Fast Multi-Model Deployment and Validation with JSON-Driven Configuration
Jan 15, 2026

Introduction
Artificial intelligence is no longer limited to single-model applications. In many real-world scenarios, multiple models need to work together to deliver a seamless user experience. This is especially true for applications that process multi-modal data such as video, audio, and text. A single model usually handles only one type of task (e.g., object detection, speech recognition, or translation), but complex applications often require a pipeline of models that run either in sequence (serial execution) or in parallel.
Take the example of a video conferencing application:
- On the video stream, one model might first perform super-resolution to enhance image quality, followed by another model that performs face detection or recognition. In addition, many conferencing systems also support background replacement (virtual background), which typically requires a segmentation model to separate the person from the background before overlaying a new scene.
- On the audio stream, a model may remove background noise and echo and then pass the cleaned signal to a speech recognition model. The recognized text can then be fed into a machine translation model to support real-time multilingual communication.
These workflows highlight two important aspects:
- Serial dependencies: Certain models depend on the outputs of others. For example, face recognition requires an enhanced frame from the super-resolution model.
- Parallel opportunities: Some tasks can run simultaneously to improve efficiency. In the conferencing example, video and audio pipelines are largely independent and can be processed in parallel.
Managing such pipelines manually is complex. Developers must write orchestration code, ensure data dependencies are respected, and manage concurrency — all of which increase development time and make experimentation harder. What if you want to quickly test whether switching the order of two models improves performance, or try running different parts of the pipeline in parallel? Without a flexible framework, this often requires significant code changes.
To solve this challenge, we designed a JSON-driven multi-model deployment tool. With it, developers can describe the execution rules of multiple models — including both serial and parallel relationships — in a configuration file. The tool automatically interprets the configuration, builds a dependency graph, and schedules the tasks accordingly. This allows for rapid verification of multi-model pipelines without rewriting orchestration logic, enabling faster iteration and more reliable deployment of complex AI systems.
Challenges in Multi-Model Deployment
Building applications that rely on multiple AI models is not as straightforward as running a single model. In practice, developers often face several challenges:
- Heterogeneous models from different vendors
Applications may combine models provided by different vendors, each with their own format, pre/post-processing requirements, and performance characteristics. Ensuring that these models interoperate correctly can be a non-trivial task. - Different execution providers (EPs)
To achieve the best performance, some models may run on the CPU, others on GPU, and still others on specialized accelerators such as NPUs, FPGAs, or DSPs. Managing these execution providers and coordinating data movement between them adds significant complexity. - Execution order and multithreading
When multiple models must run in sequence or in parallel, developers need to write multithreaded code to maximize efficiency. This involves handling thread synchronization, ensuring data dependencies are respected, and avoiding deadlocks or race conditions. - High maintenance when swapping models
Replacing one model with another (e.g., updating to a newer version of a face recognition model) often requires rewriting parts of the application. This slows down experimentation and increases maintenance costs. - Different pipelines require different programs
For every new execution order — such as changing the sequence of preprocessing, recognition, and translation — developers traditionally need to rewrite orchestration logic. This results in a massive engineering effort, especially when experimenting with multiple pipeline configurations.
Solution: JSON-Driven Multi-Model Pipeline
To overcome the challenges of orchestrating multiple AI models, we propose a JSON-driven deployment tool. Instead of writing custom code for every pipeline, developers can use a declarative JSON configuration to describe what models to run, in what order, and on which device. The tool then automatically builds the execution graph, schedules tasks, and manages synchronization.
