Precision Meets Automation: Auto-Search for the Best Quantization Strategy with AMD Quark ONNX
Jan 27, 2026

Auto-Search, a powerful new automated quantization exploration engine built into the AMD Quark ONNX optimization stack, is now available. Auto-Search is designed to intelligently navigate the increasingly complex landscape of quantization strategies, delivering the best configuration for each model, device, and deployment environment. In today’s rapidly evolving AI ecosystem—where inference efficiency defines user experience and operational cost—automating the search for optimal quantization parameters has become essential. Modern AI workloads demand not only low latency and high throughput, but also precision-preserving compression techniques that adapt to diverse architectures and hardware backends. Auto-Search addresses this challenge by providing a flexible, fully automated system that identifies the most effective quantization strategy with minimal manual intervention.
By integrating tightly with Quark’s quantization capabilities, Auto-Search automates the exploration of precision formats, calibration methods, fine-tuning techniques, and per-layer strategies, ensuring that models are optimized for the unique characteristics of each hardware target.
In this blog, we introduce Auto-Search, highlighting its design philosophy, architecture, and advanced search capabilities. We will walk through the system workflow, demonstrate how it simplifies quantization for ONNX models, and show how it enables reproducible, scalable, and production-ready model optimization. At this stage, Auto-Search focuses on ONNX-to-ONNX quantization for AMD Ryzen AI Processor and does not target PyTorch-based workflows.
What is Quark?
AMD Quark is an open-source model optimization library focused on AI model quantization, designed to enhance the performance of deep learning models across various deployment scenarios. It supports multiple hardware backends, including the AMD's data center GPUs, CPUs, and embedded SoCs. Quark offers a unified API for post-training quantization (PTQ), quantization-aware training (QAT), and fine-tuning. With seamless integration into PyTorch and ONNX ecosystems, Quark empowers users to optimize models for efficient inference on diverse platforms, including cloud, edge, and mobile devices.
For further information about Quark, please refer to AMD Quark Model Optimization Library Now Available as Open-Source
Why You Need Auto Search?
AMD Quark ONNX provides a comprehensive suite of quantization tools, offering flexibility with bit-width options such as INT8, XINT8, INT16, INT4, BF16, and FP16, along with multiple quantization schemes, including symmetric/asymmetric and per-channel/per-tensor. In addition, it supports multiple calibration methods, including MinMax, Percentile, and LayerWisePercentile, as well as fine-tuning techniques like AdaQuant and AdaRound. While these capabilities offer a lot of potential, finding the optimal quantization combination is complex and challenging.
Manual Quantization is Slow, Unpredictable, and Hard to Scale
This difficulty arises from several factors. The search space is vast, with many parameters interacting in ways that lead to exponential complexity. Additionally, the sensitivity of model accuracy can be a major issue, especially for architectures like attention mechanisms, depth-wise convolutions, and NAS models, which can degrade easily under suboptimal quantization. The problem is further compounded by hardware variability—optimal quantization strategies differ depending on whether the model runs on CPU, GPU, or NPU. Finally, the type of model also plays a critical role; for example, CNNs, transformers, and LLMs each require distinct quantization approaches for optimal performance.
AutoSearch pioneered automated quantization exploration, and Quark ONNX Auto-Search builds on this foundation with a host of powerful new capabilities. It supports hierarchical search spaces with conditional parameters, multiple sampling algorithms (TPE, Random, Grid, GPS, etc), and parallel trial execution. Robust checkpoints, resume functionality, and reproducible outcomes ensure reliability, while custom objective functions provide flexibility.
