OpenCLaw on AMD Developer Cloud: Free Deployment with Qwen 3.5 and SGLang
Mar 16, 2026

OpenClaw stands out because it gives users meaningful control over what their agent can do. Instead of prescribing a fixed experience, it allows you to enable the skills, tools, and capabilities that match your needs and your comfort level. In practice, that means the power of the agent is shaped by what you choose to make available to it.
That design makes OpenClaw interesting not just as an AI assistant, but as a flexible foundation for personal automation. With the right configuration, it can help automate daily tasks, support recurring routines, and turn familiar messaging interfaces into a more capable personal workflow layer.
This blog focuses on a practical way to get started: running OpenClaw for free with Qwen 3.5 and SGLang on AMD Developer Cloud using a single AMD Instinct™ MI300X GPU. It is a straightforward path for developers who want to experiment with a capable self-hosted agent stack on AMD hardware without a large upfront cost.
To address these concerns, this guide demonstrates how to use a powerful open-source model that exceeds the limits of typical consumer-grade GPUs by running it on enterprise data center hardware, specifically the AMD Instinct MI300X with a massive 192GB of memory, at no cost.
Complimentary AMD Developer Cloud Credits through the AMD AI Developer Program
The AMD AI Developer Program provides members with $100 of free AMD Developer Cloud credits, which is enough for approximately 50 hours of usage to get started. Members who showcase useful applications and publicly share their projects may also apply for additional credits.
Beyond the credits, signing up grants you a one-month DeepLearning.AI PRO membership, automatic entry into monthly AMD hardware sweepstakes, and access to free AMD training courses.
Getting Started
Step 1: Sign up for the AMD AI Developer Program
Existing Users: If you already have an AMD account, simply sign in and enroll in the program.
New Users: Select “Create an account” on the login page to set up your AMD account and enroll simultaneously.
Step 2: Activate Your Credits
After you join the program, navigate to the “AMD AI Developer Portal Profile Page" and follow the instructions to get your free credit.
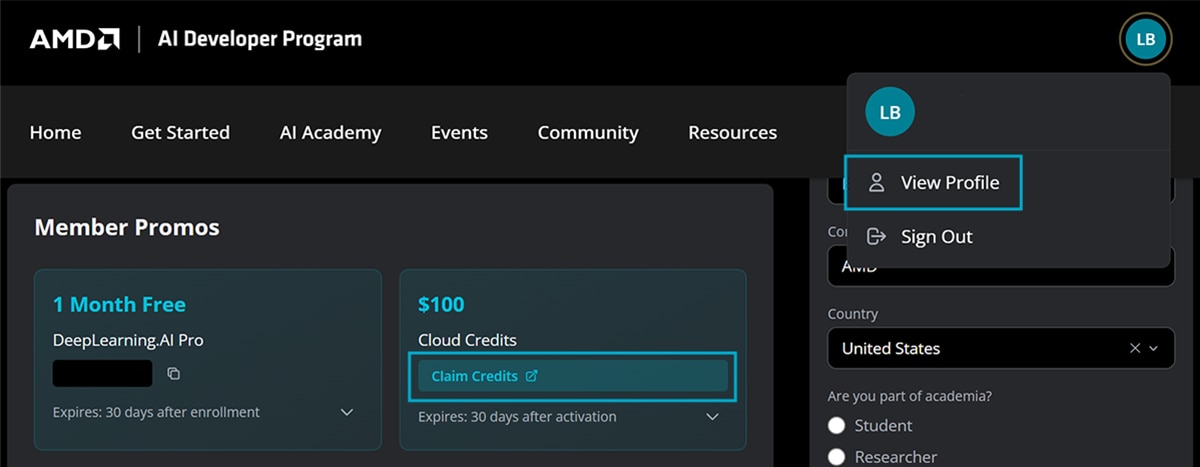
Step 3: Create a GPU Droplet
Once signed in, you will be directed to the Create a GPU Droplet page, where your credits should appear at the top.
- Select Hardware: Choose a single MI300X instance.
- Select Image: Choose the ROCm Software image.
- Configure Access: Add your SSH key (instructions for creating one are provided in that section of the page).
