Minions: On-Device and Cloud Language Model Collaboration on AMD Ryzen AI
Jul 08, 2025

The Cost-Accuracy Challenge of Today’s AI Systems
Application developers that are looking to incorporate the magic of AI in their applications must answer a fundamental question: which model should they use? This decision typically falls into one to two categories: either a frontier model, such as Open AI’s GPT o3, Anthropic’s Claude Opus 4, or a smaller language model ranging from 1 to 32 billion parameters from families like LLaMA, Qwen, etc.
Two key factors in choosing a model include the cost of serving the model and the accuracy necessary to perform the required task. Frontier models are known for their high performance, but it is no secret that the cost of using them can be high. In contrast, small models can be run locally on AI-enabled PCs with dedicated Neural Processing Units (NPUs) optimized for on-device AI workloads, such as those equipped with AMD Ryzen™ AI processors. AI PCs significantly reduce the cost of remotely running LLMs by running the inference locally. These smaller models that can run on local devices are rapidly increasing in capability to the point where they are sufficient for many tasks. However, for certain tasks, especially those requiring complex reasoning or larger context lengths, the small models fall short of the frontier capabilities.
This presents a tradeoff between accuracy and cost. Developers can choose to run a frontier model in the datacenter, which delivers state-of-the art results across a wide range of tasks, but at a higher cost. Alternatively, developers can run a smaller model locally, avoiding the per-token costs, but this may come with reduced accuracy in certain tasks.
A question we wanted to ask ourselves is: Are we forced to live in this dichotomy or is there a way to get the best of both worlds? That is why we are excited to be collaborating with the Hazy Research Group led by Chris Ré at Stanford University to enable Minions, their agentic framework which directly addresses the cost-accuracy tradeoff of today’s AI systems. This is enabled on Ryzen AI through integration with the AMD Lemonade stack.
What is Minions?
Minions is an agentic framework developed by the Hazy Research Group at Stanford University, which enables the collaboration between frontier models running in the datacenter and smaller models running locally on an AI PC. Now you might ask: if a remote frontier model is still involved, how does this reduce the cost? The answer is in how the Minions framework is architected. Minions is designed to minimize the number of input and output tokens processed by the frontier model. Instead of handling the entire task, the frontier model breaks down the requested task into a set of smaller subtasks, which are then executed by the local model. The frontier model doesn’t even see the full context of the user’s problem, which can easily be thousands, or even millions of tokens, especially when considering file-based inputs, common in a number of today’s applications such as coding and data analysis.
This interactive protocol, where the frontier model delegates work to the local model, is referred to as the “Minion” protocol in the Minions framework. The Minion protocol can reduce costs significantly but struggles to retain accuracy in tasks that require long context-lengths or complex reasoning on the local model. The “Minions” protocol is an updated protocol with more sophisticated communication between remote (frontier) and local agents through decomposing the task into smaller tasks across chunks of inputs. This enhancement reduces the context length required by the local model, resulting in accuracy much closer to that of the frontier model.
Figure 1 illustrates the tradeoff between accuracy and cost. Without Minions, developers are typically limited to two distinct options: local models that are cost-efficient but less accurate (bottom-left) and remote frontier models that offer high accuracy at a higher cost (top-right). Minions allows users to traverse the pareto frontier of accuracy and cost by allowing a remote and local model to collaborate with one another. In other words, Minions enables smarter tradeoffs between performance and cost, avoiding the extremes of all-local or all-remote models.
Please refer to the paper, “Cost-efficient Collaboration Between On-device and Cloud Language Models” for more information on the Minions framework and results.
