Ryzen AI and Radeon are ready to run LLMs Locally with Lemonade Software
Nov 13, 2025

Did you know that many AMD PCs can run free, private large language models (LLMs) right on the PC? Lemonade, or LLM-Aide, is an open-source project backed by AMD that aims to make it delightful and easy to get started.
This blog introduces Lemonade and shows some of our favorite LLM use cases on a variety of AMD computers, ranging from:
PC |
Device Families |
Key Specs |
Backend |
Scenario |
Phoenix /Hawk Point |
Integrated GPU 16-64 GB RAM |
Vulkan |
Design Assistant |
|
Strix / Krackan |
Neural Processing Unit (NPU) Integrated GPU 16-64 GB RAM |
Ryzen AI SW |
Document Q&A (RAG) |
|
Radeon |
Radeon™ 7800, 9070 or greater |
Discrete GPU 16-48 GB RAM |
ROCm |
Coding with Qwen3-Coder |
Strix-Halo |
Neural Processing Unit (NPU) Integrated GPU 64-128 GB RAM |
ROCm |
On-Device Chatbot |
We’re going to start with scenarios that can run on all of the listed PCs and then progress to the most demanding scenarios that require specialized hardware like Radeon and Ryzen AI 395 (Strix Halo).
Intro to Lemonade
Lemonade is a local LLM serving platform designed to maximize performance by leveraging the best available hardware acceleration—from Neural Processing Units (NPUs) to integrated and discrete GPUs. With Lemonade, you can run LLMs entirely on your PC, ensuring complete privacy and control over your data.
At the heart of the open-source Lemonade SDK is Lemonade Server, which plays a key role in enabling fast, easy integration with existing applications. It adheres to the OpenAI API standard, making it easy to deploy local LLMs without rewriting your codebase.
Using the one-click installer, the necessary dependencies and software packages are automatically set up to serve accelerated LLMs on Ryzen AI PCs. Once installed, your application can point to Lemonade Server’s OpenAI-compatible endpoint, allowing you to tap into the full power of your system’s NPU or GPU for efficient, private, and high-performance inference.
To see how to get started with Lemonade Server, including installing Lemonade Server and downloading, managing, and prompting LLMs, watch the following video:
Gemma-3-4B: Design Assistant
SYSTEMS: PHX/HWK, STX/KRK, Radeon, STX-Halo
Did you know some large language models can actually see? Gemma-3-4B, a vision-capable LLM from Google with 4 billion parameters, is lightweight enough to run smoothly on any of the PCs featured in this blog. Once you’ve installed Lemonade Server and launched the model, you can use the built-in LLM Chat from Lemonade to start sending the model images and having natural conversations to extract insights.
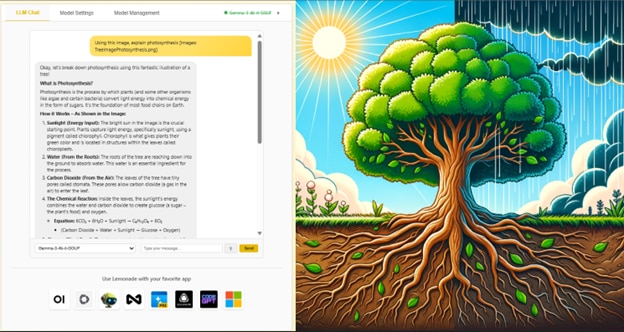
Figure 1: VLM for Photosynthesis Explanation
For example, try uploading a diagram of photosynthesis and asking the model to describe the process. You’ll get a clear, contextual breakdown—perfect for learning, getting explanations, or even generating new ideas.
We love to use it for feedback on our GUI!
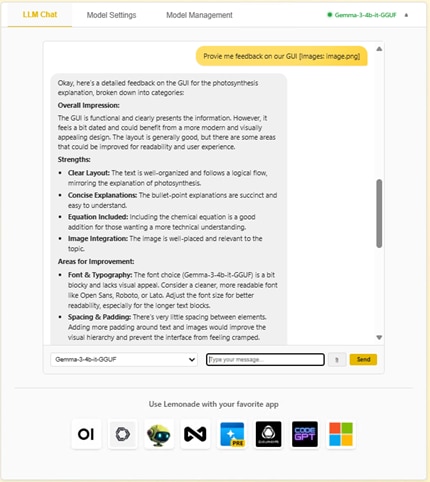
Figure 2: VLM for GUI Design Feedback
Qwen2.5-7B: Document Assistant
SYSTEMS: STX/KRK, Radeon, STX-Halo
One of the most productive ways to use local LLMs is to help them browse and analyze your private documents. Since the LLM is local, your documents always stay on your PC and remain fully private. This means that you can analyze confidential medical information, financial reports, or even private business documents and the information stays on your device and in your control.
