[How-To] Running Optimized Automatic1111 Stable Diffusion WebUI on AMD GPUs
Aug 18, 2023

[UPDATE]: TheAutomatic1111-directMLbranch now supports Microsoft Olive under the Automatic1111 WebUI interface, which allows for generating optimized models and running them all under the Automatic1111 WebUI, without a separatebranch needed to optimize for AMD platforms. The updated blog to run Stable Diffusion Automatic1111 with Olive Optimizations is available here -UPDATED HOW-TO GUIDE
Prepared by Hisham Chowdhury (AMD),Lucas Neves (AMD), andJustin Stoecker (Microsoft)
Did you know you can enable Stable Diffusion with Microsoft Olive under Automatic1111(Xformer) to get a significant speedup via Microsoft DirectML on Windows? Microsoft and AMD have been working together to optimize the Olive path on AMD hardware, accelerated via the Microsoft DirectML platform API and the AMD User Mode Driver’s ML (Machine Learning) layer for DirectML allowing users access to the power of the AMD GPU’s AI (Artificial Intelligence) capabilities.
1. Prerequisites
- Installed Git (Git for Windows)
- Installed Anaconda/Miniconda (Miniconda for Windows)
- Ensure Anaconda/Miniconda directory is added to PATH
- Platform having AMD Graphics Processing Units (GPU)
- Driver: AMD Software: Adrenalin Edition™ 23.7.2 or newer (https://www.amd.com/en/support)
2. Overview of Microsoft Olive
Microsoft Olive is a Python tool that can be used to convert, optimize, quantize, and auto-tune models for optimal inference performance with ONNX Runtime execution providers like DirectML. Olive greatly simplifies model processing by providing a single toolchain to compose optimization techniques, which is especially important with more complex models like Stable Diffusion that are sensitive to the ordering of optimization techniques. The DirectML sample for Stable Diffusion applies the following techniques:
- Model conversion: translates the base models from PyTorch to ONNX.
- Transformer graph optimization: fuses subgraphs into multi-head attention operators and eliminating inefficient from conversion.
- Quantization: converts most layers from FP32 to FP16 to reduce the model's GPU memory footprint and improve performance.
Combined, the above optimizations enable DirectML to leverage AMD GPUs for greatly improved performance when performing inference with transformer models like Stable Diffusion.
3. Generate Optimized Stable Diffusion Models using Microsoft Olive
Create Optimized Model
(Following the instruction from Olive, we can generate optimized Stable Diffusion model using Olive)
- Open Anaconda/Miniconda Terminal
- Create a new environment by sequentially entering the following commands into the terminal, followed by the enter key. Important to note that Python 3.9 is required.
- conda create --name olive python=3.9
- conda activate olive
- pip install olive-ai[directml]==0.2.1
- git clone https://github.com/microsoft/olive --branch v0.2.1
- cd olive\examples\directml\stable_diffusion
- pip install -r requirements.txt
- pip install pydantic==1.10.12
- Generate an ONNX model and optimize it for run-time. This may take a long time.
- python stable_diffusion.py --optimize
The optimized model will be stored at the following directory, keep this open for later: olive\examples\directml\stable_diffusion\models\optimized\runwayml.The model folder will be called “stable-diffusion-v1-5”. Use the following command to see what other models are supported:python stable_diffusion.py –help
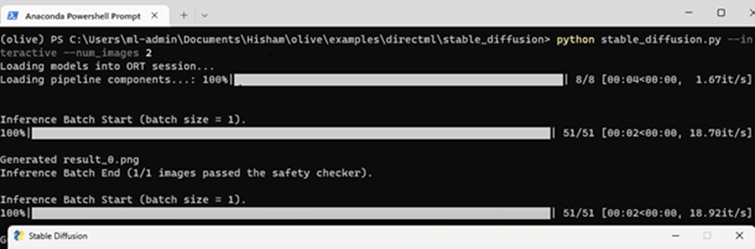
To Test the Optimized Model
- To test the optimized model, run the following command:
- python stable_diffusion.py --interactive --num_images 2
4. Install and Run Automatic1111 Stable Diffusion WebUI
Following the instructions here, install Automatic1111 Stable Diffusion WebUI without the optimized model. It will be using the default unoptimized PyTorch path. Enter the following commands sequentially into a new terminal window.