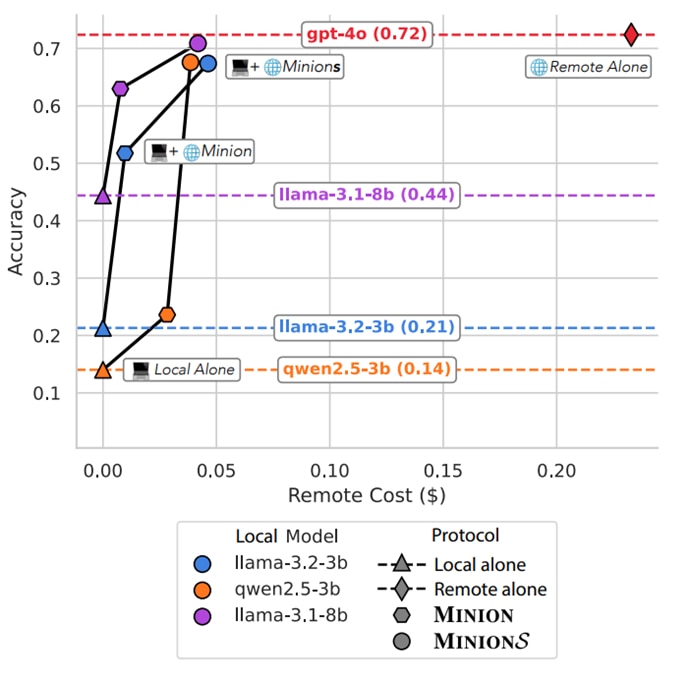
Figure 1. Demonstrating the Accuracy vs Cost problem that today’s AI application developers are facing. The FinanceBench, LongHealth, and QASPER datasets were used to generate this figure and the cost is estimated from GPT-4o rates from Jan. 2025. This figure is taken from Figure 2 of the Minions paper with the author’s permission: Cost-efficient Collaboration Between On-device and Cloud Language Models. Please refer to the paper for more details.
What is Lemonade?
If you’re new to Lemonade, it's a lightweight, open-source local LLM server designed to show the capabilities of AI PCs, with acceleration on AMD Ryzen AI PCs. Think of it as a docking station for LLMs, letting you plug powerful models directly into apps such as Open WebUI, and run them locally. Developers can also use Lemonade to integrate with modern projects that use the advanced features from the OpenAI standard. We use Lemonade to run Minions on AMD Ryzen AI PCs to leverage the powerful and efficient processing units of the integrated GPU (iGPU) and Neural Processing Unit (NPU).
Try It Yourself
To explore Lemonade in action, follow these steps to run a demo showcasing how Minions integrates with Lemonade.
Step 1: Install Lemonade on your device from the Lemonade website
Figure 2. Lemonade website. Click the “Download” button to download the Lemonade installer.
Step 2: Start the Lemonade Server by double-clicking the lemon desktop icon that was created during installation. Lemonade Server is running when you can see a lemon in your tray icons.
Step 3: Get an API key from your favorite frontier model provider. Minions currently supports targeting Open AI, Anthropic, Perplexity, Together, Open Router, Deepseek, and Mistral. Set the appropriate environment variable as noted by the Minions documentation to be able to communicate with the remote frontier model.
Step 4: Clone and build Minions from the repository.
git clone https://github.com/HazyResearch/minions.git
Step 5: Create and initialize your environment using the following commands:
cd minions
pip install -e
pip install transformers
Step 6: Run the application using the following command:
streamlit run app.py
Step 7: Configure the app with your desired configurations:
Select the desired remote provider chosen in Step 3
Select Lemonade as the local provider
Select your favorite Lemonade model as the local model
Provide the prompt and description of the task to be performed
Configure the protocol as Minion or Minions. This will control how the models communicate with one another.
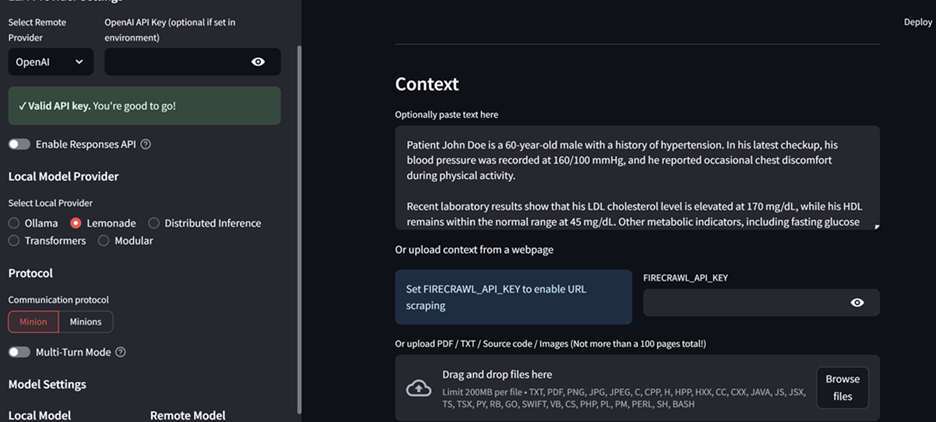
Figure 3. Image from the Minions Demo. Note that “Lemonade” is selected as the local provider.
