AMD PACE - A vLLM Plugin for CPU Inference
Jun 11, 2026

Introduction
The way large language models are served in production has converged around a small set of frameworks, and vLLM has emerged as one of the most widely adopted of these. Its scheduler, KV-cache management, and serving APIs have become the default plumbing that AI teams build around - from research notebooks to large-scale production deployments. At the same time, the demand for running these same models efficiently on CPUs continues to grow, especially in data centers where 5th Gen AMD EPYC™ processors are already powering the underlying infrastructure.
AMD PACE (AMD Platform Aware Compute Engine), a research framework was built to push CPU inference performance for transformer models on AMD EPYC as a standalone, high-performance inference server.
With this release, we are taking the next logical step: making PACE available as a plugin for vLLM. Users who already rely on vLLM for serving can now opt into PACE’s CPU-optimized backends - attention, MLP, normalization, and more - without changing the way they deploy or operate their stack.
This blog walks through why we chose the plugin path, how the integration is structured, and the four (soon to be five) building blocks that make up the PACE vLLM plugin today.
Why a Plugin? The vLLM + PACE Narrative
For deployments running LLM inference on a scale on vLLM, the PACE plugin is offered as an additional option. Because PACE is delivered as a plugin, users can adopt individual optimizations as they become available, validate them against their own workloads, and roll back without disruption. The goal is straightforward: on a 5th Gen AMD EPYC processor, enabling the PACE plugin to deliver measurably better latency and throughput, with no application code changes.
Technical Overview: The PACE vLLM Plugin
PACE plugs into vLLM through the platform plugin interface. The integration is a single extra install on top of an existing vLLM environment, with no application code changes; the command used to start vLLM is unchanged.
pip install pace-vllm
At startup, vLLM discovers the plugin, and it should run as the platform on this host. On AMD EPYC with AVX512 support, the plugin activates and serves as the platform; on any other hardware it returns control to vLLM, which continues with its default platform.
Once active, vLLM retains responsibility for the scheduler, request lifecycle, OpenAI-compatible API, and continuous batching. PACE provides the worker, model runner, KV Cache management and attention backend, and custom CPU operators that handle linear, normalization, and MLP execution on AMD EPYC cores.
The PACE plugin is delivered in four components in this first release. Each is an independent change inside the plugin and can be enabled or disabled through configuration. Support for MOE is under active development and would be part of subsequent release.
The four components in this first release are:
- Plugin infrastructure - registering PACE as a vLLM plugin.
- SLAB backend - KV Cache Management and attention implementation wired in through the plugin.
- Linear and normalization operators - drop-in CPU-tuned replacements.
- Fused MLP - a fused implementation of the MLP block activated when pattern is detected in compile mode.
The sections below describe each of these in turn.
1. Plugin Infrastructure
PACE is delivered as a pip-installable package that shares a Python environment with vLLM. Installation places the plugin's Python files and native libraries into that environment. The integration itself runs at startup: vLLM discovers the plugin, calls into it, and the plugin checks whether the host is AMD EPYC with AVX512 support. If so, it activates, loads its native libraries, so its CPU kernels are registered with PyTorch's operator registry, and provides vLLM with its platform definition. From this point on, vLLM uses its existing plugin hooks to select the worker, model runner, attention backend, and custom CPU operators, and those hooks resolve the PACE implementations rather than the defaults. vLLM continues to issue the same calls; PACE provides the corresponding implementations.
2. SLAB Attention Backend
SLAB is one of the attention strategies PACE supports as a standalone server. It is a unified AVX-512 attention dispatcher that classifies each sequence by query length and routes it to a suitable kernel - GQA-aware decode with online softmax, multi-token decodes for speculative verification or tiled prefill. On AMD EPYC, this consistently delivers strong decode and prefill performance, particularly for the medium-context, medium-batch regimes that dominate production traffic.
