Rethinking Local AI: Lemonade Server’s Python Advantage
Jul 21, 2025
We’re the engineers behind Lemonade Server, an open-source tool that deploys local LLMs onto the GPUs and NPUs of AI PCs. Before people try Lemonade Server, they’re often surprised that we wrote it in Python. The main question being: Isn’t Python slow and cumbersome to deploy?
Once you try Lemonade Server, you’ll get it. It’s agile enough to keep up with the ever-evolving LLM ecosystem while delivering the polish and performance expected of native software.
This blog challenges the idea that Python isn’t suitable for production—by exploring how we used it to build Lemonade Server, a production-grade, high-performance local LLM deployment tool.
A quick note on the term “local LLM server”: this refers to software that provides (serves) LLMs to applications. Local LLM servers are becoming the de facto standard on AI PCs for two key reasons: 1) applications do not need to ship their own end-to-end LLM support, and 2) applications can easily swap between cloud-based and local LLM servers, which share the universal API discussed below.
Beating the Catch-22

Figure 2. Great LLM software in 2025 needs high software agility to keep up with LLM trends, while also being polished to production-readiness standards.
We faced a catch-22 when we started work on Lemonade Server. We needed to achieve both development agility and production-readiness, and our choice of programming language would seemingly equip us for success in only one or the other:
- The Python LLM ecosystem provides the development agility needed to keep up with the breakneck pace of LLM trends and advancements.
- Production-ready code for PC applications is often expected to be written in native languages like C# or C++.
There’s so much great work out there that developers have little patience for tools that are late on state-of-the-art capabilities, hard to distribute or install, or present a cumbersome user experience.
Next, let’s break down the requirements in each area, so that we can then describe how we navigated the decision space.
Development Agility Requirements
On the agility front, every month there is some new hype around a combination of model, tool, and technique that practically obsoletes what we had before. Last month the combo was Qwen3, MCP, and Hugging Face tiny-agents. Next month it’ll be something new, and developer tools that don’t keep up risk falling into obscurity. Ideally, developer tools like Lemonade Server are agile enough to adopt the latest and greatest within days of their public availability.
Production-Readiness Requirements
On the production-readiness front, here are some of the key metrics Lemonade Server had to meet, regardless of language:
- No noticeable overhead to the key LLM performance metrics of time-to-first-token (TTFT, aka prompt processing) or tokens-per-second (TPS).
- Familiar application experience with a one-click GUI installer, GUI access to all features, runs on startup, and lives in the system tray.
- No requirement that software like Anaconda, Python, pip, etc. is pre-installed.
- Ready to load an LLM less than 2 seconds after startup.
- Installed footprint must be small relative to LLM sizes: under 0.5 GB for CPU serving and under 1 GB for hardware-accelerated serving.
- Straightforward to include as a dependence in other software, regardless of that other software’s language.
Agility and Readiness Together
Figure 3. Our approach to Python gives us both development agility and the expected level of production readiness.
Here are the key enablers that allow us to deliver both agility and production-readiness in Lemonade Server using Python:
- Language-agnostic interface – The developer API is decoupled from implementation details, making it easy to integrate with any language or runtime.
- Native performance where it counts – All performance-critical components are implemented in native code, ensuring speed without sacrificing flexibility.
- Popular libraries – We build on proven foundations like Hugging Face, FastAPI, and OpenAI’s tooling to accelerate development and reliability.
- OS-native packaging and UX – Lemonade Server ships with native installers, system integration, and a user interface that feels at home on your machine.
The remainder of this blog is a technical deep dive into how we activated each of the 4 enablers.