Step 8: Sit back and watch the local and remote model communicate with one another to solve the task at hand! A good initial prompt can be taken from the Minions examples:
Context: “Patient John Doe is a 60-year-old male with a history of hypertension. In his latest checkup, his blood pressure was recorded at 160/100 mmHg, and he reported occasional chest discomfort during physical activity. Recent laboratory results show that his LDL cholesterol level is elevated at 170 mg/dL, while his HDL remains within the normal range at 45 mg/dL. Other metabolic indicators, including fasting glucose and renal function, are unremarkable.”
Description: “Blood pressure and cholesterol data.”
Query: “Based on the patient's blood pressure and LDL cholesterol readings in the context, evaluate whether these factors together suggest an increased risk for cardiovascular complications.”
This will generate a response that states that the provided data indicates a risk in cardiovascular complications.
Python API
Minions provides a Python API for integration into your application. See the Lemonade Open AI Python test, which shows how you can create a single Minions object that will automatically have the remote and local model collaborate with one another to perform a language task.
Building on top of Minions + Lemonade
Along with the ability to coordinate between local and remote models, the Minions repository contains multiple sample applications of how folks can build on top of Minions such as Model Context Protocol (MCP), Deep Research, and more. We encourage folks to try out those applications as well as to integrate Minions using Lemonade into their own applications!
Diving Deeper and Contributing
To learn more about Lemonade and how it integrates with Minions, the best place to start is the Lemonade Minions client. You will notice that it is very simple—this reflects not only how easy it is to integrate Lemonade into your own application, but also how straightforward it is to connect to new clients in the Minions framework.
We are very excited about the future of collaboration between remote and local models, and we are thrilled to be working with the open-source community on developing these frameworks!
We are still in the early stages of integrating Lemonade with local + remote collaborative frameworks such as Minions and we’d love your input. If you have feedback, fixes, or question, create an issue on the Minions repository and assign eddierichter-amd or edansasson, or email us at lemonade@amd.com.
To learn more and contribute to Lemonade, please check out lemonade-server.ai.
To learn more and contribute to Minions, please check out the Minions github repository.
To learn more about the Minions protocols and framework, check out the Minions paper which will be presented at the International Conference on Machine Learning, ICML 2025!
Acknowledgments
A massive shoutout to Avanika Narayan, Dan Biderman, and Chris Ré from Stanford University for creating and driving the Minions project and being such great collaborators.



Related Blogs
-
Announcing the ROCm Certification Program
Build AI and HPC expertise on AMD Instinctt™ GPUs. Earn the ROCmt™ Certification with hands-on, production-ready skills.
July 13, 2026
-
Serving NVFP4 Models on AMD Instinct™ MI355 Accelerators — ROCm Blogs
Learn how to serve NVFP4 models on AMD Instinct™ MI355 using an emulation pipeline in vLLM — no format conversion needed.
July 12, 2026
-
Towards Feature Complete Triton Support in JAX-Triton — ROCm Blogs
Learn what new features were added to JAX-Triton and how that could help you write or reuse more efficient and readable GPU kernels in JAX.
July 07, 2026
-
RDC and RocProfiler Compared to DCGM for Commonly Used Metrics — ROCm Blogs
Learn how CLI commands and Python code help you evaluate app performance without a profiler, with examples explaining what each metric means.
July 06, 2026
-
AMD Ryzen™ AI Developer Platform: Open, Ready, and Built for AI
Meet the AMD Ryzen™ AI Developer Platform: open, AI-first, and ready to help developers build, test, and deploy AI workloads.
July 06, 2026
-
Accelerating Large-Scale LLM Inference on AMD Instinct MI350X/MI355X with Eagle3 and AMD Quark — ROCm Blogs
Learn how the AMD Quark team enables Eagle3 speculative decoding for Kimi-K2.5 and MiniMax-M2.5 on AMD Instinct MI355X GPUs with ROCm, vLLM, and InferenceX.
July 02, 2026
-
Optimizing MI300X Inter-Chiplet Communication via the RCCL Tuner API — ROCm Blogs
Learn how to build a topology-aware RCCL tuner plugin for MI300X CPX/NPS4 mode and validate it with rccl-tests.
June 29, 2026
-
Why Open Software Matters for Enterprise AI
Open software is helping enterprises move AI from experimentation to production. Discover how open ecosystems, transparent frameworks, and AMD ROCm™ software enable organizations to accelerate innovation, maintain flexibility, and build AI strategies for long-term success.
June 29, 2026