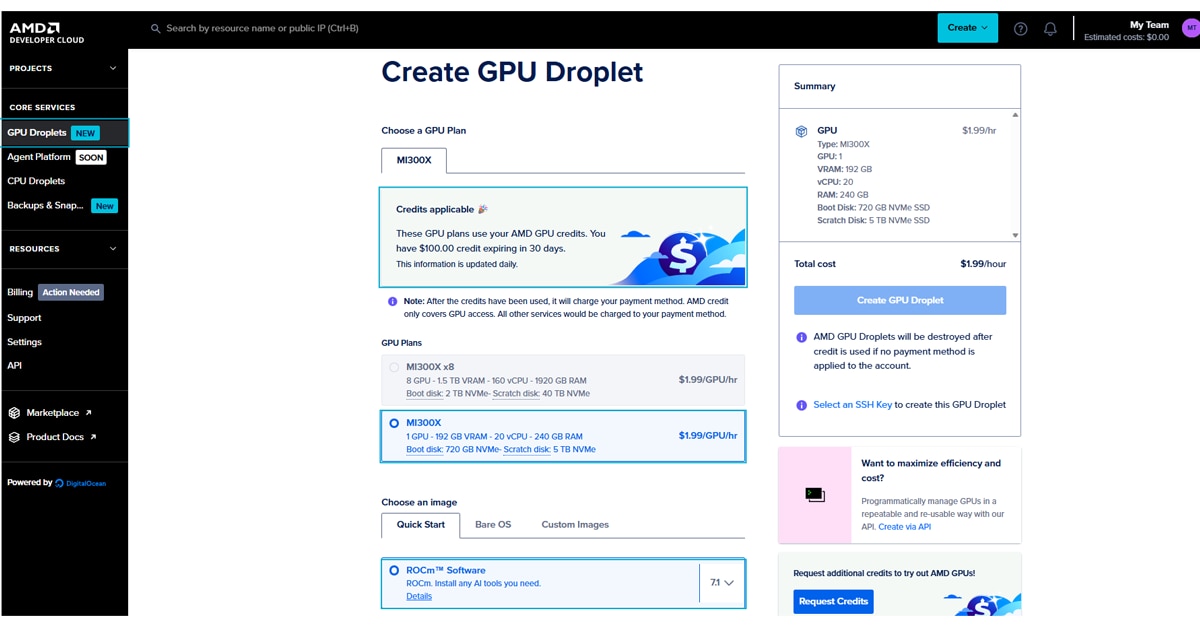
Once the droplet is created, you can access it via your terminal or by clicking on Web Console button:
ssh root@<YOUR_DROPLET_IP>
Running the Model with SGLang
We will use SGLang, one of the most popular frameworks for LLMs, to run our model. The following steps must be followed in your droplet that you created in the previous step.
Step 1: Configure Firewall and Launch
First, open port 8090 to allow traffic to your model:
ufw allow 8090
Step 2: Run the Model in SGLang Docker Container
In this example, we will pull the latest docker image for MI300X GPU and start a container to server Qwen3.5 model. Run the following commands on your droplet to start your model inference:
docker run -d \
--name sglang_server \
--ipc=host \
--privileged \
--device=/dev/kfd \
--device=/dev/dri \
-p 8090:8090 \
lmsysorg/sglang:v0.5.9-rocm700-mi30x \
python3 -m sglang.launch_server \
--model-path Qwen/Qwen3.5-122B-A10B-FP8 \
--served-model-name qwen3-5-122b \
--host 0.0.0.0 --port 8090 \
--tp-size 1 \
--api-key abc-123 \
--attention-backend triton \
--reasoning-parser qwen3 \
--tool-call-parser qwen3_coder \
--trust-remote-code
Note: Replace abc-123 in the command below with a secure, unique API Key.
This server exposes an OpenAI-compatible endpoint that OpenClaw can connect to directly during installation. The address of your endpoint will be in this format:
http://<your-droplet-ip>:8090/v1
Connecting OpenClaw to Your Local LLM
Now that the model is running, we will install OpenClaw and connect it directly to the SGLang endpoint. Recent versions of OpenClaw simplify this process significantly by allowing you to configure the model during the initial installation
Step 1: Install OpenClaw
Run the following command on your local machine or droplet (Mac/Linux):
curl -fsSL https://openclaw.ai/install.sh | bash
This launches the OpenClaw interactive onboarding process.
For all other OS installation options, please check OpenClaw’s official page. During installation, OpenClaw will guide you through a short onboarding process. For a minimal working setup, select the options shown in the screenshots below.
Step 2: Select QuickStart Mode
When prompted during installation, choose: Onboarding mode: QuickStart
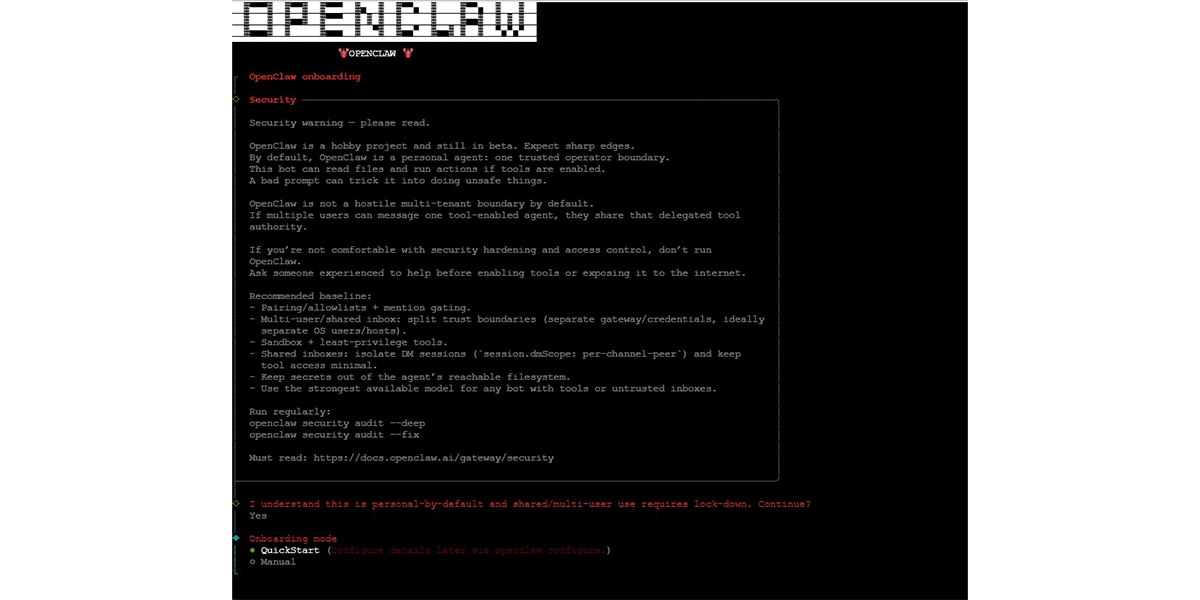
Step 3: Configure the SGLang Model
When prompted for the model provider, select: Model/auth provider: SGLang
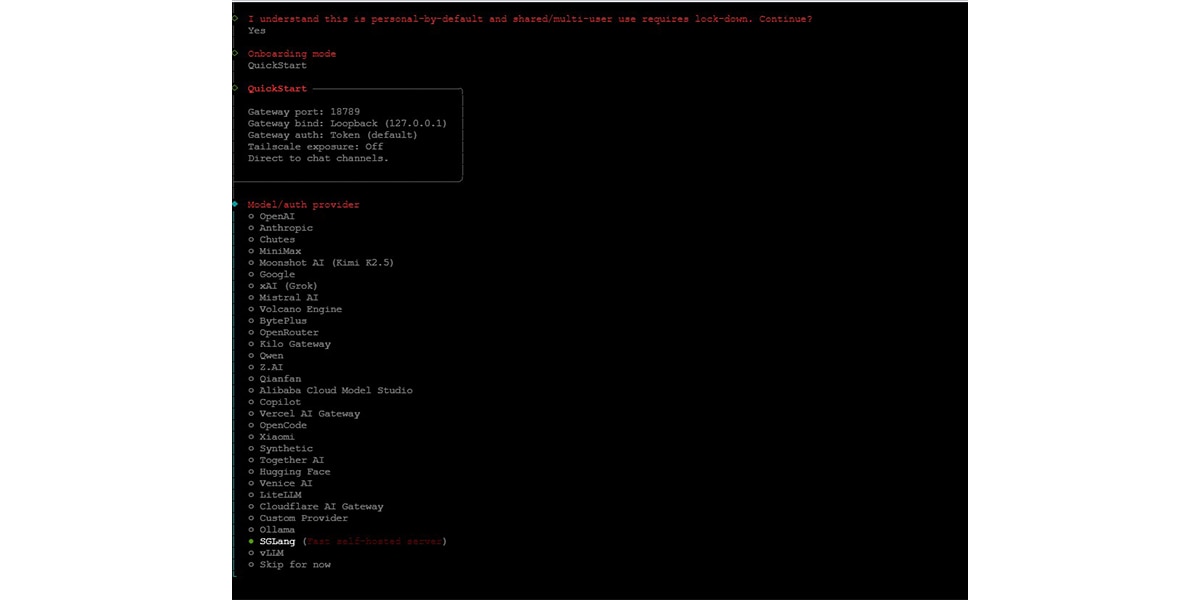
You will then be asked to enter the following values.
SGLang Base URL: http://<your-droplet-ip>:8090/v1SGLang API Key:
abc-123 (Replace this with the same API key you used when launching the SGLang server.)
SGLang Model: qwen3-5-122b (This must match the --served-model-name used when starting the SGLang server.)
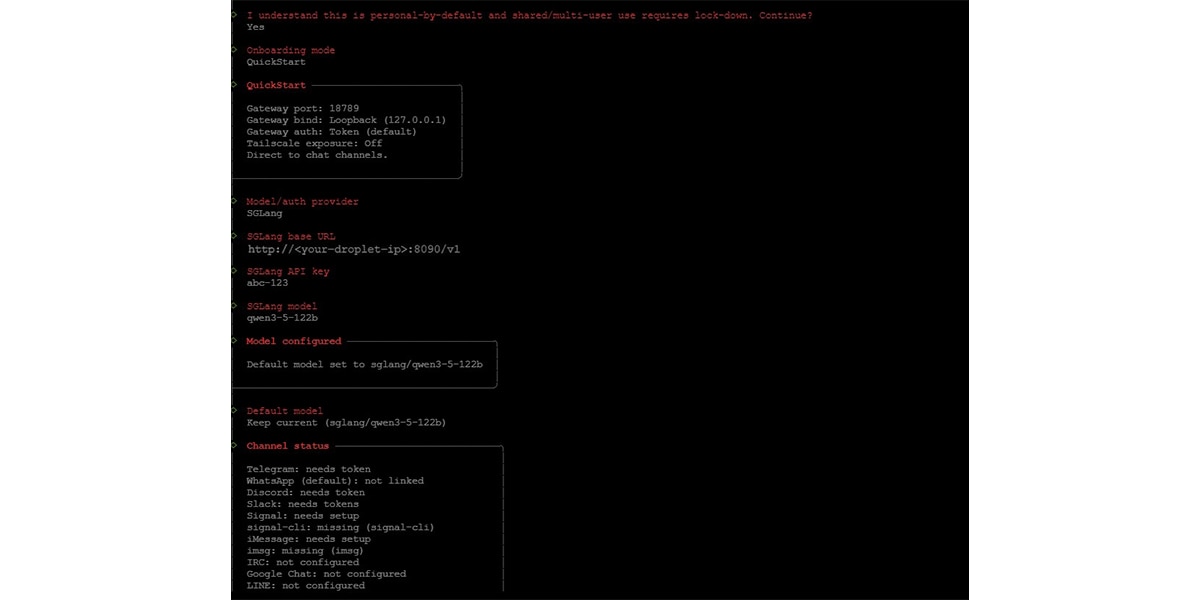
Once entered, OpenClaw automatically configures the provider and sets the model as the default agent model.
Step 4: Skip Optional Features
For a minimal working setup, you can skip the remaining optional features during onboarding:
- Chat channel integrations (Telegram, Slack, etc.)
- Web search provider
- Skills configuration
- Hooks
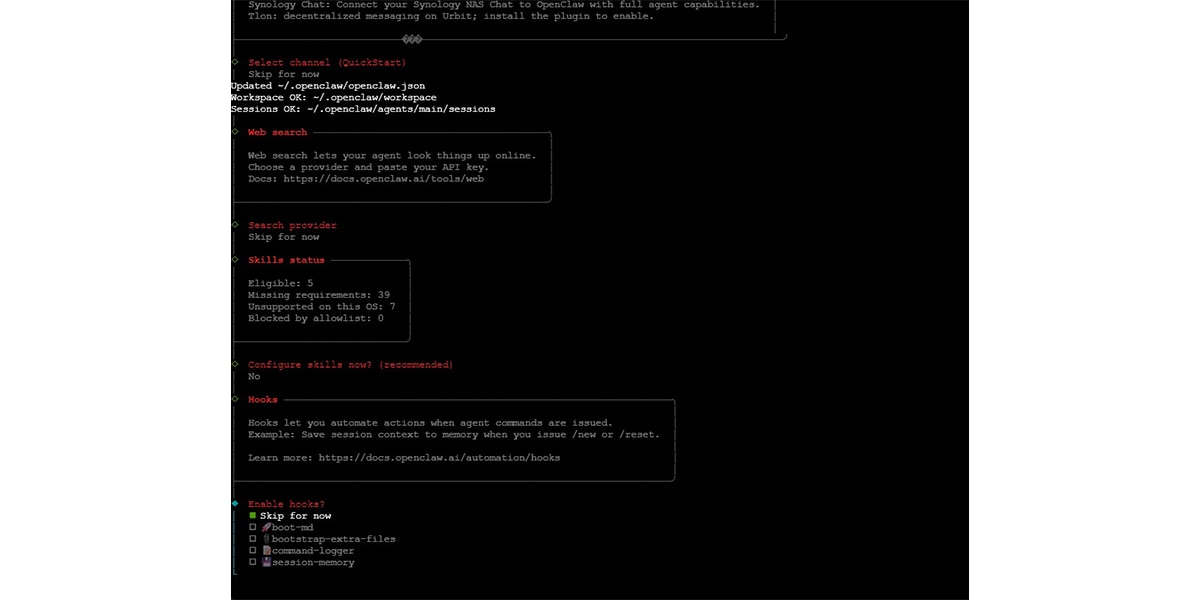
These features can always be enabled later.
Step 5: Open the OpenClaw Dashboard
At the end of onboarding, OpenClaw prints a dashboard link similar to:
http://127.0.0.1:18789/token=<generated-token>
If running on a remote droplet, create an SSH tunnel before opening any links in your browser:
ssh -N -L 18789:127.0.0.1:18789 root@<your-droplet-ip>
Then open in your browser:
http://127.0.0.1:18789/token=<generated-token>
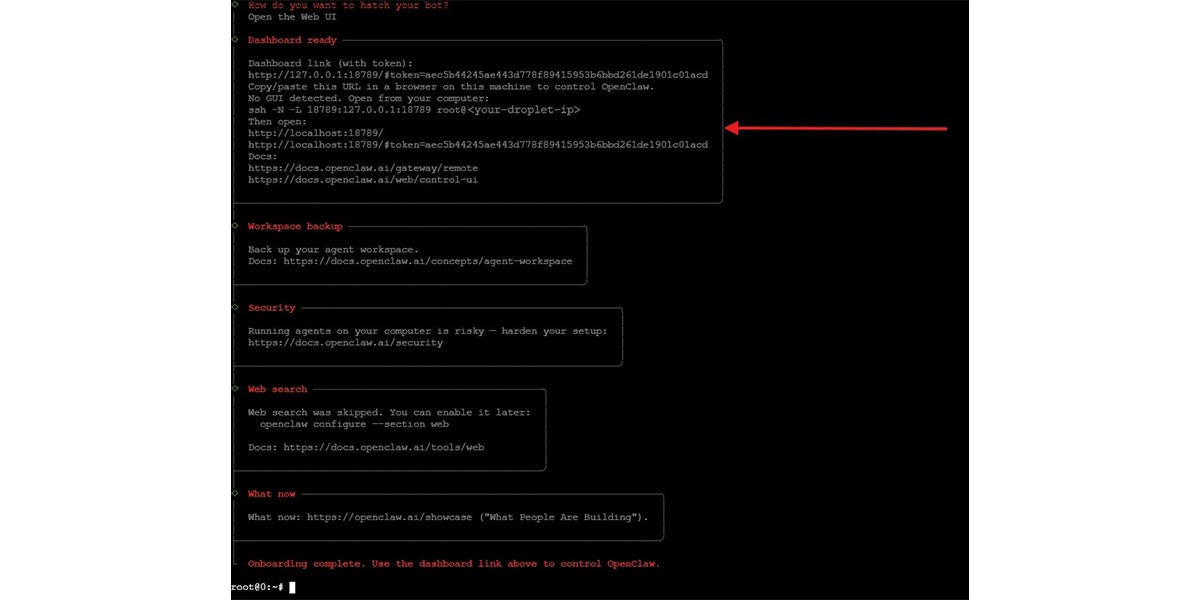
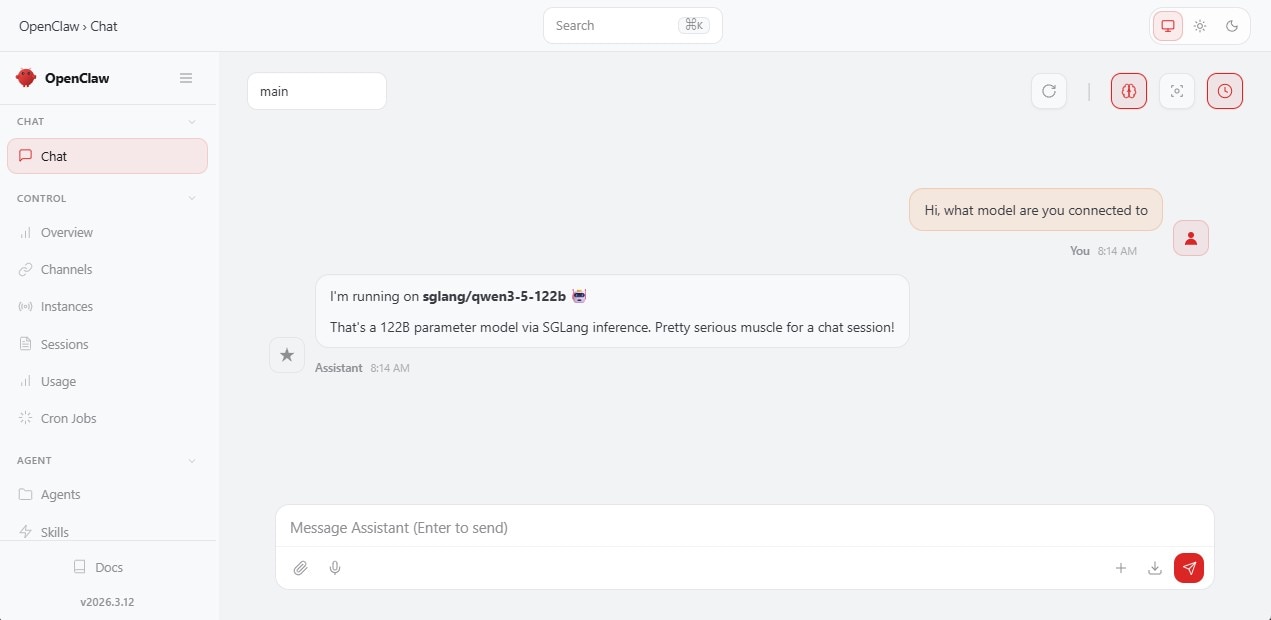
From here you can start chatting with your OpenClaw agent powered by your SGLang-hosted Qwen 3.5 model.
Conclusion
You are now ready to start chatting with your agent running on enterprise-grade hardware. You can use this same method to run other open-source models from Hugging Face. Don't forget to share your projects with the community to earn more free GPU credits. Happy building!


Related Blogs
-
What to Expect at AMD Advancing AI 2026
Get a preview of AMD Advancing AI 2026, including key themes, sessions, and innovations shaping the future of AI. Discover how industry leaders are coming together to explore real-world use cases and strategies for scaling AI across the enterprise.
July 14, 2026
-
Announcing the ROCm Certification Program
Build AI and HPC expertise on AMD Instinctt™ GPUs. Earn the ROCmt™ Certification with hands-on, production-ready skills.
July 13, 2026
-
GEAK Agent-Driven Optimization of the DeepSeekV4 MLA Kernel — ROCm Blogs
GEAK Agent accelerates DeepSeekV4 MLA kernel optimization with Triton and delivers SGLang E2E gains on AMD GPUs.
July 12, 2026
-
ZenDNN 6.0 FP16 Inference and MoE Acceleration
ZenDNN 6.0 takes the next step: FP16 functional support for AMD’s 6th Gen EPYC™ processors, MoE model optimization, and the vLLM compatibility window.
July 10, 2026
-
Fast Image Generation and Editing with SGLang Diffusion on AMD GPUs — ROCm Blogs
Serve and benchmark diffusion models for image generation and editing on AMD Instinct GPUs using SGLang Diffusion on ROCm.
July 09, 2026
-
AMD Instinct™ Network Traffic, Congestion Trends, and Harmonics in Scale-Out Networks for AI Training Clusters — ROCm Blogs
Explore how synchronized GPU collectives create harmonic congestion in AI clusters and the strategies to diagnose and mitigate it.
July 08, 2026
-
Porting High-Performance HIP Kernels to FlyDSL — ROCm Blogs
This blog post shows how to port HIP C++ GPU kernels to FlyDSL, AMD's new Python DSL, matching hand-tuned C++ performance with less code.
July 08, 2026
-
The Resilience as an Architectural Structure
This blog evaluates the Topological Ghost Protocol (TGP), an experimental architecture for long-context LLM inference on AMD Instinct™ MI300X, focusing on memory residency, KV-cache recycling, and resilience under high-concurrency workloads.
July 08, 2026