The Common Interface
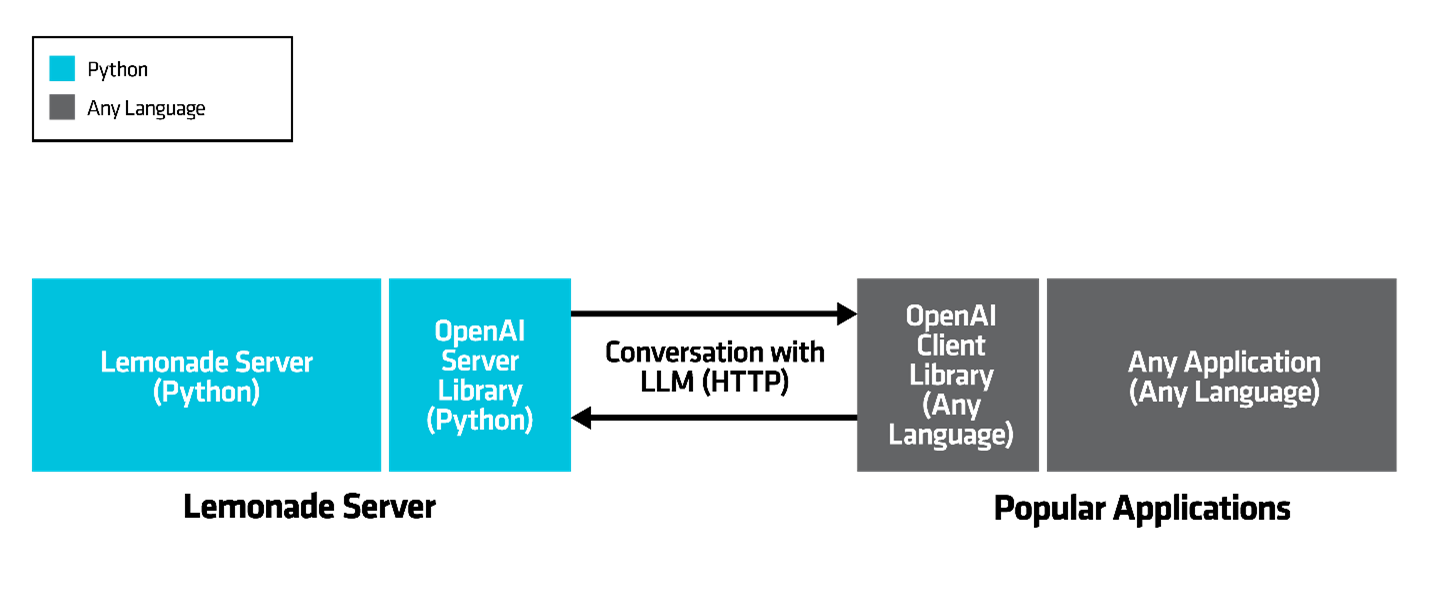
Figure 4. LLM servers like Lemonade provide LLMs to apps over the universal HTTP protocol which allows the server and apps to be agnostic about each others’ programming language.
The industry standard for applications to communicate with LLMs is the OpenAI API. While originally introduced by OpenAI for their cloud-based GPT-as-a-service product, it’s now widely adopted by both cloud and local deployment solutions—and supported by thousands of apps.
The OpenAI API encodes an app’s conversation with an LLM onto the universal HTTP protocol. This design choice helped it gain traction quickly, and today, client libraries exist for nearly every major programming language: C++, C#, Java, Python, Node.js, Go, Ruby, Rust, PHP, and more. This allows an LLM deployment tool written in any language to communicate with an app written in any other language.
This pervasiveness means that a new deployment tool like Lemonade Server, can adopt the OpenAI API and instantly become compatible with thousands of apps, regardless of what language they’re written in. Developers don’t need to know Lemonade Server is written in Python; they just use their OpenAI client library of choice, and it works.
Delivering Native Performance
Figure 5. Performance-critical tasks in Lemonade Server are implemented in native languages such as C++ and Rust. Only the natural language and routing logic is in Python.
We’ve solved the language barrier, but what about performance? Isn’t Python too slow for real-world app deployments? If that were true, Lemonade Server would suffer from sluggish startup times, delayed time-to-first-token, and poor token generation throughput.
And yet, Lemonade Server is as snappy and responsive as anyone could want. That’s because all performance-critical components run in native code under the hood.
For example, llama.cpp, ONNX Runtime, and Hugging Face transformers interface with Python, but offload the critical number crunching to the native code layer—often accelerated by GPUs or NPUs. By the time we’re back in Python, the workload has shifted from tensor math to natural language, which Python excels at.
We also make use of so-called lazy imports throughout the codebase—including using background threads to do imports—to avoid multi-second Python import times ending up on the critical path of important operations such as starting the server process.
Standing on the Shoulders of Great Libraries
Figure 6. Our own code for Lemonade Server is focused on providing a great user experience. We rely on great open-source libraries to provide high performance compute (ONNX Runtime GenAI, llama.cpp, Hugging Face transformers), HTTP serving (FastAPI), model management (Hugging Face Hub), and request/response formatting (OpenAI).
With the performance barrier addressed, let’s analyze how Python maximizes agility in Lemonade Server.