- Open Anaconda/Miniconda Terminal.
- Enter the following commands in the terminal, followed by the enter key, to install Automatic1111 WebUI
- conda create --name Automatic1111 python=3.10.6
- conda activate Automatic1111
- git clone https://github.com/lshqqytiger/stable-diffusion-webui-directml
- cd stable-diffusion-webui-directml
- git submodule update --init --recursive
- webui-user.bat
- CTRL+CLICK on the URL following "Running on local URL:" to run the WebUI
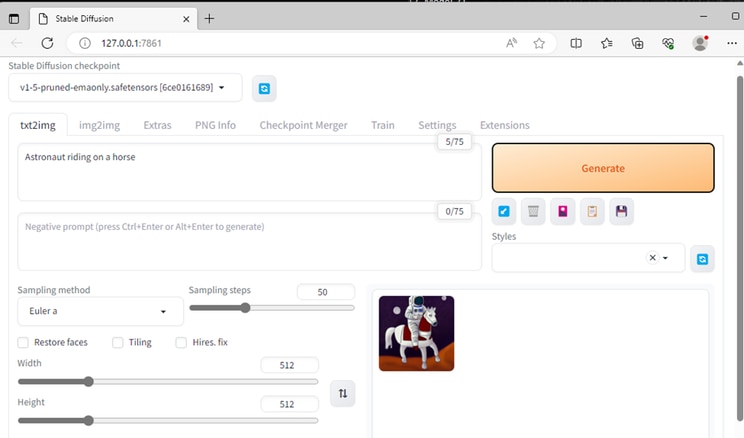
5. Enable Olive Optimized Path on AMD Radeon
Integrate the optimized model
- Copy generated optimized model (the “stable-diffusion-v1-5” folder) from Optimized Modelfolderinto the directory stable-diffusion-webui-directml\models\ONNX. The ONNX folder may need to be created for some users.
Run the Automatic1111 WebUI with the Optimized Model
- Launch a new Anaconda/Miniconda terminal window
- Navigate to the directory with the webui.bat and enter the following command to run the WebUI with the ONNX path and DirectML. This will be using the optimized model we created in section 3.
- webui.bat --onnx --backend directml
- CTRL+CLICK on the URL following "Running on local URL:" to run the WebUI
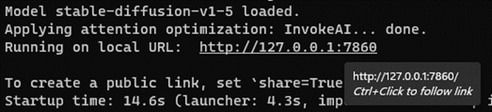
4. Pick “stable-diffusion-v1-5” from dropdown

6. Conclusion
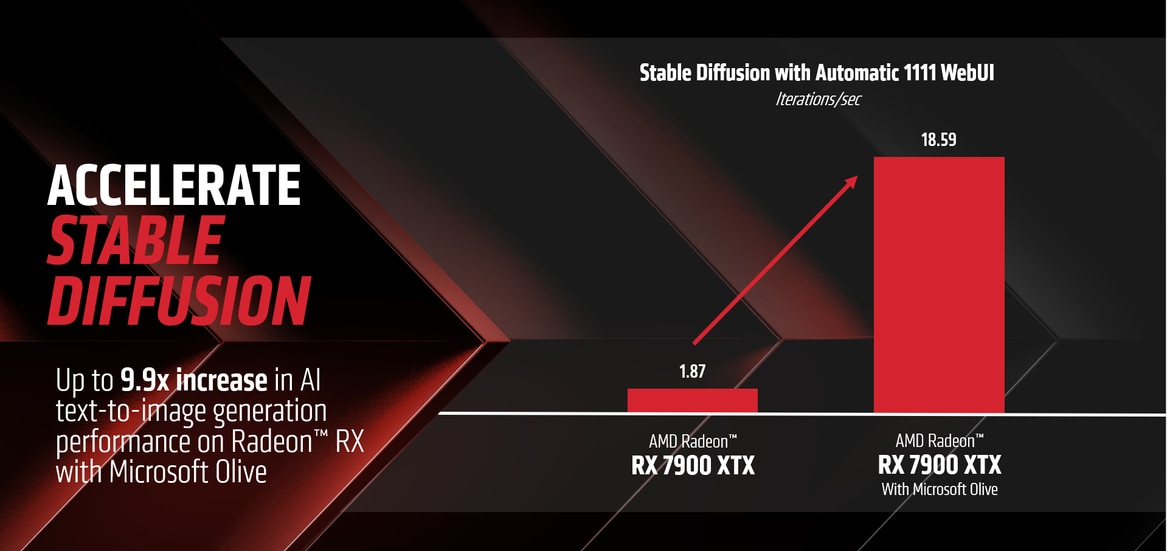
Running on the default PyTorch path, the AMD Radeon RX 7900 XTX delivers 1.87 iterations/second.