3. Linear and Normalization Operators
Linear projections - Q/K/V, output, and the gate/up/down projections inside MLP - are some of the compute-intensive operators in a transformer. PACE’s linear kernels use cache-blocked micro-kernels with weight matrices pre-packed into blocked layouts that match the SIMD tile dimensions, eliminating runtime reordering. Normalization (RMSNorm) is similarly tuned for AVX-512 and fused where it makes sense to keep data on chip.
4. Fused MLP
In standard implementations, the MLP block in a transformer is expressed as a sequence of linear projections with an activation function (typically SwiGLU or GELU) in between. Each of these is a separate kernel with its own memory traffic. PACE’s fused MLP collapses these stages into a single, cache-aware kernel. The gate and up projections are fused, the activation is applied inline, and the down projection consumes the activation output without round-tripping through DRAM. Block sizes are chosen to keep the working set inside L1 and L2 caches on EPYC cores, and the weights are pre-packed in the same blocked layout used by the linear kernels in component 3, so there is no layout shuffle at the boundary.
Evaluation
Feature |
Specification |
CPU |
AMD EPYC™ 9755, codename “Turin” |
Architecture |
Zen 5 |
Cores |
128 cores per socket |
RAM |
1.5 TB |
Precision |
BF16 |
Sockets |
2 |
We compare vLLM with the PACE plugin enabled against stock vLLM on the same hardware, across:
- A representative set of model architectures and sizes (e.g., Llama-3.1-8B, Qwen2-7B, Phi-4, Gemma-3-4B/12B).
- Input/output length combinations covering short and long contexts.
- Batch sizes spanning low-latency (BS=1) and throughput-oriented (BS=32, 128) regimes.
- Auto regressive decode and serving workloads driven by vLLM’s native bench serve benchmark suite.
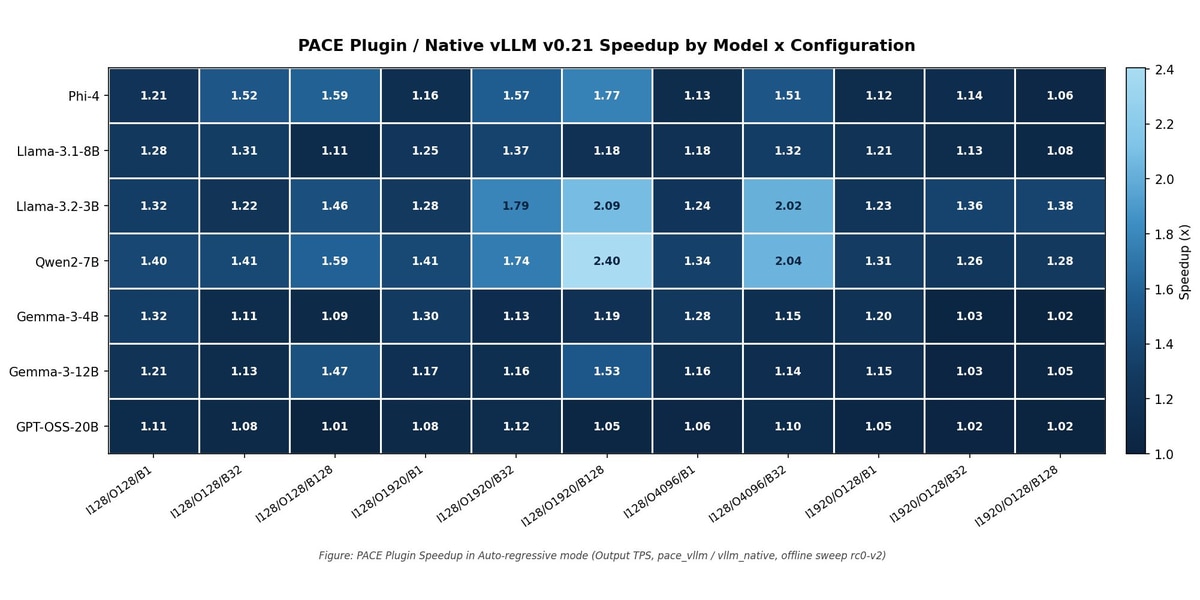
Note: The vLLM PACE plugin retains 92-98% of standalone PACE efficiency. It also makes operator level optimizations for future cores and models straightforward to add.