The LLM ecosystem already offers excellent inference engines and applications, and standards like HTTP and the OpenAI API are well-established. Lemonade Server shouldn’t reinvent the wheel—and it doesn’t. Instead, we concentrate our efforts on providing a great user experience by:
- Routing OpenAI requests to the right inference engine on the right device.
- Servicing complex requests, including those involving images and tooling calling.
- Providing a native GUI for routine tasks like model installation and management (see Native Look, Feel, and Distribution).
Here are the libraries Lemonade Server leverages to stay agile and focus on adding value:
| Library | How Lemonade Server Uses It |
| Hugging Face transformers |
|
Hugging Face huggingface_hub |
|
| openai |
|
| fastapi |
|
| GGML llama.cpp |
|
Native Look, Feel, and Distribution
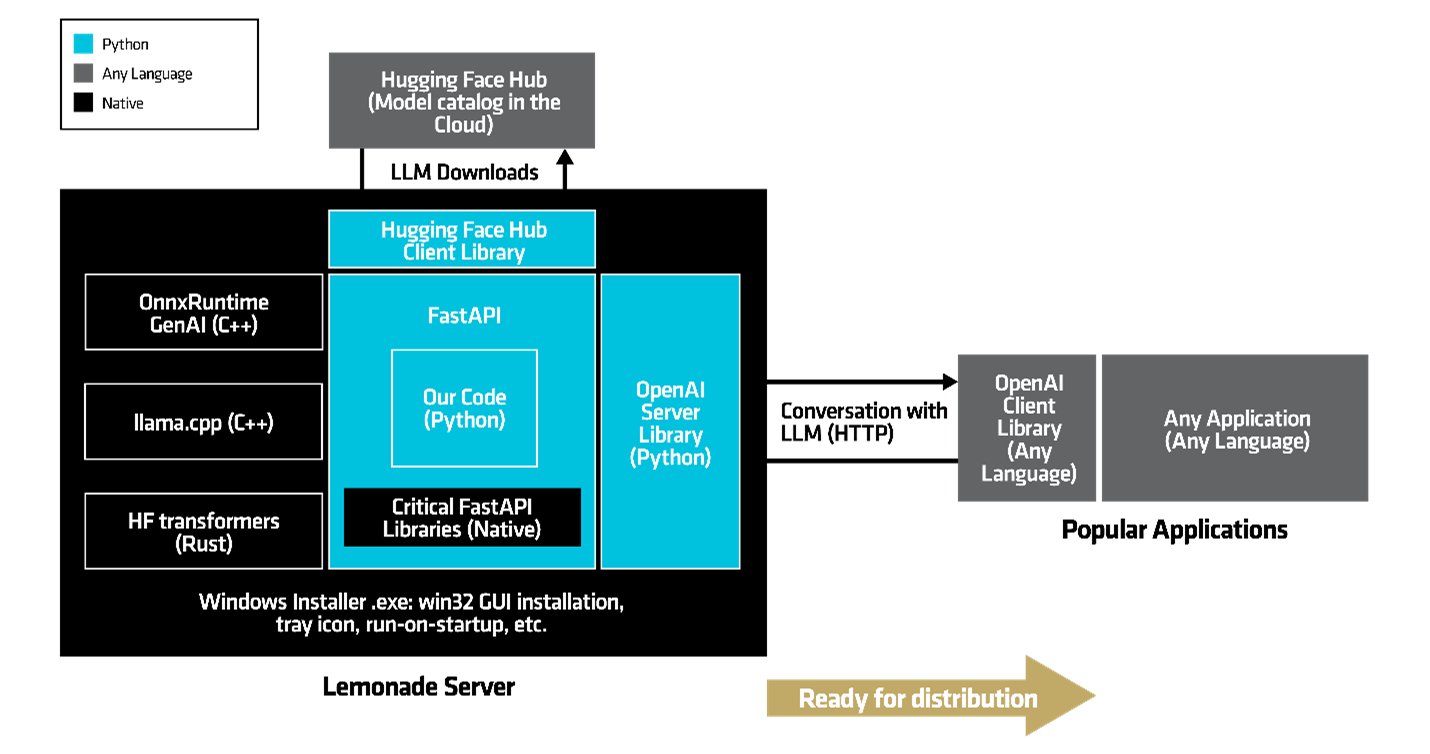
Figure 7. Full software architecture diagram for Lemonade Server, which is packaged and distributed using a native Windows installer and operating system hooks for the system tray and startup process.