Running on the optimized model with Microsoft Olive, the AMD Radeon RX 7900 XTX delivers 18.59 iterations/second.

End Result is up to 9.9X improvement to performance on AMD Radeon™ RX 7900 XTX.


Related Blogs
-
Open Standards, Real Solutions: AMD at SIGGRAPH 2026
AMD heads to DigiPro and SIGGRAPH 2026 to discuss open standards, production technology, and the fine art of Gaussian splatting.
July 17, 2026
-
FastFlowLM Joins AMD to Advance AI Inference
The FastFlowLM team has joined AMD, marking another key step in AMD’s strategy to advance AI performance and efficiency across the stack.
July 17, 2026
-
From Pixels to Predictions: Edge AI Pipeline Acceleration
Learn how AMD Vitis™ AI & AMD Vitis Video Analytics SDK (VVAS) use Gstreamer to build real-time Edge AI pipelines on AMD Versal™ AI Edge Series Gen 2.
July 16, 2026
-
Running Cloud Agents? Your Most Important Upgrade Could be an AMD Zen 5 CPU
As agents begin navigating applications, coordinating tools and completing real work, the local CPU is becoming a critical part of the AI execution pipeline.
July 16, 2026
-
Multi-Accelerator Support for AIMs and AMD Solution Blueprints — ROCm Blogs
Deploy and run AIMs and AMD Solution Blueprints across AMD Instinct™ GPUs, AMD EPYC™ CPUs, and AMD Radeon™ GPUs
July 15, 2026
-
ROCm 7.14: TheRock Goes Production and Expands AMD’s AI Software Platform — ROCm Blogs
Explore what's new in ROCm 7.14: TheRock goes production, expanded hardware support, stronger AI frameworks, and enhanced profiling tools.
July 14, 2026
-
From Vector Search to Agentic RAG: Building an Enterprise Research Analyst with hipVS — ROCm Blogs
Learn how to build an agentic RAG research assistant using hipVS GPU-accelerated vector search on AMD Instinct GPUs, with multi-query decomposition, parallel retrieval, and cited sources synthesis.
July 14, 2026
-
When a Faster Kernel Doesn’t Speed Up Serving: Profiling FP8 KV Cache on AMD Instinct MI308X — ROCm Blogs
Learn how a 34% faster FP8 KV cache kernel delivered 0% E2E speedup, and how profiling attribution exposed the hidden dtype-cast cost on MI308X.