Conclusion
vLLM has become the default substrate for LLM inference, and AMD EPYC is one of the most widely deployed CPU platforms in the data center. The PACE vLLM plugin sits at the intersection of both. The four components in this initial release stand on their own and compose cleanly with the rest of vLLM. With the fifth component on the way, and additional attention backends already lined up behind the same plugin contract, PACE on vLLM is set up to keep improving in step with both projects.
We look forward to feedback from the community as more teams turn the research plugin on against their own workloads.
Resources
Footnotes
Endnote
A system configured with an AMD EPYC™ 9755 processor was used to evaluate vLLM with the AMD PACE plugin enabled versus stock vLLM 0.21.0 (used for both native and PACE). Testing done by AMD on May 25, 2026; results may vary based on configuration, usage, software version, and optimizations. SYSTEM CONFIGURATION: Supermicro; AMD EPYC 9755 128-Core Processor (2 sockets, 128 cores per socket, 2 threads per core); 1 NUMA node per socket; 1536 GB memory (24 DIMMs, 6400 MT/s, 64 GiB/DIMM); Ubuntu 24.04.2 LTS, kernel 6.8.0-86-generic
Footnotes
Endnote
A system configured with an AMD EPYC™ 9755 processor was used to evaluate vLLM with the AMD PACE plugin enabled versus stock vLLM 0.21.0 (used for both native and PACE). Testing done by AMD on May 25, 2026; results may vary based on configuration, usage, software version, and optimizations. SYSTEM CONFIGURATION: Supermicro; AMD EPYC 9755 128-Core Processor (2 sockets, 128 cores per socket, 2 threads per core); 1 NUMA node per socket; 1536 GB memory (24 DIMMs, 6400 MT/s, 64 GiB/DIMM); Ubuntu 24.04.2 LTS, kernel 6.8.0-86-generic


Related Blogs
-
Kimi Code in MXFP4 on AMD GPUs
Discover how ATOM accelerates Kimi K2.5, K2.6, and K2.7-Code inference with optimized serving on AMD Instinct™ GPUs.
July 21, 2026
-
Rebuilding Agentic AI for AMD GPU
AMD and Moonshot AI built an agentic AI serving stack that optimizes KV cache, scheduling, and GPU performance on AMD Instinct™ GPUs
July 21, 2026
-
Train and Run Models on AMD GPUs with Unsloth
Train, fine-tune, run AI models with Unsloth on AMD GPUs across Windows, WSL and Linux, with native inference for leading models.
July 20, 2026
-
Microsoft Azure Expanding AI Infra Choice with AMD Helios™
Microsoft and AMD expand Azure AI infrastructure with AMD Instinct MI455X and Helios, delivering more choice, scale, and efficiency.
July 20, 2026
-
GEAK V3: Agent-Driven, Repository-Level GPU Kernel Optimization across HIP, Triton, and FlyDSL on AMD GPUs — ROCm Blogs
Explore GEAK v3: agent-driven, repository-level GPU kernel optimization across HIP, Triton, and FlyDSL on AMD Instinct™ GPUs.
July 19, 2026
-
SPIR-V on ROCm: A Portable IR for AMD GPUs — ROCm Blogs
Learn how SPIR-V brings compile-once, specialize-on-device portability to AMD GPUs — with a reproducible HIP benchmark, trade-off analysis, and quick-start guide.
July 19, 2026
-
Open Standards, Real Solutions: AMD at SIGGRAPH 2026
AMD heads to DigiPro and SIGGRAPH 2026 to discuss open standards, production technology, and the fine art of Gaussian splatting.
July 17, 2026
-
FastFlowLM Joins AMD to Advance AI Inference
The FastFlowLM team has joined AMD, marking another key step in AMD’s strategy to advance AI performance and efficiency across the stack.
July 17, 2026







