvement accelerates, creating a self-reinforcing cycle of innovation.
The message is clear:
- Hardware is strong
- Software is accelerating
- Progress is open and transparent
This is just the start. Every night gets better.
Set up InferenceMAX™ and share your results to help drive continuous improvement.
Footnotes
[1] 1k/1k run, 10/05/2025, 8:16 PM PDT
[2] 1k/1k run, 10/05/2025, 8:16 PM PDT; 1k/8k run, 10/05/2025, 8:21 PM PDT
All performance and/or cost savings claims are provided by the 3rd party organization featured herein and have not been independently verified by AMD. Performance and cost benefits are impacted by a variety of variables. Results herein are specific to such 3rd party organization and may not be typical. GD-181a.


Related Blogs
-
The Journey Begins: AMD, SUSE and Rancher Government Solutions (RGS) Team Up on Initial Validation of Enterprise AI Blueprints
AMD, SUSE, and RGS are delivering a secure, open AI platform to accelerate private, sovereign, and enterprise AI deployments.
July 22, 2026
-
Kimi Code in MXFP4 on AMD GPUs
Discover how ATOM accelerates Kimi K2.5, K2.6, and K2.7-Code inference with optimized serving on AMD Instinct™ GPUs.
July 21, 2026
-
AMD Data Intelligence Platform: Open Modular Blueprint
See how AMD built OPTIMA, an open data intelligence platform that connects enterprise data for AI agents, analytics, and automation.
July 21, 2026
-
Rebuilding Agentic AI for AMD GPU
AMD and Moonshot AI built an agentic AI serving stack that optimizes KV cache, scheduling, and GPU performance on AMD Instinct™ GPUs
July 21, 2026
-
Efficient MiniMax-M3 Inference on AMD Instinct GPUs with ATOM and ATOMesh — ROCm Blogs
Serve and benchmark MiniMax-M3 on AMD Instinct MI355X GPUs using ATOM and ATOMesh with EAGLE3 speculative decoding.
July 20, 2026
-
Building a High-Performance Video Inference Pipeline with ROCm Libraries Using C/C++ — ROCm Blogs
Learn how to build a powerful, GPU-accelerated video analytics pipeline with ROCm, combining rocDecode for fast hardware video decoding and MIGraphX for efficient AI-powered analysis and inference.
July 20, 2026
-
Train and Run Models on AMD GPUs with Unsloth
Train, fine-tune, run AI models with Unsloth on AMD GPUs across Windows, WSL and Linux, with native inference for leading models.
July 20, 2026
-
Microsoft Azure Expanding AI Infra Choice with AMD Helios™
Microsoft and AMD expand Azure AI infrastructure with AMD Instinct MI455X and Helios, delivering more choice, scale, and efficiency.
July 20, 2026







