Super Resolution Acceleration on Ryzen AI NPU
Jan 07, 2026

In recent years, the demand for high-resolution images has surged, driven not only by advances in digital photography but especially by real-time services such as online meetings, online games, and streaming video, where visual clarity directly impacts usability and user experience. In these bandwidth- and latency-constrained scenarios, super-resolution is not just beneficial but often necessary: it reconstructs sharper faces and text in video calls from low-bitrate feeds, restores fine textures and distant details in cloud-gaming streams, and delivers higher perceived quality for videos at lower bitrates or on high‑density displays. By effectively trading compute for bandwidth, super-resolution helps platforms maintain quality under fluctuating network conditions and device limitations.
However, as input resolutions of the model grow, the memory bandwidth costs of super-resolution also escalate. High-resolution images often require substantial memory bandwidth to sustain the transfer of pixel data during processing. Traditional approaches to super-resolution typically involve scaling the entire image, leading to excessive memory access that can bottleneck real-time performance. This overhead can manifest in increased latency and reduced throughput. Consequently, optimizing the performance of super-resolution algorithms for high-resolution inputs is a pressing concern that researchers and practitioners must address.
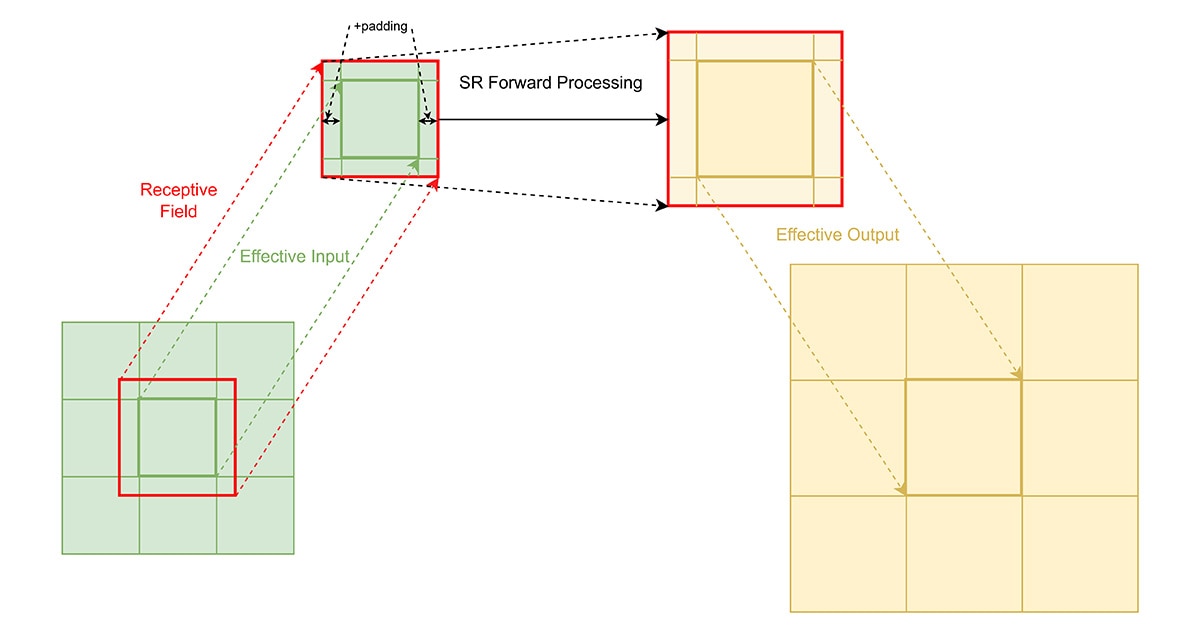
One promising strategy to tackle these challenges is the implementation of a tiling approach. By breaking down high-resolution images into smaller, manageable tiles, we can significantly reduce the memory bandwidth required required for data transfer, while keeping the output exactly the same as the full model, as shown in Fig. 1. This tiling strategy allows for localized processing of image patches, which not only minimizes the amount of data accessed at any one time but also can take advantage of spatial locality in memory access patterns. Furthermore, tiling can enhance the efficiency of parallel computing architectures, as individual tiles can be processed concurrently, thereby accelerating overall processing times.