In particular, we highlight several advanced sampling algorithms proposed in Auto-Search. The Tree-structured Parzen Estimator (TPE) is a Bayesian optimization algorithm for hyperparameter tuning that improves performance by modeling the distributions of good and bad configurations separately, enabling efficient exploration–exploitation trade-offs, natural handling of conditional and hierarchical search spaces, scalability to high-dimensional mixed parameter spaces. In addition, we develop a grid-based sampling strategy tailored to the hierarchical structure of the search space. This design allows the sampler to systematically explore different levels of the hierarchy while preserving dependencies between parameters. We highlight this component as a key element of our framework, as it plays a crucial role in enabling efficient and structured exploration of the hierarchical search space.
Together, these features transform quantization into a high-performance, automated optimization engine that operates seamlessly across models, devices, and deployment targets.
Auto-Search Architecture and Workflow
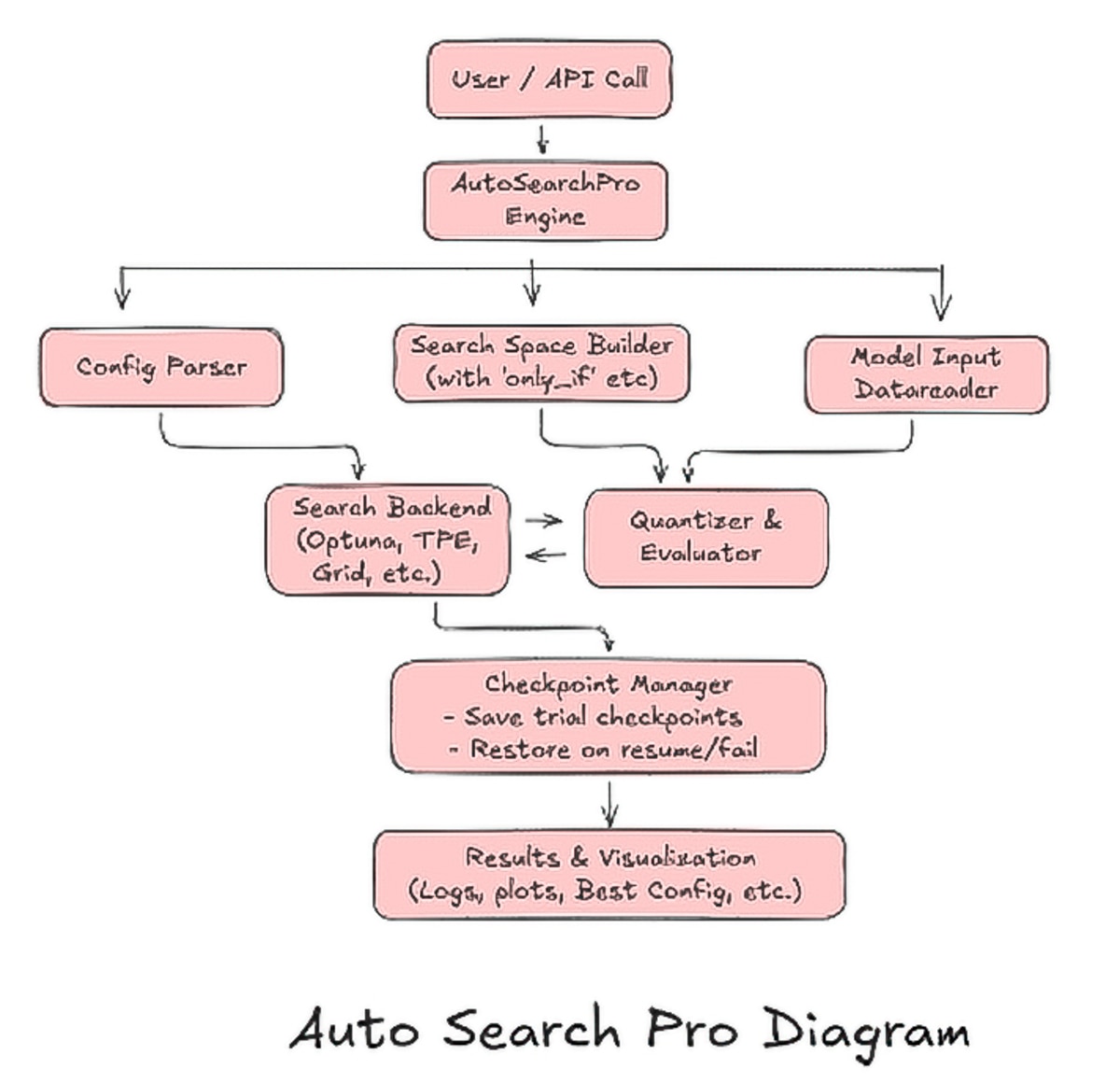
This system provides a streamlined, automated framework for optimizing AI models through quantization and fine-tuning. The workflow begins with a simple User/API call, where users specify the model path, data reader, search space, and constraints—setting the context for the entire optimization process.
At the center of the pipeline is the Auto-Search Core Engine, which dynamically explores quantization strategies, evaluates parameter combinations, and identifies the best configuration for each model. Supporting this is the Config Parser, which validates inputs and resolves dependencies to ensure smooth, error-free execution.
The Search Space Builder enables hierarchical and conditional search definitions, allowing the system to explore only relevant parameter combinations. The Model/Data Loader handles ONNX model loading and calibration data preparation, simplifying model integration.
The Search Backend drives the exploration using methods such as TPE, GPS, Random, Grid, or custom samplers. Each candidate configuration is then evaluated by the Evaluation Module, which performs quantization, inference, and metric computation to assess accuracy and efficiency.
For long or distributed runs, the Checkpoint Manager provides robust pause-and-resume capabilities. Finally, visualization tools offer interactive plots that reveal optimization history, parameter importance, and key correlations.
Together, these components form a flexible, scalable, and highly efficient pipeline that automates quantization exploration and delivers clear, actionable insights for deploying optimized AI models across diverse hardware and use cases.
Usage Example
Here we provide a simple example to demonstrate how to start auto-search using a predefined search space. For detailed usage, please refer to Automatic Search Pro for Model Quantization — AMD Quark 0.11 documentation and Quark ONNX Quantization Tutorial For Resnet50 — AMD Quark 0.11 documentation
