Speed is the Moat: Inference Performance on AMD GPUs
Feb 17, 2026

In the generative AI landscape, inference performance is shifting from static benchmarks to a game of "evolutionary velocity." InferenceX™ serves as a proving ground for our software stack's velocity.
AMD believes true leadership is not about "snapshot performance" tailored for specific scripts that cannot be replicated in production. We are excited to deliver breakthroughs that meet both FP8 production demands and deliver FP4 capabilities. Our progress is structural: we ensure that every breakthrough is industrialized so that open-source inference engines like vLLM and SGLang users can directly consume these top-tier performance gains.
I. Core Breakthroughs: The "Velocity" of Distributed Inference (DI)
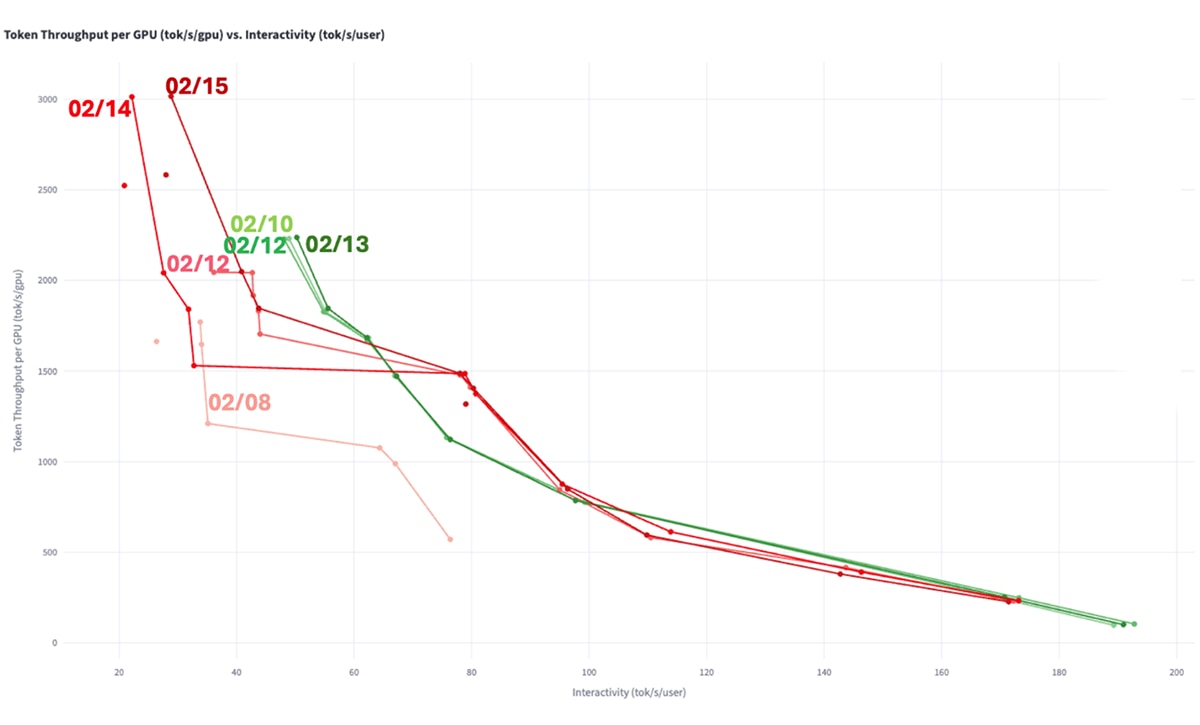
In distributed scenarios, the AMD team achieved a significant upward shift in performance curves over the past few weeks. This is a direct result of significant improvements in distributed computing and communication software.
Overcoming Communication and Prefill Bottlenecks:
For large-scale models like DeepSeek R1 (DSR1), Distributed Inference (DI) efficiency determines deployment economics.
- Prefill Bottleneck Removal: Prefill was the primary limiter of end-to-end distributed inference performance. By approximately doubling prefill throughput through parallelism restructuring, we increased total DSR1 FP8 8K/1K distributed throughput per GPU from 2K to 3K within one week, exceeding the published B200 baseline of ~2.2K
- Communication Overlap: By leveraging "communication bubbles" to overlap with computation, we achieved total parity or outperformance against competitors in medium-to-high interactivity zones.
II. MoRI: The Engine of Low-Latency Connectivity
To achieve these distributed breakthroughs, we have engineered MoRI (Modular RDMA Interface). It serves as the architectural backbone for superior communication performance and minimal latency
- Expert Parallelism (MORI-EP): Purpose-built for large scale MoE (Mixture-of-Experts) models like DeepSeek-R1, MORI-EP offers high performance expert dispatch and combine kernels. Recent kernel-level optimizations have reduced latency by up to 82%, driving HBM, XGMI, and RDMA communication overheads close to their theoretical upbound.
- Adaptive Kernel Selection: MoRI provides an automatic adaptive switching mechanism. High-throughput kernels are used for prefill and high-concurrency decode, while low-latency kernels are activated for low-concurrency scenarios. Pre-tuned launch configurations ensure maximal CU utilization.
- Unified Traffic Control: Both the KV transfer engine (MoRI-IO) and MoE expert parallelism are built the top of common MoRI primitives, enabling unified network priority management. This enables joint optimization of KV transfer and token dispatch traffic, actively promoting coordinated data movement and sustained network efficiency.
With the above optimization and tuning, the distributed inference performance on AMD Instinct™ MI355X GPUs for DeepSeek FP8 has been drastically improved within 7 days, on both 1K/1K and 8K/1K cases in InferenceX v2. The rate of improvement underscores the pace at which the stack is evolving.
Image Zoom
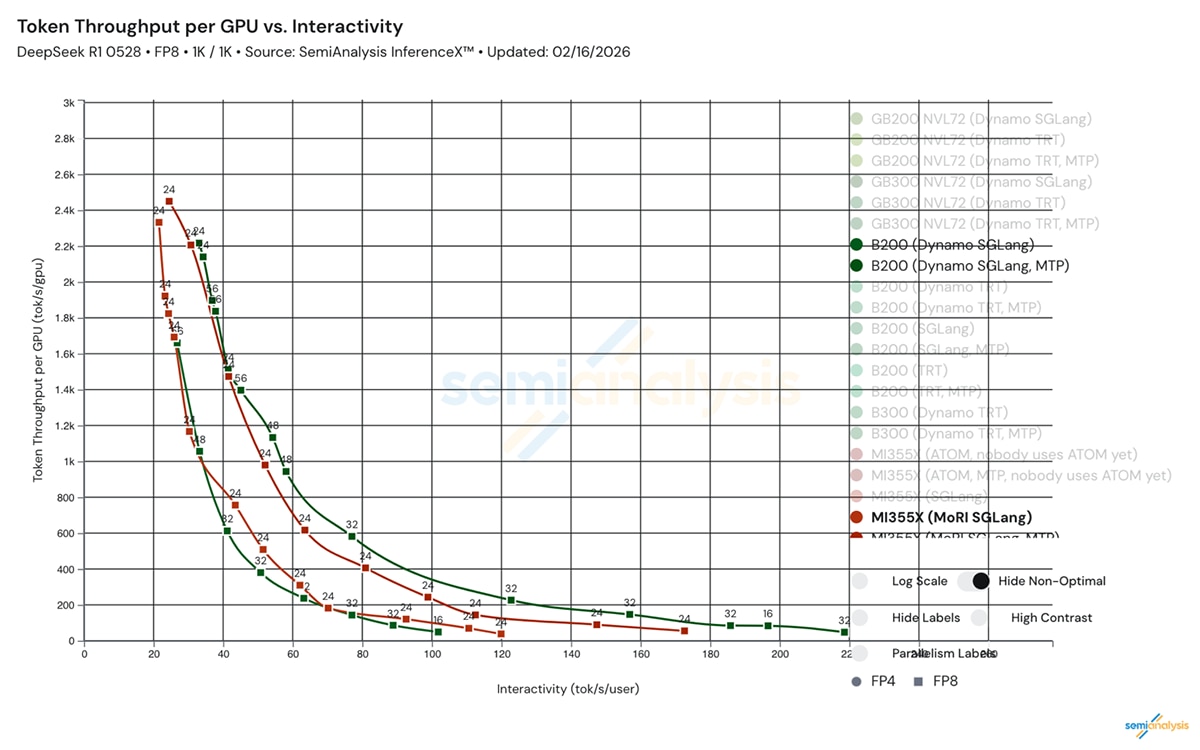
Image Zoom
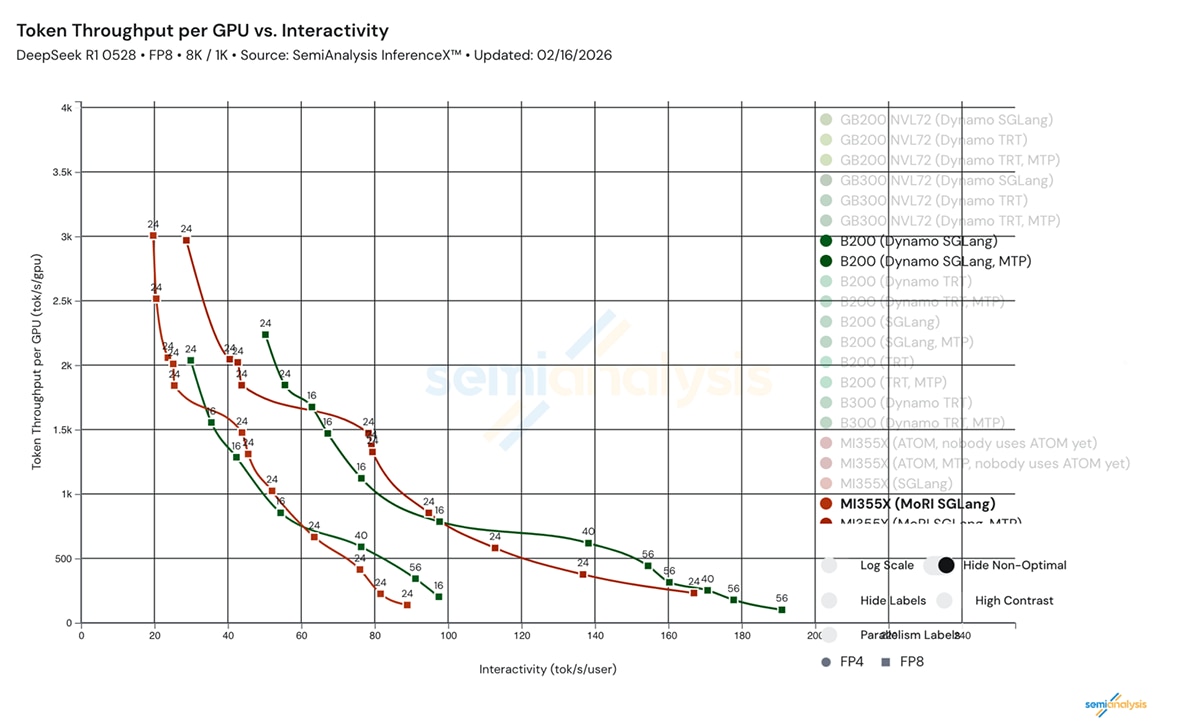
Image Zoom
III. Single Node and MTP: Defining New Interactivity Standards
Single-node performance is the bedrock of inference, while Multi-Token Prediction (MTP) is a key feature for enhancing user experience.
Single Node Performance
Through kernel fusion and targeted optimizations within the AITER library, we improve compute efficiency and overall hardware utilization in single-node configurations. In representative large-model workloads, our single-node solution delivers a 1.08x to 1.2x throughput uplift over baseline framework configurations. These gains have been validated in customer-facing PoCs, demonstrating practical performance improvements in real deployment environments.
For example, our collaboration on Qwen3 latency optimization illustrates how coordinated stack and hardware work translates into measurable performance gains.
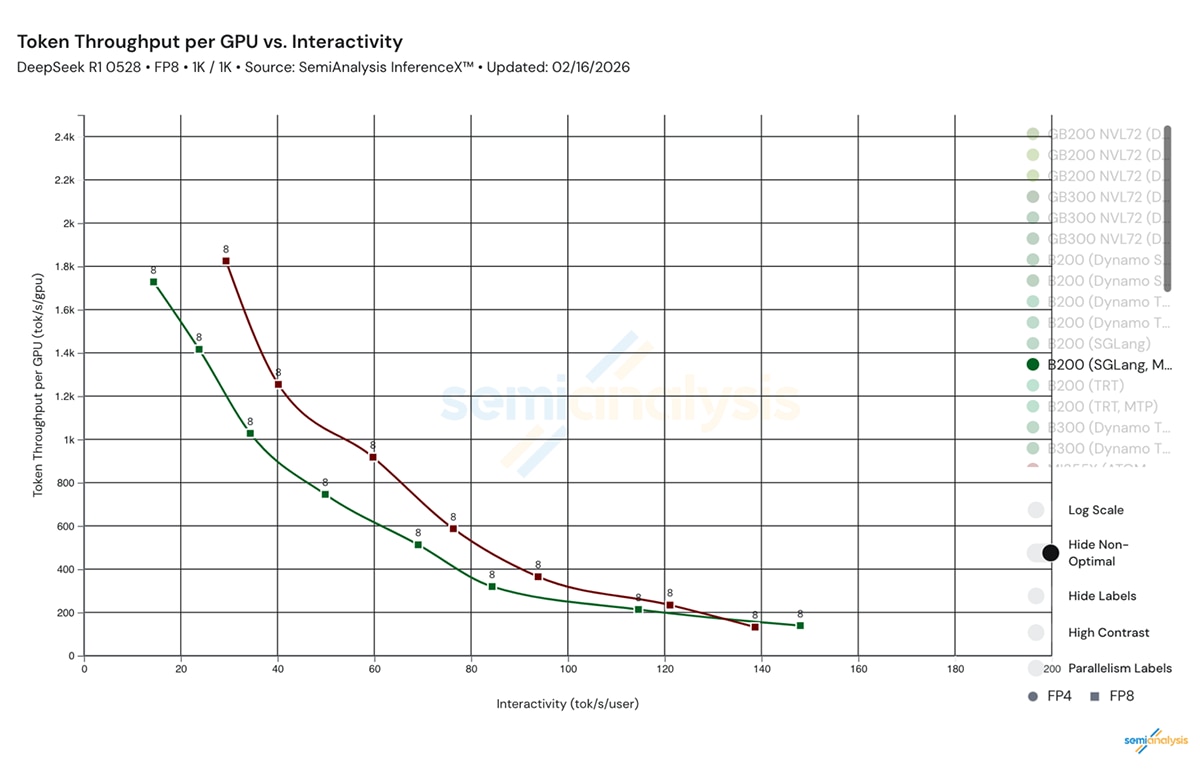
MTP: A Generational Leap in Interactivity
We leverage Multi-Token Prediction (MTP) to reduce effective decode latency while maintaining model accuracy. In our testing, the MI355X GPUs with MTP delivers higher per-GPU throughput than B200 across the evaluated interactivity range.
Image Zoom
IV. From Day-0 Support to Optimized Performance
Our objective is clear: enable new models on Day-0 and continuously improve performance thereafter. An approach reflected in our recent Day-0 support for Qwen3 Coder Next on AMD Instinct™ GPUs.
We integrate directly with vLLM and SGLang to ensure immediate compatibility with standard open-source workflows, while advancing kernel, communication, and parallelism optimizations across the stack. This allows customers to deploy immediately and benefit from ongoing performance gains as the software evolves.
In distributed serving, architecture and workload characteristics both matter. Rack-scale systems can offer advantages in certain regimes, while higher-interactivity serving emphasizes latency sensitivity. Our focus is to deliver strong, production-ready performance across the full interactivity spectrum.
V. Roadmap: Ecosystem Ubiquity and Native Integration Strategy
AMD is committed to a Native Integration strategy that prioritizes community alignment over proprietary fragmentation. Our roadmap includes deep integration of ATOM’s core capabilities into leading open-source frameworks, ensuring customers can access peak AMD Instinct GPU performance through standard ecosystem tools.
1. Dual-Track Integration: Performance and Ecosystem Alignment
Our strategy combines upstream alignment with rapid optimization:
- vLLM Integration: We align with upstream vLLM and use an Out-of-Tree (OOT) path to deliver optimized kernels without modifying core code. This preserves ecosystem compatibility while enabling Day-0 performance. The vLLM+ATOM integration delivers up to 1.2x throughput uplift over vanilla vLLM
- SGLang Alignment: ATOM serves as a high-velocity backend for new model and hardware launches, with optimized kernels integrated directly into SGLang. Functionality and accuracy are validated, with ongoing benchmarking to ensure seamless performance
2. H1 2026 Feature Roadmap: From Sprint to Scale
We are executing a phased rollout to move from technical proof-of-concepts to production-ready ecosystem ubiquity, making our FP4, disaggregation, and WideEP gains fully composable and ready for large-scale deployment.
Category |
2026 Q1: Foundation & Reach |
2026 Q2: Product Ready |
Milestones |
Functional OOT integration for vLLM/SGLang; Support for critical models (Qwen MoE 235B, DeepSeek V3/V3.2). |
Full production readiness; Zero-overhead parity with standalone ATOM performance. |
Key Features |
Compatibility with TP/EP parallelism, Chunked Prefill, Prefix Cache, and Sparse/Radix Attention. FP4 performance. |
Expansion to DP/SP/CP/PP parallelism; Support for MTP (1/2/3) and Multimodality preprocessors. |
Model Scope |
Critical LLM models: Qwen Dense, Qwen MoE (235B), DeepSeek V3/V3.2, Kimi-K2. |
Extension to VLM (Vision-Language Models); Qwen3 Next and Kimi-K2.5 (FP8/FP4); DeepSeek V4. |
Conclusion
Speed is our moat. Our software iteration velocity is high, and we will continue advancing performance week over week through sustained execution across the inference stack.
This progress is part of a broader execution roadmap. Instinct MI450 Series GPUs and Helios are doing great in the labs and we are actively going through our hardware and software validation steps. We remain on track for second-half production ramp and initial customer deployments.



Related Blogs
-
The Importance of Open Ecosystems for Agentic AI Deployment
Enterprise agents need access to applications and data across the business. Open ecosystems help prevent AI vendor lock-in from standing in their way
July 30, 2026
-
Advancing AI 2026 Developer Sessions
See how Advancing AI 2026 brought together 2,000+ developers for workshops, technical sessions, and hands-on demos.
July 30, 2026
-
Closing the GPU Cluster Validation Gap: A Kubernetes-Native Approach with CVF — ROCm Blogs
Learn how to validate AMD GPU clusters end-to-end with CVF: hardware acceptance, mesh bandwidth, RDMA, and RCCL testing in one pipeline.
July 28, 2026
-
AMD GPU Operator v1.5.0: DRA Support, Automated GPU Node Recovery, and Expanded Kubernetes Infrastructure Control — ROCm Blogs
Discover how AMD GPU Operator v1.5.0 improves GPU scheduling, automates node recovery, and expands Kubernetes control.
July 27, 2026
-
Kimi-K3 on AMD Instinct GPUs
Day 0 support for Kimi-K3 on AMD Instinct MI355X GPUs with validated TP8 setups.
July 27, 2026
-
Attention Decode on AMD MI450 GPUs: A Gluon Kernel Optimization Guide — ROCm Blogs
Learn how to design a high-performance attention decode kernel on AMD MI450 GPUs using Gluon.
July 26, 2026
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026
-
Introducing Instella-MoE: A State-of-the-Art Fully Open Mixture-of-Experts Language Model — ROCm Blogs
Explore Instella-MoE-16B-A3B, AMD’s fully open 16B MoE LLM with 2.8B active params per token, trained on AMD Instinct™ MI300 & MI325 GPUs.
July 23, 2026