Image Zoom
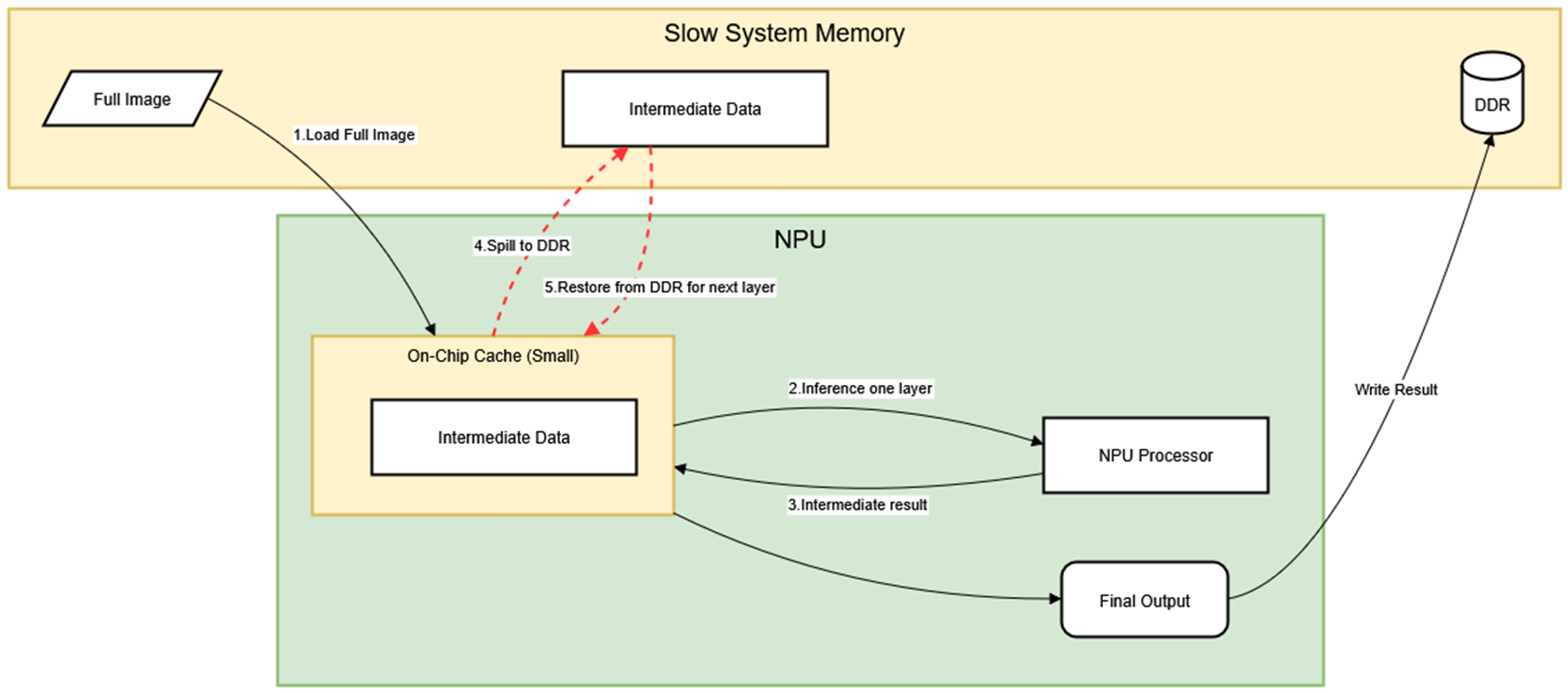
Image Zoom
Optimizing the Inference Pipeline
Compiler-aware Image Tiling
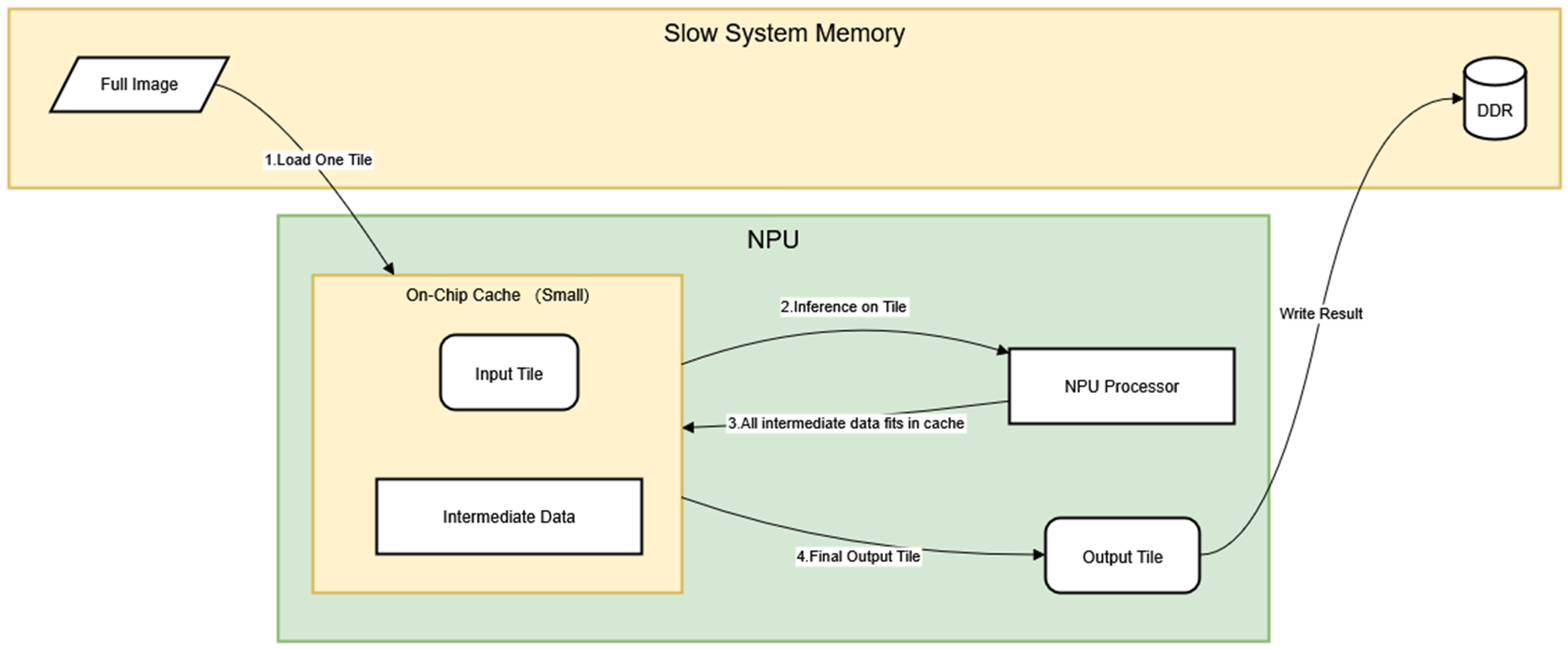
Traditional full-frame processing forces intermediate data to spill into DDR due to cache capacity constraints, creating significant bandwidth bottlenecks. Rather than processing entire high-resolution frames at once, we split input frames into smaller tiles along different dimensions. This strategy keeps the entire computational working set (input tiles, intermediate activations, and output patches) resident in fast on-chip memory throughout the inference pipeline.
The input frame is divided into a grid of smaller image patches that can be processed independently by the SR model. This spatial decomposition transforms a memory-intensive operation on large images into a series of cache-friendly computations on smaller data blocks. Each tile maintains sufficient overlap with neighboring tiles to ensure that no extra accuracy loss at tile boundaries. By reducing the input tensor size in this way, we dramatically shrink the footprint of intermediate activations and feature maps generated during model inference.
This cache-centric approach delivers substantial throughput improvements by minimizing memory access latency and maximizing computational efficiency. The NPU can maintain peak utilization while processing each tile, as all required data remains accessible within the high-bandwidth cache hierarchy. The result is a more predictable and consistently high-performance inference pipeline that scales effectively across varying input resolutions.
Compiler Optimization