Now that we have a compelling product, the next step is getting it into the hands of developers and LLM enthusiasts. Python is typically distributed via PyPI, which requires the user/developer to install a Python distribution and set up a virtual Python environment. While this process is fine for developers already working within the Python ecosystem, it’s not ideal for users nor developers working in any other language or expecting a native installation experience.
Figure 8. Screenshot of the Lemonade Server Installer GUI on Windows.
We solved this problem by wrapping our installation process with a lightweight Windows installer called Lemonade_Server_Installer.exe, which provides a familiar, user-friendly GUI (see Figure 8). Crucially, this installer contains a tiny (28 MB) “embeddable” Python interpreter, eliminating the need for the user to pre-install Python or manage virtual environments. This keeps the installation process simple and accessible, even for developers outside the Python ecosystem.
Figure 9. The Lemonade Server system tray application provides a menu for achieving common tasks such as loading/unloading models and accessing documentation.
Once Lemonade Server is installed on Windows, it becomes available as a system tray application (see Figure 9). This further meets the user’s expectations for native background services on Windows and provides convenient access to key features—such as loading and unloading models, accessing documentation, and launching the model management tool in the web app.
Figure 10. The Lemonade Server web app provides a graphical user interface (GUI) for important features.
The Lemonade Server web app (see Figure 10) provides a GUI for the most important features: chatting with the LLM and managing model downloads.
We implemented this as a web app, instead of a native application for two key reasons:
- Consistent cross-platform experience – It ensures the same look and feel across both Windows and Linux.
- Reference design – It demonstrates how a non-Python client—in this case, JavaScript—can interact with Lemonade Server over HTTP APIs.
Our one requirement for choosing a web app over a native GUI was that it had to feel just as fast and responsive. Try it for yourself, we think you’ll agree that it delivers.
Figure 11. Software is distributed on the lemonade-server.ai website.
Finally, to distribute Lemonade Server, we’ve launched a website at https://lemonade-server.ai. Getting started is simple: just click the big yellow Download button and run Lemonade_Server_Installer.exe. With a fast internet connection, the entire setup takes under two minutes.
While Pythonic installation via PyPI and GitHub remains available for developers who prefer it, the GUI experience prioritizes ease of use, making Lemonade Server accessible to a broader audience.
Conclusion
Thanks for taking this deep dive with us into the architecture and design choices of Lemonade Server! You can reach out to us at lemonade@amd.com if you have any questions or feedback. Please let us know if you’d like us to write more of this technical long-form content in the future.
Until next time, you can:
- Try out Lemonade Server at https://lemonade-server.ai
- Star our GitHub
- Learn more on our YouTube channel
- Read about using Lemonade Server with MCP and agents


Related Blogs
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026
-
Introducing Instella-MoE: A State-of-the-Art Fully Open Mixture-of-Experts Language Model — ROCm Blogs
Explore Instella-MoE-16B-A3B, AMD’s fully open 16B MoE LLM with 2.8B active params per token, trained on AMD Instinct™ MI300 & MI325 GPUs.
July 23, 2026
-
Enabling Language-specific Reasoning in Multilingual Models with Reinforcement Learning — ROCm Blogs
Learn how to train multilingual reasoning models with reinforcement learning and extend context windows on AMD Instinct GPUs.
July 23, 2026
-
Agentic AI Workflows Simplified
Rocm.AI simplifies how developers build and serve with ROCm on AMD GPU’s
July 23, 2026
-
AMD Launches Helios™: The Highest Performing Rackscale AI Infrastructure Solution
AMD launches Helios, an open rack-scale AI platform connecting 72 AMD Instinct™ MI455X GPUs for frontier AI inference and training
July 23, 2026
-
Agentic AI: AMD EPYC™ 9005 CPUs Wins Today, EPYC 9006, formerly code-named “Venice”, Takes It to a New Level
AMD EPYC 9006 Series Server CPUs deliver up to 256 cores, faster memory and I/O, and a strong foundation for enterprise AI workloads, helping advance your data center for the agentic era.
July 23, 2026
-
AI Networking Built for Scale
AMD AI networking unifies front-end, scale-up, and scale-out infrastructure to accelerate training, inference, and agentic AI.
July 23, 2026
-
AMD Helios™: Resilient Scale-Up Networking for AI
Discover how AMD Helios™ delivers resilient scale-up networking for production AI with UALoE, AFM, AFOS, and vPods.
July 23, 2026







