A Practical Method for Evaluating Punctuation Model Accuracy
Jan 14, 2026

Automatic Speech Recognition (ASR) is a key technology for today’s voice-driven applications such as virtual assistants, real-time transcription, and speech-based user interfaces. As these applications more often use large language models (LLMs), the quality of ASR output has become crucial. In particular, clean and well-structured text with proper punctuation is essential for both human readability and effective processing by LLMs.
However, some ASR models—such as Zipformer—produce text without any punctuation. The output is essentially a long stream of words, which is harder for humans to read and also less suitable as input for LLMs. This is because LLMs are typically trained on large text corpora that include proper punctuation and sentence boundaries; unpunctuated ASR output can hurt overall system performance.
To solve this problem, a punctuation model is often applied after ASR. The punctuation models add the right punctuation marks to the raw ASR output. This improves readability and makes the text better suited for use as an LLM prompt. Despite their widespread use in practice, however, there is limited discussion on how to evaluate punctuation models in a clear, systematic, and reproducible manner. In this blog, we introduce a practical method for evaluating punctuation model accuracy using real-world data with the Sherpa-ONNX framework and demonstrate how it can support informed model selection for efficient deployment on AMD Ryzen™ AI platforms.
Model Preparation
There are several existing punctuation restoration models, such as the models mentioned in https://k2-fsa.github.io/sherpa/onnx/punctuation/index.html?highlight=punctuation. In our experiments, we evaluate two representative models: a fixed-point model and a floating-point model.
- Download the two model packages
- # wget https://github.com/k2-fsa/sherpa-onnx/releases/download/punctuation-models/sherpa-onnx-punct-ct-transformer-zh-en-vocab272727-2024-04-12-int8.tar.bz2
- # wget https://github.com/k2-fsa/sherpa-onnx/releases/download/punctuation-models/sherpa-onnx-punct-ct-transformer-zh-en-vocab272727-2024-04-12.tar.bz2
- Extract the two bz2 files and only copy the contained ONNX file to a target directory, for example, c:\test\.
Prerequisites
Build sherpa-onnx in below steps:
# git clone https://github.com/k2-fsa/sherpa-onnx
# cd sherpa-onnx
# cmake -G "Visual Studio 17 2022" -A x64 -B build . -DCMAKE_BUILD_TYPE=Release -DSHERPA_ONNX_ENABLE_BINARY=OFF -DSHERPA_ONNX_ENABLE_WEBSOCKET=OFF -DSHERPA_ONNX_ENABLE_TTS=OFF
# cd build
# cmake --build . --config release -j 16
Sherpa is the deployment framework supporting deploying speech related pre-trained models on various platforms. This step will build the lib file to run punctuation model.
Prepare Golden File and Test File
We select an existing dataset for evaluation. Specifically, we use the VocalNo dataset available on Hugging Face https://huggingface.co/datasets/t0bi4s/vocalno/blob/main/train.csv or https://huggingface.co/datasets/t0bi4s/vocalno/blob/main/validation.csv . The first one has 897 sentences and the second one has 100 sentences. We will use the first one in the test below.
Download the first file and make the following modifications.
- Remove the trailing audio file references (e.g., audio/000***.wav) from each line. This can be easily accomplished using a modern text editor or simple scripting tools.
- Append the Chinese full stop “。” to the end of each line if it is not already present. This step is necessary because the punctuation model consistently inserts “。” at sentence boundaries; enforcing a uniform ending avoids unnecessary accuracy degradation during evaluation.
- Remove all whitespace characters from the file.
After these modifications, the resulting file is treated as the ground-truth reference and is renamed to f_golden.txt.
Next, create a copy of this file named f_input.txt. Further process this copy by removing all punctuation marks. The resulting file serves as the input text for the punctuation model during testing.
Prepare Test Code
Organize your project directory using the following structure:
include\
sherpa-onnx\
csrc\
offline-punctuation.h
offline-punctuation-model-config.h
parse-options.h
src\
test_punctuation.cpp
lib\
sherpa-onnx-core.lib
onnxruntime.dll
CMakeLists.txt
- Copy the three header files from the include directory of the Sherpa-ONNX source code into the include directory of your project.
- Copy sherpa-onnx\build\lib\Release\sherpa-onnx-core.lib, which was generated in the previous build step, into the lib directory.