One of the key enablers of efficient SR model inference on NPU is the compiler in the Ryzen AI software stack (https://www.amd.com/en/developer/resources/ryzen-ai-software.html), whose ability is to fuse operations across tiles, thereby reducing memory access overhead and improving execution throughput.
The NPU compiler supports L1-level AIE tile fusion, which allows operations within a single tile to be tightly coupled and executed with minimal latency. However, L2-level fusion, which spans across multiple tiles, is typically constrained by the size of the input image. Large images may exceed the available L2 memory, preventing full fusion and leading to fragmented execution and increased control overhead.
By applying image tiling, we effectively reduce the size of each input patch, making it feasible for the compiler to perform full L2 fusion across the entire inference pipeline for a single tile. This not only ensures that all intermediate tensors and activations remain within the L2 memory boundary, but also enables the compiler to generate highly optimized execution graphs with fewer control instructions.
In a single patch inference scenario, the reduced control flow complexity allows the software overhead to be hidden behind the hardware and software pipeline, resulting in a more streamlined and efficient execution. The compiler can schedule operations more aggressively, leveraging the NPU’s parallelism and memory hierarchy to maintain high throughput and low latency.
This compiler-aware tiling strategy is crucial for unlocking the full potential of NPU hardware, especially when scaling SR models to high-resolution inputs. It ensures that each tile benefits from optimal fusion and minimal software intervention, contributing to a robust and scalable acceleration pipeline.
