Maximizing AI Performance: The Role of AMD EPYC 9575F CPUs in Latency-Constrained Inference Serving
Jun 12, 2025

Key Takeaways
- The rise of real-time agentic applications using Generative AI is setting higher performance benchmarks, particularly in terms of latency, for serving inference workloads.
- AMD EPYCTM 9575F host CPUs significantly improve latency-constrained inference serving, delivering over 10 times the performance compared to Intel Xeon Host CPUs1.
The Relevance of the Host CPU
While GPUs are often emphasized for AI workloads due to their significant processing capabilities, selecting the appropriate CPU can substantially boost GPU investments. With the emergence of agentic AI imposing stricter performance requirements on serving large language models (LLMs), the choice of host CPU can critically influence the responsiveness of agentic AI system performance. Internal performance analyses conducted by AMD on AI inference workloads running on GPU clusters have identified several key factors that underscore the importance of the CPU in accelerating inference serving:
- Runtime: When runtime is latency-constrained and includes non-overlapping pre-processing, a high-performance CPU can accelerate end-to-end workload performance.
- Orchestration: Collective operations, especially in mixture-of-expert (MOE) models, can be sensitive to CPU frequency, impacting overall performance.
- Novel Model Architectures: As model architectures evolve, newer models and runtimes may not be fully optimized for GPU deployment, making CPU performance even more critical.
- Control Plane: The CPU plays a vital role in managing the control plane, facilitating communication between GPU nodes.
- Agentic AI: As agentic AI evolves, it will impose even tighter performance constraints on inference serving.
Overview of AMD EPYCTM High Frequency Processors
5th Generation AMD EPYC™ CPUs include higher-frequency processor options designed specifically for hosting accelerator platforms. These CPUs excel at orchestrating data movement and managing multiple virtual machines—critical capabilities that can help to extract more performance from GPU nodes. With processor options up to 64 cores with a maximum frequency of up to 5 GHz and support for up to 6 TB of memory, 5th Generation AMD EPYCTM CPUs provide multiple powerful processor options specifically designed for hosting GPU clusters. In fact, our benchmark data, published in this whitepaper, has shown that increased core frequency performance results in accelerated AI workload performance.

Balancing Latency and Throughput
Throughput is important in inference serving as it is indicative of GPU and system utilization, essentially, high throughput implies good GPU utilization. Latency is equally important as it serves as an indicator of the system's responsiveness and usability. The significance of latency in inference serving applications is highlighted by the ML Perf Interactive benchmark variant, which targets real-time applications. Analysis of user data from popular LLM serving platforms has driven aggressive latency targets in the ML Perf Llama2 70B inference serving interactive benchmark [1]
- 450ms time to first token (99th percentile)
- 40ms per output token (99th percentile)
The ML Perf interactive mode inference serving benchmark, introduced in version 4.0, emphasizes responsiveness by balancing user experience with system efficiency. This benchmark variant is designed to reflect the latency constraints typical of real-time applications, thereby providing a more accurate measure of system performance under such conditions.
Balancing high throughput and good latency for inference workloads is challenging. Typically, higher throughput can be achieved by increasing batch sizes, but this often leads to higher latency. Conversely, optimizing for lower latency typically reduces throughput because smaller batch sizes are processed more quickly but less efficiently. However, by utilizing high-performance AMD EPYC™ 9575F CPUs, it is possible to achieve a more optimal balance between latency and throughput, enhancing overall system efficiency.
Comparative analysis with Intel Xeon Host CPUs
The following shows the inference serving performance on an 8x GPU system with a 2-socket CPU, utilizing the vLLM inference runtime to serve Llama-3.3-70B in a TP8 configuration. Latency-constrained throughput, also referred to as "goodput," is plotted against various time-to-first-token constraints (300ms, 400ms, 500ms, 600ms).
At a 300ms constraint, no goodput is observed on the Intel Xeon 8592+ processor hosted system. And at a 400ms constraint, the system hosted by the AMD EPYCTM 9575F host processor demonstrates over 10 times the goodput compared to the system using the Intel Xeon host processor.
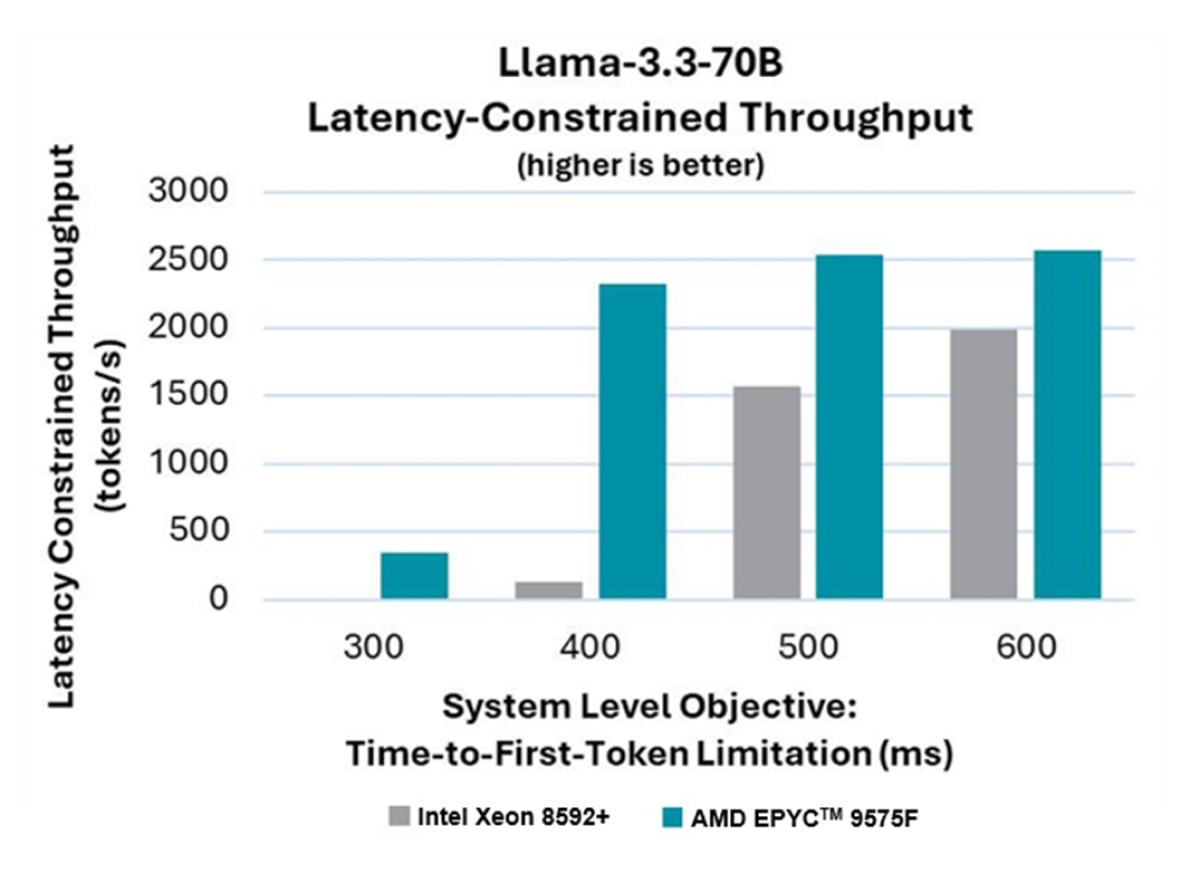
This comparative analysis of AMD EPYCTM 9575F processors with Intel Xeon host processor highlights the significant performance advantages of the AMD EPYCTM 9575F host processor in latency-constrained inference serving scenarios, demonstrating leadership efficiency and responsiveness when used as host CPU for a GPU system.
Configurations Tested
Model Tested |
Llama3.3 70B |
Data Set |
Sonnet3.5-SlimOrcaDedupCleaned [2] |
Runtime |
vLLM v1.0, TP8, MAX_NUM_REQS=512, NUM_PROMPTS=512 |
Test Runs |
5 times, average used |
Server Command |
vllm serve ${model} --dtype half --kv-cache-dtype auto -pp 1 -tp 8 |
Client Command |
python /workspace/vllm/benchmarks/benchmark_serving.py --model ${model} --tokenizer ${model} --dataset-name hf --dataset-path ${dataset_id} --num-prompts ${num_prompt} --goodput ttft:${slo_ttft} --trust-remote-code --save-result --hf-split train --percentile-metrics ttft,tpot,itl,e2el |
Testing Platforms |
Intel Xeon 8592+ host processor
|
AMD EPYCTM 9575F host processor |
Server |
Supermicro SYS-821GE-TNHR |
Supermicro AS-8125GS-TNHR |
CPU |
2P Intel Xeon Platinum 8592+ (2x64C Cores) |
2P AMD EPYCTM 9575F (2x64C Total Cores) |
CPU Peak Frequency |
3.9 GHz |
5.0 GHz |
GPU Accelerators |
8x H100 SXM 80GB HBM3 |
8x H100 SXM 80GB HBM3 |
Memory |
1TB 16x64GB DDR5-5600 |
1.5TB 24x64GB DDR5-6000 |
Operating System |
Ubuntu 22.04.3 LTS, kernel-5.15.0-118-generic |
Ubuntu 22.04.3 LTS, kernel=5.15.0-117-generic |
References
Footnotes
- 9xx5-169 : Llama-3.3-70B latency constrained throughput (goodput ) results based on AMD internal testing as of 05/14/2025.Configurations: Llama-3.3-70B, vLLM API server v1.0, data set: Sonnet3.5-SlimOrcaDedupCleaned, TP8, 512 max requests (dynamic batching), latency constrained time to first token (300ms, 400ms, 500ms, 600ms), OpenMP 128, results in tokens/s. 2P AMD EPYC 9575F (128 Total Cores, 400W TDP, production system, 1.5TB 24x64GB DDR5-6400 running at 6000 MT/s, 2 x 25 GbE ConnectX-6 Lx MT2894, 4x 3.84TB Samsung MZWLO3T8HCLS-00A07 NVMe ; Micron_7450_MTFDKCC800TFS 800GB NVMe for OS, Ubuntu 22.04.3 LTS, kernel=5.15.0-117-generic , BIOS 3.2, SMT=OFF, Determinism=power, mitigations=off) with 8x NVIDIA H100. 2P Intel Xeon 8592+ (128 Total Cores, 350W TDP, production system, 1TB 16x64GB DDR5-5600 , 2 x 25 GbE ConnectX-6 Lx (MT2894), 4x 3.84TB Samsung MZWLO3T8HCLS-00A07 NVMe, Micron_7450_MTFDKBA480TFR 480GB NVMe , Ubuntu 22.04.3 LTS, kernel-5.15.0-118-generic , SMT=OFF, Performance Bias, Mitigations=off) with 8x NVIDIA H100. Results:CPU 300 400 500 600; 8592+ 0 126.43 1565.65 1987.19; 9575F 346.11 2326.21; 2531.38 2572.42; Relative NA 18.40 1.62 1.29. Results may vary due to factors including system configurations, software versions, and BIOS settings. TDP information from ark.intel.com

Contributors

Related Blogs
-
For Creators Performance Is Creative Freedom
Artist Peter Neill uses AMD Ryzen processors, Ryzen AI-powered mobile performance, and Affinity by Canva to keep large-image editing fast, fluid, and creative.
July 27, 2026
-
Kimi-K3 on AMD Instinct GPUs
Day 0 support for Kimi-K3 on AMD Instinct MI355X GPUs with validated TP8 setups.
July 27, 2026
-
Attention Decode on AMD MI450 GPUs: A Gluon Kernel Optimization Guide — ROCm Blogs
Learn how to design a high-performance attention decode kernel on AMD MI450 GPUs using Gluon.
July 26, 2026
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026
-
Introducing Instella-MoE: A State-of-the-Art Fully Open Mixture-of-Experts Language Model — ROCm Blogs
Explore Instella-MoE-16B-A3B, AMD’s fully open 16B MoE LLM with 2.8B active params per token, trained on AMD Instinct™ MI300 & MI325 GPUs.
July 23, 2026
-
Enabling Language-specific Reasoning in Multilingual Models with Reinforcement Learning — ROCm Blogs
Learn how to train multilingual reasoning models with reinforcement learning and extend context windows on AMD Instinct GPUs.
July 23, 2026
-
Agentic AI Workflows Simplified
Rocm.AI simplifies how developers build and serve with ROCm on AMD GPU’s
July 23, 2026
-
AMD Launches Helios™: The Highest Performing Rackscale AI Infrastructure Solution
AMD launches Helios, an open rack-scale AI platform connecting 72 AMD Instinct™ MI455X GPUs for frontier AI inference and training
July 23, 2026