July 14, 2026








Footnotes
7. Disclaimers & Footnotes
Links to third-party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites, and no endorsement is implied. GD-98Testing conducted by AMD as of August 15th, 2023, on a test system configured with a Ryzen9 7950X 3D(4.2GHz) CPU, 32GB DDR5, Radeon RX 7900XTX GPU, Windows 11 Pro, with AMD Software: Adrenalin Edition 23.7.2, using the application Stable Diffusion 1.5 with Microsoft Olive under Automatic 1111 vs. Default Automatic 1111. Performance may vary. System manufacturers may vary configurations, yielding different results. RS-587The information presented in this document is for informational purposes only and may contain technical inaccuracies, omissions, and typographical errors. The information contained herein is subject to change and may be rendered inaccurate for many reasons, including but not limited to product and roadmap changes, component and motherboard version changes, new model and/or product releases, product differences between differing manufacturers, software changes, BIOS flashes, firmware upgrades, or the like. Any computer system has risks of security vulnerabilities that cannot be completely prevented or mitigated. AMD assumes no obligation to update or otherwise correct or revise this information. However, AMD reserves the right to revise this information and to make changes from time to time to the content hereof without obligation of AMD to notify any person of such revisions or changes. GD-18. THIS INFORMATION IS PROVIDED ‘AS IS.” AMD MAKES NO REPRESENTATIONS OR WARRANTIES WITH RESPECT TO THE CONTENTS HEREOF AND ASSUMES NO RESPONSIBILITY FOR ANY INACCURACIES, ERRORS, OR OMISSIONS THAT MAY APPEAR IN THIS INFORMATION. AMD SPECIFICALLY DISCLAIMS ANY IMPLIED WARRANTIES OF NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR ANY PARTICULAR PURPOSE. IN NO EVENT WILL AMD BE LIABLE TO ANY PERSON FOR ANY RELIANCE, DIRECT, INDIRECT, SPECIAL, OR OTHER CONSEQUENTIAL DAMAGES ARISING FROM THE USE OF ANY INFORMATION CONTAINED HEREIN, EVEN IF AMD IS EXPRESSLY ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.Copyright 2023 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, [insert all other AMD trademarks used in the material IN ALPHABETICAL ORDER here per AMD's Guidelines on Using Trademark Notice and Attribution] and combinations thereof are trademarks of Advanced Micro Devices, Inc. Microsoft is a registered trademark of Microsoft Corporation in the US and/or other countries. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners.
Footnotes
7. Disclaimers & Footnotes
Links to third-party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites, and no endorsement is implied. GD-98Testing conducted by AMD as of August 15th, 2023, on a test system configured with a Ryzen9 7950X 3D(4.2GHz) CPU, 32GB DDR5, Radeon RX 7900XTX GPU, Windows 11 Pro, with AMD Software: Adrenalin Edition 23.7.2, using the application Stable Diffusion 1.5 with Microsoft Olive under Automatic 1111 vs. Default Automatic 1111. Performance may vary. System manufacturers may vary configurations, yielding different results. RS-587The information presented in this document is for informational purposes only and may contain technical inaccuracies, omissions, and typographical errors. The information contained herein is subject to change and may be rendered inaccurate for many reasons, including but not limited to product and roadmap changes, component and motherboard version changes, new model and/or product releases, product differences between differing manufacturers, software changes, BIOS flashes, firmware upgrades, or the like. Any computer system has risks of security vulnerabilities that cannot be completely prevented or mitigated. AMD assumes no obligation to update or otherwise correct or revise this information. However, AMD reserves the right to revise this information and to make changes from time to time to the content hereof without obligation of AMD to notify any person of such revisions or changes. GD-18. THIS INFORMATION IS PROVIDED ‘AS IS.” AMD MAKES NO REPRESENTATIONS OR WARRANTIES WITH RESPECT TO THE CONTENTS HEREOF AND ASSUMES NO RESPONSIBILITY FOR ANY INACCURACIES, ERRORS, OR OMISSIONS THAT MAY APPEAR IN THIS INFORMATION. AMD SPECIFICALLY DISCLAIMS ANY IMPLIED WARRANTIES OF NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR ANY PARTICULAR PURPOSE. IN NO EVENT WILL AMD BE LIABLE TO ANY PERSON FOR ANY RELIANCE, DIRECT, INDIRECT, SPECIAL, OR OTHER CONSEQUENTIAL DAMAGES ARISING FROM THE USE OF ANY INFORMATION CONTAINED HEREIN, EVEN IF AMD IS EXPRESSLY ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.Copyright 2023 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, [insert all other AMD trademarks used in the material IN ALPHABETICAL ORDER here per AMD's Guidelines on Using Trademark Notice and Attribution] and combinations thereof are trademarks of Advanced Micro Devices, Inc. Microsoft is a registered trademark of Microsoft Corporation in the US and/or other countries. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners.