Single Node and Distributed Inference Performance on AMD Instinct MI355X GPU
Jan 06, 2026

Introduction
The rapid growth of GenAI and LLM workloads, from agentic workflows and multi-step tool use to retrieval-augmented reasoning, demands inference infrastructure that is fast, adaptable, and highly optimized.
AMD addressed these challenges on the AMD Instinct™ MI355X GPU by combining three tightly integrated elements:
- Highly optimized and fused kernels for modern LLM primitives such as MLA attention, sparse MoE experts, and block-scale GEMMs, tuned specifically for Instinct GPUs
- A lightweight AMD inference engine that orchestrates scheduling, batching, and KV-cache management and can be run directly by users. This engine has been open-sourced here: https://github.com/ROCm/ATOM/
- High-performance distributed inference support, optimized for MoE dispatch, expert aggregation, and KV traffic across nodes
While AMD continues to invest in general-purpose inference frameworks such as vLLM and SGLang, ATOM provides the most direct path to peak MI355X GPU performance for modern reasoning and MoE-heavy workloads, which increasingly dominate frontier LLM architectures.
Over the past months, AMD have implemented numerous optimizations to improve both single-node performance and multi-node distributed inference for DeepSeek-R1 on the MI355X GPU.
Single Node Inference
DeepSeek-R1 is a reasoning-focused open sourced model that combines MLA attention with sparse MoE experts, placing heavy demands on both compute efficiency and memory bandwidth.
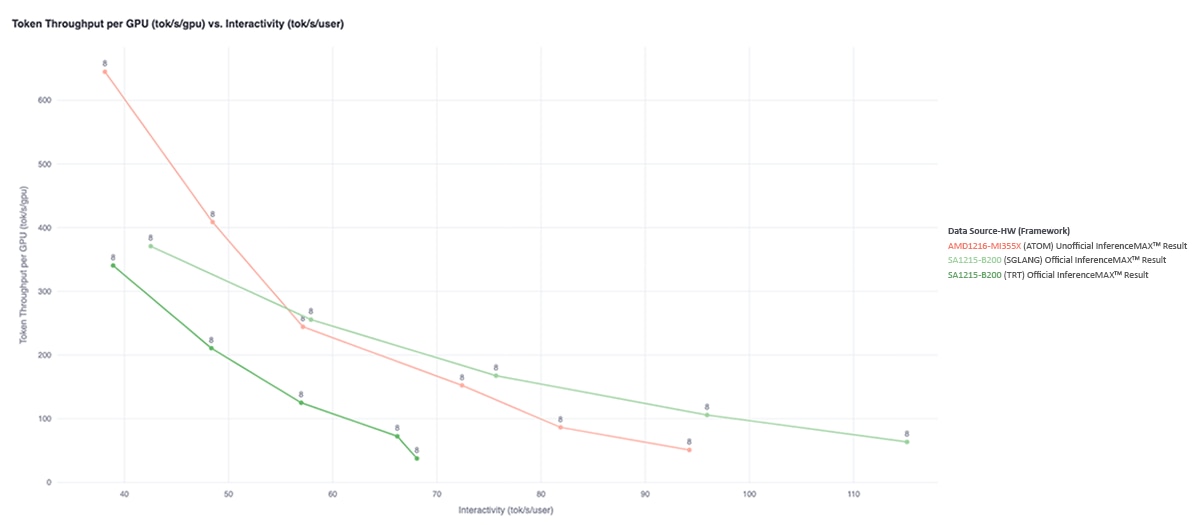
Across concurrency levels from 4 to 64, the MI355X GPU running ATOM consistently delivers strong inference performance compared to NVIDIA Blackwell B200 systems using existing inference frameworks. These results are driven by kernel-level optimizations such as fused MoE execution, MLA attention fusion, and reduced memory movement across the inference pipeline.
At higher concurrency levels (32 and 64), which are critical for minimizing cost per token in large-scale deployments, the MI355X GPU with ATOM demonstrates particularly strong throughput, matching or exceeding B200 systems running SGLang in these high-throughput regimes.
The MI355X GPU maintains this performance advantage across a range of sequence length configurations, including interactive (1K/1K), throughput-oriented (8K/1K), and long-generation (1K/8K) workloads.
Image Zoom
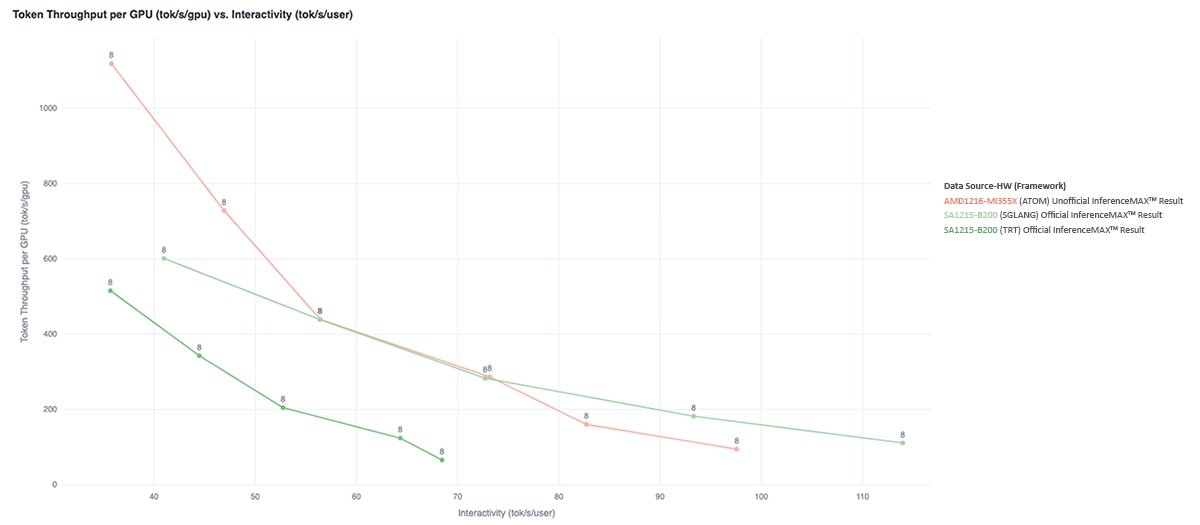
Image Zoom
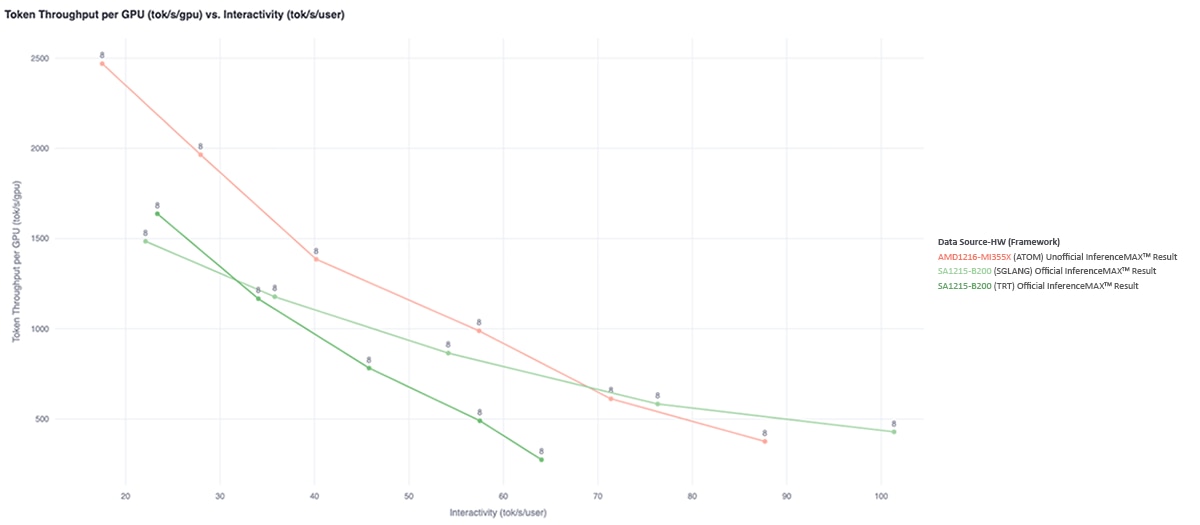
Image Zoom
Multi Node, Distributed Inference
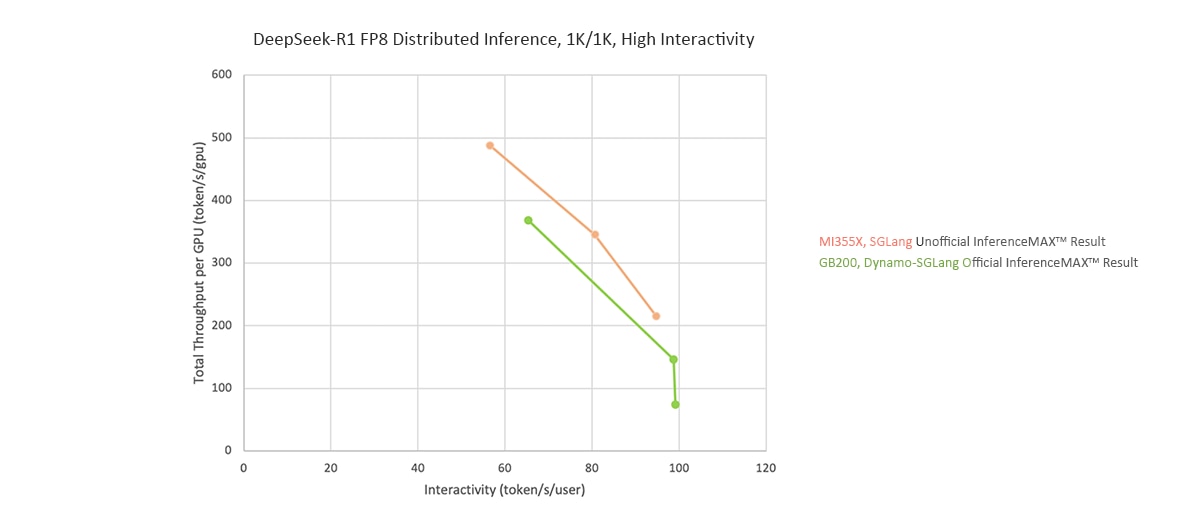
The MI355X GPU also demonstrates competitive performance in multi-node distributed inference for MoE-based workloads.
By combining optimized kernel execution with efficient distributed handling of MoE dispatch, expert aggregation, and KV-cache traffic, the MI355X GPU scales effectively across nodes for various workloads.
In latency-sensitive configurations such as the 1K/1K ISL/OSL case, the MI355X GPU using a 3-nodes 1P2D, EP8 configuration delivers higher throughput per GPU than NVL72 with Dynamo, while maintaining similar interactivity, which is beneficial for real-time, user-facing applications. More broadly, the MI355X GPU supports advanced distributed inference strategies (including expert parallelism and prefill/decode disaggregation) and scales effectively across nodes for MoE-heavy workloads by efficiently handling MoE dispatch, expert aggregation, and KV-cache traffic.
Image Zoom
What is Next?
AMD will continue optimizing existing and emerging AI workloads, including:
- Design space exploration for larger expert-parallel configurations
- Additional operator fusion for large MoE models
- Long-context inference and serving optimizations
Summary
This study demonstrates that the AMD Instinct MI355X GPU delivers competitive and often leading LLM inference performance for modern reasoning-focused MoE models.
For single-node inference, MI355X running ATOM achieves strong throughput and interactivity across a wide range of concurrency levels and sequence lengths. These results are enabled by optimized kernel execution for key LLM primitives such as MLA attention, sparse MoE experts, and block-scale GEMMs.
In distributed inference, the MI355X GPU scales efficiently for MoE workloads. In latency-sensitive configurations such as the 1K/1K ISL/OSL case, the MI355X GPU in a 1P2D EP8 configuration delivers higher throughput per GPU with similar interactivity, making it well suited for real-time inference scenarios. The platform also supports advanced parallelism strategies, including expert parallelism and prefill and decode disaggregation, enabling strong performance across both latency-oriented and throughput-oriented deployments.
All optimizations discussed in this study have been upstreamed into the open-source community. Users can reproduce and extend these results and deploy ATOM as a standalone inference engine or as a backend for frameworks such as vLLM and SGLang.
Taken together, these results show that the MI355X GPU is well positioned to support the next wave of GenAI inference workloads, where scalability, efficiency, and software openness increasingly define platform competitiveness.
Footnotes
Disclaimer:
All performance analysis conducted by AMD as of December 2025. This analysis is provided for informational purposes only and should not be relied upon to make a purchasing decision.
Footnotes
Disclaimer:
All performance analysis conducted by AMD as of December 2025. This analysis is provided for informational purposes only and should not be relied upon to make a purchasing decision.


Related Blogs
-
What to Expect at AMD Advancing AI 2026
Get a preview of AMD Advancing AI 2026, including key themes, sessions, and innovations shaping the future of AI. Discover how industry leaders are coming together to explore real-world use cases and strategies for scaling AI across the enterprise.
July 14, 2026
-
Local Image and Video Generation on AMD Ryzen™ AI Max+ Processor (Windows) — ROCm Blogs
Run ComfyUI natively on Windows on AMD Ryzen AI Max+ with ROCm 7.2.1—SDXL, Flux, and video workflows on the Radeon 8060S, no WSL.
July 13, 2026
-
LogsLop: A Tiny Summarization Tool for Enormous Log Files — ROCm Blogs
LogsLop deduplicates repetitive log lines so humans and LLMs can find failures in enormous log files.
July 13, 2026
-
Announcing the ROCm Certification Program
Build AI and HPC expertise on AMD Instinctt™ GPUs. Earn the ROCmt™ Certification with hands-on, production-ready skills.
July 13, 2026
-
Serving NVFP4 Models on AMD Instinct™ MI355 Accelerators — ROCm Blogs
Learn how to serve NVFP4 models on AMD Instinct™ MI355 using an emulation pipeline in vLLM — no format conversion needed.
July 12, 2026
-
GEAK Agent-Driven Optimization of the DeepSeekV4 MLA Kernel — ROCm Blogs
GEAK Agent accelerates DeepSeekV4 MLA kernel optimization with Triton and delivers SGLang E2E gains on AMD GPUs.
July 12, 2026
-
ZenDNN 6.0 FP16 Inference and MoE Acceleration
ZenDNN 6.0 takes the next step: FP16 functional support for AMD’s 6th Gen EPYC™ processors, MoE model optimization, and the vLLM compatibility window.
July 10, 2026
-
Fast Image Generation and Editing with SGLang Diffusion on AMD GPUs — ROCm Blogs
Serve and benchmark diffusion models for image generation and editing on AMD Instinct GPUs using SGLang Diffusion on ROCm.
July 09, 2026