Content in CMakeLists.txt is:
cmake_minimum_required(VERSION 3.18.1)
project(test_punctuation)
set(CMAKE_CXX_STANDARD 20)
add_compile_options($<$<CONFIG:>:/MT> $<$<CONFIG:Release>:/MT>)
add_executable(test_punctuation ${CMAKE_SOURCE_DIR}/src/test_punctuation.cpp)
target_link_directories(test_punctuation PRIVATE ${CMAKE_SOURCE_DIR}/lib )
target_include_directories(test_punctuation PRIVATE ${CMAKE_SOURCE_DIR}/include )
target_link_libraries(test_punctuation PRIVATE sherpa-onnx-core onnxruntime)
Content in test_punctuation.cpp is:
#include <iostream>
#include <fstream>
#include "sherpa-onnx/csrc/offline-punctuation.h"
std::vector<std::string> get_file_line(const std::string & input_file) {
std::ifstream is(input_file);
if (is.is_open()) {
std::vector<std::string> stringv;
std::string line;
while(std::getline(is, line)) {
stringv.emplace_back(line);
}
return stringv;
} else {
std::cout <<"input file open error! \n";
exit(-1);
}
}
// usage: *.exe model_path input_file.txt
int32_t main(int32_t argc, char *argv[]) {
sherpa_onnx::OfflinePunctuationConfig cfgPunc;
std::unique_ptr<sherpa_onnx::OfflinePunctuation> punct;
cfgPunc.model.ct_transformer = argv[1];
cfgPunc.model.num_threads = 1;
cfgPunc.model.debug = false;
cfgPunc.model.provider = "cpu";
std::vector<std::string> stringv = get_file_line(argv[2]);
punct = std::make_unique<sherpa_onnx::OfflinePunctuation>(cfgPunc);
for(int j=0;j<stringv.size();j++) {
auto text_with_punct = punct->AddPunctuation(stringv[j]);
std::cout<< text_with_punct <<"\n";
}
return 0;
}
Build steps:
# cmake -G "Visual Studio 17 2022" -A x64 -S . -B build
# cd build
# cmake --build . --config release
Next, run the generated program using the following format:
# release\test_punctuation.exe c:\test\model.onnx some_path2\f_input.txt > f_output.txt
The resulting f_output.txt file contains the punctuated text generated by the model. When you open the file, you can see that the output closely resembles well-formed sentences with appropriate punctuation, making it easy for humans to read and suitable for processing by LLMs.
Accuracy Test
How can we determine and compare the accuracy of two punctuation models? Below, we introduce a simple and practical evaluation method.
Accuracy Evaluation Method
To compare the accuracy of two punctuation models:
- Run the punctuation model on f_input.txt to produce f_output.txt.
- Compare f_output.txt with f_golden.txt line by line and character by character.
- Count one difference whenever characters mismatch and skip to the next character.
This comparison is essentially a classic dynamic programming problem, which allows us to account for any insertions, deletions, and substitutions when computing the total number of differences.
The test_diff.py implements the above algorithm.
import sys
def min_diff_with_skips(str1, str2):
len1, len2 = len(str1), len(str2)
dp = [[0] * (len2 + 1) for _ in range(len1 + 1)]
for i in range(len1 + 1):
dp[i][len2] = len1 - i
for j in range(len2 + 1):
dp[len1][j] = len2 - j
for i in range(len1 - 1, -1, -1):
for j in range(len2 - 1, -1, -1):
if str1[i] == str2[j]:
dp[i][j] = dp[i+1][j+1]
else:
dp[i][j] = 1 + min(
dp[i+1][j+1],
dp[i+1][j],
dp[i][j+1]
)
return dp[0][0]
line_input = []
with open(sys.argv[1], 'r', encoding='utf-8') as file:
line_input = [line.strip() for line in file]
line_golden = []
with open('f_golden.txt', 'r', encoding='utf-8') as file:
line_golden = [line.strip() for line in file]
diff_input=0
for si, sg in zip(line_input, line_golden):
diff_input=diff_input+min_diff_with_skips(si, sg)
print("different number: ", diff_input)
You can run the Python script from the command prompt using the following command:
# python test_diff.py f_output.txt
The output is:
# different number: 1366
The total number of mismatched punctuation between the model output and the golden file is 1,366. The golden file contains a total of 2,880 punctuation marks. Therefore, the accuracy of the float model can be calculated as:
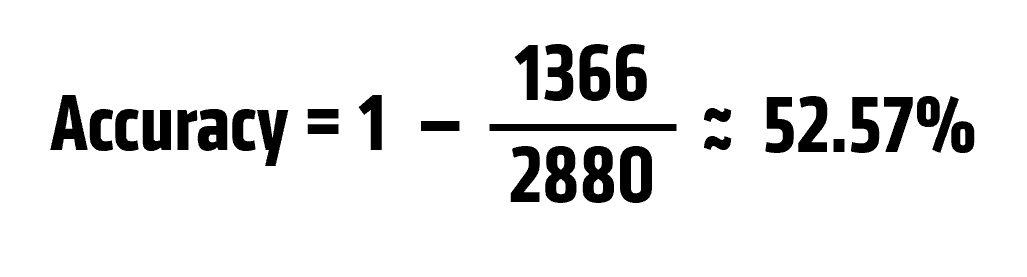
When testing with the fixed model, the total number of mismatched punctuation marks is 1,352. Given that the golden file contains 2,880 punctuation marks, the accuracy of the fixed model is:
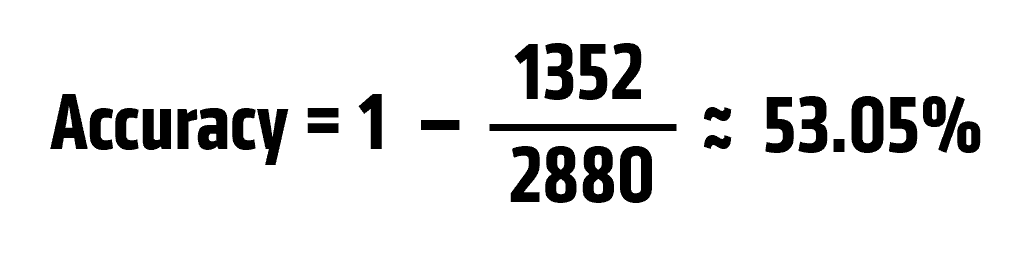
We also evaluated both models using a second test file containing 100 sentences.
The test results are summarized below:
| Test Set | Float Model | Int8 Model |
| 879 sentences | 52.57% | 53.05% |
| 100 sentences | 46.45% | 47.93% |
Because the float and int8 models achieve very similar accuracy—with the int8 model performing slightly better—the int8 model becomes the preferred choice for deployment pipelines. It not only maintains comparable accuracy but also provides significantly improved runtime performance.
Our performance measurements for the punctuation model are shown below:
| Metric | Float Model | Int8 Model |
| Model loading time | 400 ms | 140 ms |
| Memory usage | 700 MB | 260 MB |
Summary
In this blog, we presented a simple yet effective method for evaluating the accuracy of punctuation models. Using a real-world dataset and a reproducible evaluation workflow, we demonstrated how to compare punctuation models by measuring character-level differences between model output and ground-truth text.
Our experiments showed that both float and fixed models achieve similar accuracy, with the fixed model performing slightly better across both datasets. In addition to maintaining comparable accuracy, the fixed model significantly reduces model loading time and memory usage, making it a more practical choice for deploying punctuation restoration in ASR systems. For developers building speech-enabled applications on AMD Ryzen™ AI platforms, the evaluation approach presented here provides a clear and reliable way to select punctuation models that improve ASR output quality while balancing accuracy, performance, and efficiency.


Related Blogs
-
The Importance of Open Ecosystems for Agentic AI Deployment
Enterprise agents need access to applications and data across the business. Open ecosystems help prevent AI vendor lock-in from standing in their way
July 30, 2026
-
Advancing AI 2026 Developer Sessions
See how Advancing AI 2026 brought together 2,000+ developers for workshops, technical sessions, and hands-on demos.
July 30, 2026
-
Closing the GPU Cluster Validation Gap: A Kubernetes-Native Approach with CVF — ROCm Blogs
Learn how to validate AMD GPU clusters end-to-end with CVF: hardware acceptance, mesh bandwidth, RDMA, and RCCL testing in one pipeline.
July 28, 2026
-
AMD GPU Operator v1.5.0: DRA Support, Automated GPU Node Recovery, and Expanded Kubernetes Infrastructure Control — ROCm Blogs
Discover how AMD GPU Operator v1.5.0 improves GPU scheduling, automates node recovery, and expands Kubernetes control.
July 27, 2026
-
Kimi-K3 on AMD Instinct GPUs
Day 0 support for Kimi-K3 on AMD Instinct MI355X GPUs with validated TP8 setups.
July 27, 2026
-
Attention Decode on AMD MI450 GPUs: A Gluon Kernel Optimization Guide — ROCm Blogs
Learn how to design a high-performance attention decode kernel on AMD MI450 GPUs using Gluon.
July 26, 2026
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026
-
Introducing Instella-MoE: A State-of-the-Art Fully Open Mixture-of-Experts Language Model — ROCm Blogs
Explore Instella-MoE-16B-A3B, AMD’s fully open 16B MoE LLM with 2.8B active params per token, trained on AMD Instinct™ MI300 & MI325 GPUs.
July 23, 2026