Zero-copy Runtime Approach
When we split input images into tiles, each tile is handled by an individual runner which runs on NPU device, the runner takes tile image as its input buffer. If we are given an entire image buffer, the base address of input buffer for each tile buffer is calculated.
Another point to consider is that an image is divided into multiple tiles in memory, and the memory for each tile is fragmented rather than contiguous. That means the runner must support taking non-contiguous memory as its input buffer to avoid memory copy, which we call stride access. The low-level runtime which the runner is based on can calculate the DDR address according to the stride parameter passed before accessing it. Therefore, all that is required for the inference is the correct base address of the tile buffer.
When a pre-allocated image buffer in memory is being processed:
- Instantiate a device buffer-object referencing to the image buffer.
- Do the tiling and calculate the offset in buffer-object for each tile.
- Create sub-buffer-object for each tile.
The runners take associate sub-buffer-object as its input and start to process the tile.
Our library also allows users to specify the buffers by themselves instead of copying the data into a designated address. So, for OS level’s memory sharing. We can directly use pre-allocated buffers for NPU processing without any extra copies. Here is an example to use D3D resources as i/o buffers:
// Vector to store D3D resources
std::vector<D3DResource> d3dInputs;
std::vector<D3DResource> d3dOutputs;
// Vector to be used by NPU
std::vector<gaming_sr::OrtBuf> inputs;
std::vector<gaming_sr::OrtBuf> outputs;
// Create D3D resources for all tiles
for (size_t tile_idx = 0; tile_idx < num_tiles; ++tile_idx) {
D3DResource inputResource = CreateD3DBuffer(input_size);
D3DResource outputResource = CreateD3DBuffer(output_size);
d3dInputs.push_back(std::move(inputResource));
d3dOutputs.push_back(std::move(outputResource));
// NPU directly uses shared buffers from D3D resources
inputs.push_back({inputResource.mem.get(), input_size});
outputs.push_back({outputResource.mem.get(), output_size});
Demo
To make these ideas concrete, we’ve packaged a sample application (tile_sample.zip, following README to run the application) that demonstrates the end-to-end impact of tiling on high-resolution super-resolution workloads. The requirements to run the application are as follows.
Devices: Device with AMD NPU & GPU
OS System: Windows 11
Software Dependency: OpenCV 4.10, NPU Driver (32.0.203.280), GPU Driver
The app lets you toggle between full-frame and tile-based inferences. The following table shows the latency breakdowns.
|
E2E Latency(ms) |
Full model |
35.24 |
Tiling model |
Additional Resources
1. AMD XDNA NPU in Ryzen AI Processors - https://ieeexplore.ieee.org/document/10592049


Related Blogs
-
Understanding Attention Algorithms and Their Backends for Image and Video Generation — ROCm Blogs
Practical guide to attention backends in ComfyUI on AMD describing how to optimize performance, memory, and stability with the right configuration.
July 19, 2026
-
How Pixar and AMD Scale Rendering for Artists
See how Pixar, Ranch Computing, and AMD brought production-grade RenderMan workflows, mentorship, and cloud rendering to creators worldwide.
July 17, 2026
-
Efficient Hyperparameter Optimization for Autonomous Driving Models with AMD Instinct GPU Partitioning — ROCm Blogs
Accelerate HPO for autonomous driving models using AMD MI300X GPU partitioning for higher throughput, efficiency, and parallelism.
July 07, 2026
-
AMD Ryzen™ AI Halo Now Available at Micro Center
Ryzen AI Halo launches at Micro Center, powering agentic PCs for developers building larger, next-generation local AI applications.
July 06, 2026
-
AMD Named Current Company to Beat in Gartner® AI Vendor Race
In a new report, Gartner positions AMD as the current front-runner for enterprise AI server CPUs.
June 24, 2026
-
A Practical Guide to Running LLMs on AMD Radeon™ GPUs — ROCm Blogs
This guide describes how to run LLMs on AMD Radeon™ GPUs using a range of partner frameworks, tools, and runtimes, with step-by-step setup instructions and performance optimization tips.
June 18, 2026
-
AI Across Industries: How AMD Technologies Are Powering the Next Wave of Enterprise Transformation
AI is reshaping every industry. Explore how leading enterprises are using AMD-powered AI infrastructure to accelerate innovation, improve efficiency, and drive business transformation.
June 18, 2026
-
AMD Spartan™ UltraScale+™ SU200P FPGA Now in Production
Now in production. AMD Spartan™ UltraScale+™ SU200P FPGA with high I/O, low power, and state-of-the-art security features.
June 15, 2026