import copy
from quark.onnx import AutoSearchPro, get_auto_search_config
def get_model_input():
pass
# return model_input_path
def prepare_datareader():
pass
# return calib_data_reader
# Get auto search pre-defined config
# Available auto search config: "XINT8_SEARCH", "A8W8_SEARCH", "A16W8_SEARCH"
auto_search_config_name = "XINT8_SEARCH"
quant_config = copy.deepcopy(get_auto_search_config(auto_search_config_name))
# Prepare model and calibration data reader
quant_config["model_input"] = get_model_input()
quant_config["calib_data_reader"] = prepare_datareader()
# Start auto search
auto_search_pro_ins = AutoSearchPro(quant_config)
best_params = auto_search_pro_ins.run()
Image Zoom
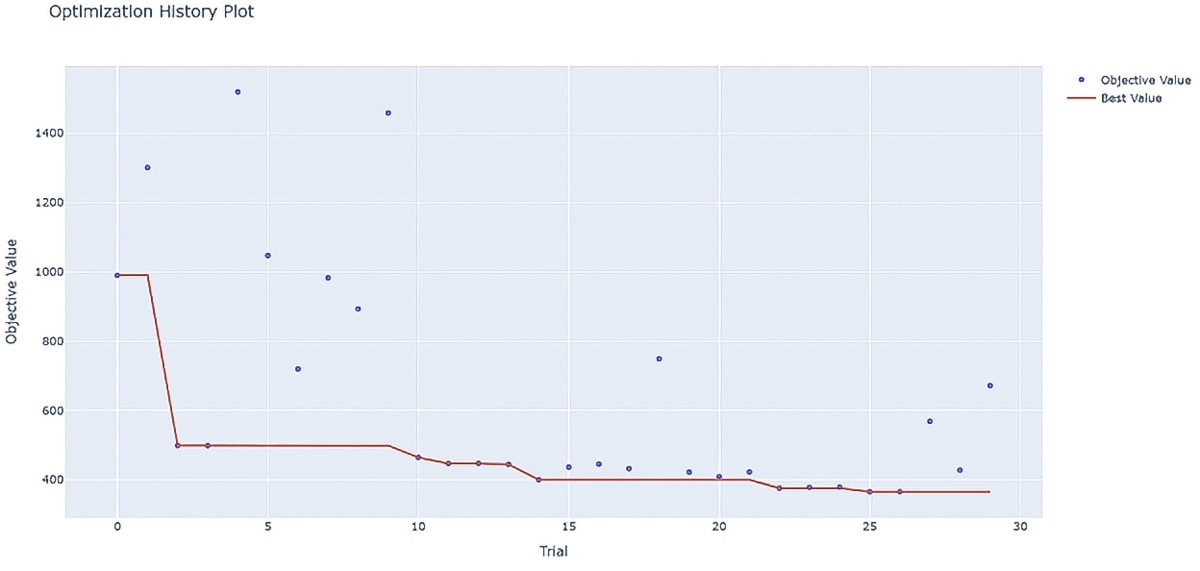
The optimization history illustrates the evolution of the objective value across iterations. The objective value represents the difference in precision between the floating-point ONNX model and the quantized model. By default, it is computed as the L2 distance between the outputs of the floating-point ONNX model and the quantized model. This plot helps visualize convergence speed, stability, and the effectiveness of the search strategy.
Image Zoom
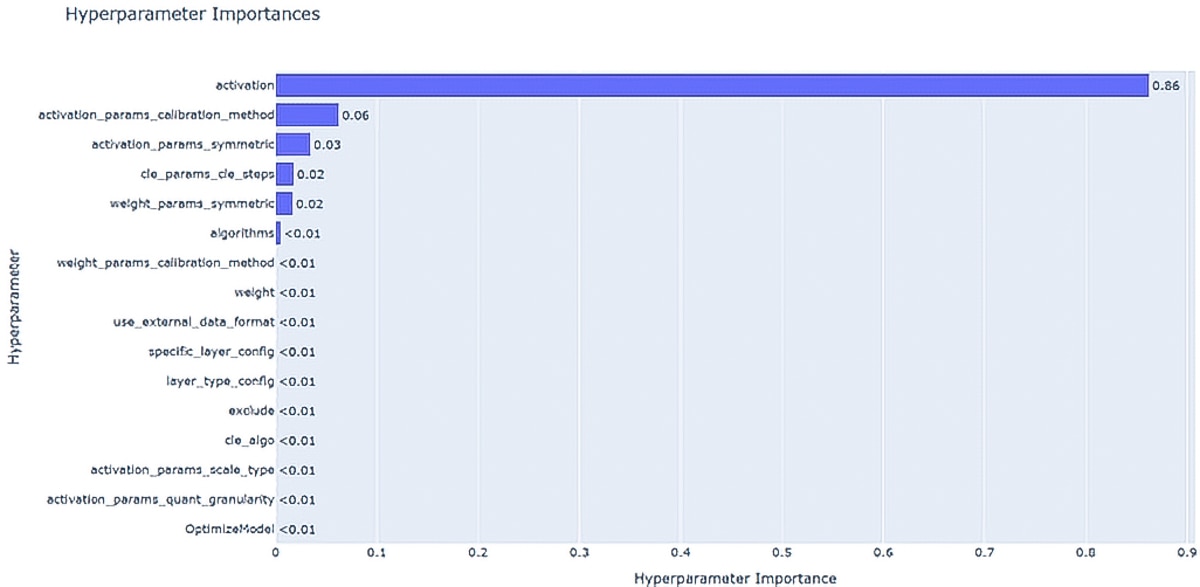
The parameter-importance plot quantifies the relative contribution of each hyperparameter to the overall performance. Higher bars indicate parameters with stronger influence on the objective metric. This visualization highlights which parameters are worth prioritizing for tuning and which have marginal impact.