Core Idea
- Declarative orchestration: Pipelines are described in JSON, not hardcoded in application logic
- Array = sequential execution: Models listed in an array run one after another
- Object = parallel execution: Models grouped in an object run concurrently
- Nested structures: Arrays and objects can be nested to express arbitrarily complex workflows
- Unified task definition: Each task specifies its model file, execution provider, and optional runtime parameters
- This design allows pipelines to be reconfigured simply by editing JSON, without rewriting the program
Execution Model
The tool interprets the pipeline structure recursively:
- Array ([...]) → run tasks in sequence
- Object ({...}) runs branches in parallel
- Nested structures → combine sequence and parallelism flexibly
Example: A video pipeline (super-resolution → segmentation → background replacement) runs in parallel with an audio pipeline (echo cancellation → speech recognition → translation):
{
"params": {
"video_sr": {
"model": "sr.onnx",
"provider":"NPU"
},
"seg": {
"model": "seg.onnx",
"provider":"CUDA"
},
"bg_replace": {
"model": "bg.onnx",
"provider":"CPU"
},
"aec": {
"model": "aec.onnx",
"provider":"DSP"
},
"asr": {
"model": "asr.onnx",
"provider":"CUDA"
},
"mt": {
"model": "mt.onnx",
"provider":"CPU"
}
},
"tasks": {
"video_branch": [
"video_sr",
"seg",
"bg_replace"
],
"audio_branch": [
"aec",
"asr",
"mt"
]
}
}
Here:
- Inside the config, an object defines two branches (video_branch and audio_branch) that run in parallel
- Within each branch, tasks run sequentially
Configurable Runtime Parameters
Each model can be fine-tuned with its own runtime parameters, enabling performance optimization without code changes.
{
"tasks": {
"seg": {
"model": "seg.onnx",
"xclbin": "AMD_AIE2P_4x4_Overlay.xclbin",
"opt_level": "info"
},
"aec": {
"model": "aec.onnx",
"xclbin": "AMD_AIE2P_4x4_Overlay",
"fps": "50",
"priority": "realtime"
}
}
}
Scheduling & Execution
The orchestration engine works as follows:
- Parse JSON → read task definitions and pipeline structure
- Build DAG (Directed Acyclic Graph) → derive dependencies from dataflow and pipeline semantics
- Schedule tasks → run ready tasks immediately, leveraging multi-threading for parallel branches
- Manage synchronization → ensure sequential tasks wait for predecessors; parallel tasks run independently and rejoin when needed
- Execute with providers → each model is dispatched to its assigned execution provider
Minimal pseudocode:
function run_pipeline(node):
if node is string:
run_task(node)
else if node is array:
for step in node:
run_pipeline(step) # sequential
else if node is object:
futures = []
for key, branch in node.items():
futures.append(spawn_thread(run_pipeline, branch)) wait_all(futures)
Benefits
- This JSON-driven approach directly addresses the earlier challenges:
- Heterogeneous models → unified representation in JSON
- Different execution providers → explicitly declared per task, automatically handled
- Multithreading complexity → hidden behind declarative parallel objects
- Model replacement → swap model path or parameters in JSON, no code rewrite
- Pipeline variations → change order or parallelism by editing JSON, not building new programs
In short, developers can focus on designing workflows, while the tool handles execution logic. This reduces engineering effort, accelerates experimentation, and makes multi-model deployment practical across diverse hardware.
Example