Applications & Use Cases
Auto-Search supports a wide range of models and deployment scenarios.
For CNN models, the search space design can vary depending on the specific characteristics of the model structure and the task at hand. For instance, a depth-wise model may require experimentation with both per-tensor and per-channel spaces to determine the optimal configuration. Additionally, adjusting hyperparameters such as those in CLE (clipping, learning rates, etc.) may yield improved performance. In the case of object detection tasks, an auto search space design can help identify the most effective regions or components to exclude, streamlining the model’s efficiency and achieving target accuracy.
For Transformer-based models such as ViT, DeiT, BERT, and TinyLlama, their unique characteristics may benefit from specialized techniques like SmoothQuant and Layerwise Percentile. These methods can significantly enhance quantization results, optimizing both speed and accuracy for these architectures.
Auto search also plays a pivotal role in enabling mixed-precision implementations. For lightweight models, techniques like Adaround and AdaQuant are particularly valuable candidates for the auto search space design, contributing to both model performance and precision optimization.
Summary
Quark Auto-Search delivers smarter, hardware-aware quantization exploration, accelerating evaluation through multiprocessing and multi-GPU execution. It ensures a reliable, production-grade pipeline, supported by a generalizable and extensible search language. With robust checkpoints, reproducibility, and interactive visualization, Quark Auto-Search transforms quantization from a complex manual process into an automated, scalable, and enterprise-ready optimization framework that works seamlessly across all model architectures and hardware targets
Looking ahead, the framework will expand in several directions. Planned enhancements include full Quark Torch support, automatic search over QAT hyperparameters, and graph-level optimization search. In addition, ongoing efforts to improve ecosystem integration, such as collaboration with projects like Olive, will ensure broader compatibility and workflow synergy.
Acknowledgement
Sincere thanks to the AMD Quark Team and our partner teams e.g. AI Software Team for their guidance and support.


Related Blogs
-
The Importance of Open Ecosystems for Agentic AI Deployment
Enterprise agents need access to applications and data across the business. Open ecosystems help prevent AI vendor lock-in from standing in their way
July 30, 2026
-
Advancing AI 2026 Developer Sessions
See how Advancing AI 2026 brought together 2,000+ developers for workshops, technical sessions, and hands-on demos.
July 30, 2026
-
Closing the GPU Cluster Validation Gap: A Kubernetes-Native Approach with CVF — ROCm Blogs
Learn how to validate AMD GPU clusters end-to-end with CVF: hardware acceptance, mesh bandwidth, RDMA, and RCCL testing in one pipeline.
July 28, 2026
-
AMD GPU Operator v1.5.0: DRA Support, Automated GPU Node Recovery, and Expanded Kubernetes Infrastructure Control — ROCm Blogs
Discover how AMD GPU Operator v1.5.0 improves GPU scheduling, automates node recovery, and expands Kubernetes control.
July 27, 2026
-
Kimi-K3 on AMD Instinct GPUs
Day 0 support for Kimi-K3 on AMD Instinct MI355X GPUs with validated TP8 setups.
July 27, 2026
-
Attention Decode on AMD MI450 GPUs: A Gluon Kernel Optimization Guide — ROCm Blogs
Learn how to design a high-performance attention decode kernel on AMD MI450 GPUs using Gluon.
July 26, 2026
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026
-
Introducing Instella-MoE: A State-of-the-Art Fully Open Mixture-of-Experts Language Model — ROCm Blogs
Explore Instella-MoE-16B-A3B, AMD’s fully open 16B MoE LLM with 2.8B active params per token, trained on AMD Instinct™ MI300 & MI325 GPUs.
July 23, 2026