Assuming that we are running models ranging from A to J in the arranged order as shown in the picture below:
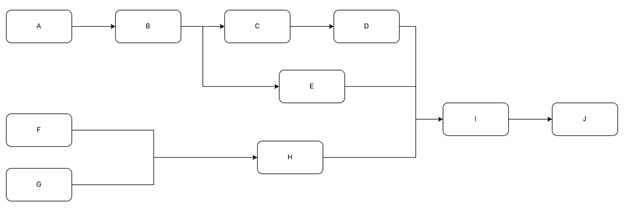
then the JSON configure should be
{
"params": {
"A": {
"model": "A.onnx",
"provider":"VitisAI"
},
"B": {
"model": "B.onnx",
"provider":"VitisAI"
},
"C": {
"model": "C.onnx",
"provider":"CPU"
},
"D": {
"model": "D.onnx",
"provider":"DSP"
},
"E": {
"model": "E.onnx",
"provider":"CUDA"
},
"F": {
"model": "F.onnx",
"provider":"CPU"
},
"G": {
"model": "G.onnx",
"provider":"CUDA"
},
"H": {
"model": "H.onnx",
"provider":"CUDA"
},
"I": {
"model": "I.onnx",
"provider":"VitisAI"
},
"J": {
"model": "J.onnx",
"provider":"VitisAI"
},
},
"tasks": [
{
"pipeline1" : [
"A",
"B",
{
"pipeline2" : [
"C",
"D"
],
"pipeline3" : "E"
}
],
"pipeline4" : [
{
"pipeline5" : "C",
"pipeline6" : "D"
},
"H"
]
},
"I",
"J"
]
}
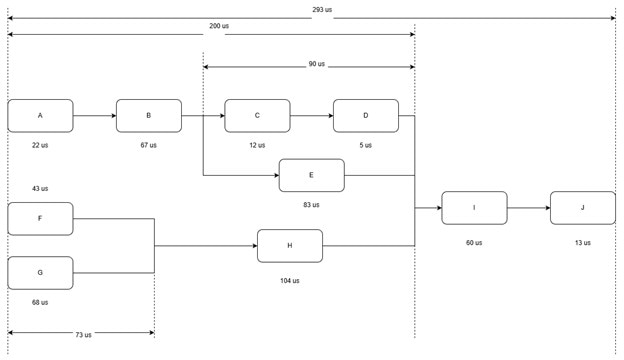
Then it will generate a corresponding JSON output which indicates how long it takes for each phase.
[ {"inference_time" : 293}, { "pipeline1":[ {"inference_time" : 200}, {"A" : 22}, {"B" : 67} { {"inference_time" : 90}, "pipeline2" : { "C" : 12, "D" : 5 }, "pipeline3" : { "E" : 83 } } ], "pipeline4": [ { {"inference_time" : 73}, "pipeline5" : { "F" : 43 }, "pipeline6" : { "G" : 68 } }, "H" : 104 ] }, {"I" : 60}, {"J" : 13} ]
Conclusion
Deploying multi-model AI pipelines is complex, requiring careful orchestration, synchronization, and hardware management. A JSON-driven approach abstracts this complexity, allowing developers to define sequential and parallel workflows declaratively. By automatically building execution graphs, managing dependencies, and handling multiple execution providers, the tool accelerates experimentation, simplifies model replacement, and enables efficient multi-modal AI deployment. This framework empowers developers to focus on innovation, while JSON-driven orchestration ensures reliability, flexibility, and scalability across diverse AI applications.


Related Blogs
-
The Importance of Open Ecosystems for Agentic AI Deployment
Enterprise agents need access to applications and data across the business. Open ecosystems help prevent AI vendor lock-in from standing in their way
July 30, 2026
-
Advancing AI 2026 Developer Sessions
See how Advancing AI 2026 brought together 2,000+ developers for workshops, technical sessions, and hands-on demos.
July 30, 2026
-
Closing the GPU Cluster Validation Gap: A Kubernetes-Native Approach with CVF — ROCm Blogs
Learn how to validate AMD GPU clusters end-to-end with CVF: hardware acceptance, mesh bandwidth, RDMA, and RCCL testing in one pipeline.
July 28, 2026
-
AMD GPU Operator v1.5.0: DRA Support, Automated GPU Node Recovery, and Expanded Kubernetes Infrastructure Control — ROCm Blogs
Discover how AMD GPU Operator v1.5.0 improves GPU scheduling, automates node recovery, and expands Kubernetes control.
July 27, 2026
-
Kimi-K3 on AMD Instinct GPUs
Day 0 support for Kimi-K3 on AMD Instinct MI355X GPUs with validated TP8 setups.
July 27, 2026
-
Attention Decode on AMD MI450 GPUs: A Gluon Kernel Optimization Guide — ROCm Blogs
Learn how to design a high-performance attention decode kernel on AMD MI450 GPUs using Gluon.
July 26, 2026
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026
-
Introducing Instella-MoE: A State-of-the-Art Fully Open Mixture-of-Experts Language Model — ROCm Blogs
Explore Instella-MoE-16B-A3B, AMD’s fully open 16B MoE LLM with 2.8B active params per token, trained on AMD Instinct™ MI300 & MI325 GPUs.
July 23, 2026