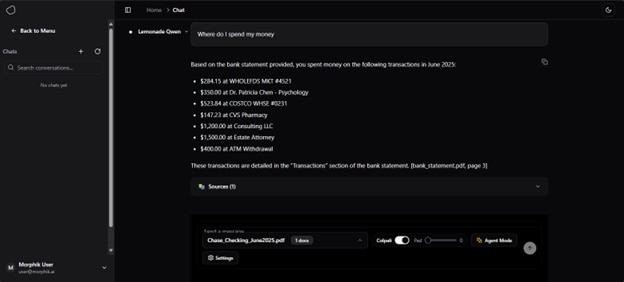
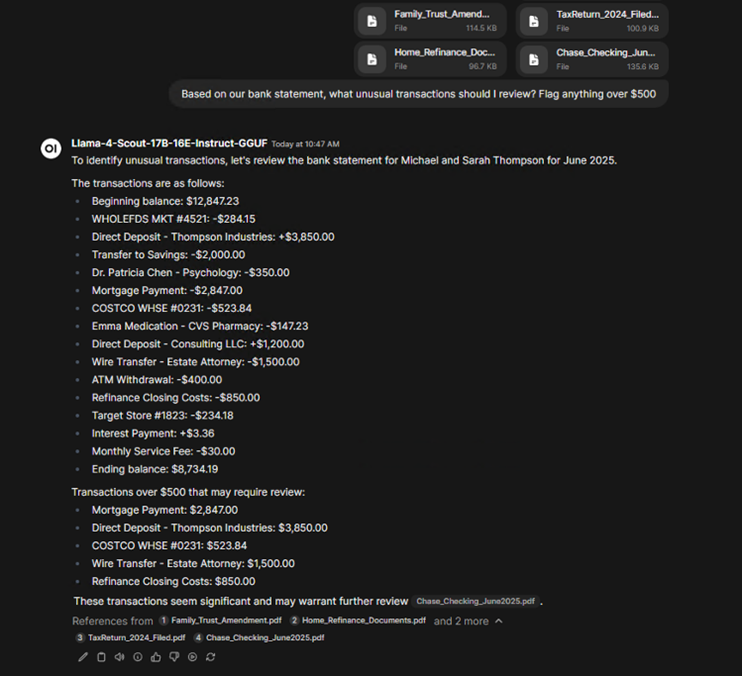
Figure 3: Morphik AI using Lemonade
Lately we’ve been enjoying using Morphik AI, an open-source app that fully integrates Lemonade and provides a comprehensive local document assistant. In the image above, you’ll see a screenshot where we uploaded a bank statement and asked, “Where do I spend my money?” and received a context-aware response.
Document assistants, like Morphik AI, are often powered by retrieval-augmented generation (RAG) systems that enhance the LLM’s capabilities by using relevant context from your documents, so that you get more meaningful answers. RAG augments the answer generation with specific information related to your documents, reports, and secure data.
To get started with Morphik AI for use with Lemonade:
- Use the self-hosted installation instructions for Morphik AI found here.
- Then, following the local inference guide to configure with Lemonade, found here.
Qwen3-Coder-30B: Coding Assistant
SYSTEMS: Radeon, STX-Halo
Large language models (LLMs) are getting to the point where they can be personalized and adaptive to our needs. Even at this early stage, the potential is already clear. We created a customized version of the classic game Asteroids using the Lemonade Model Hub on Continue.dev, with the following workflow:
- Chat to Scaffold: We begin by prompting the model through Continue’s chat interface to generate a basic framework for the game, including sample code and structure.
- Plan to Expand: Next, we use the planning feature to brainstorm enhancements—like power-ups, difficulty scaling, or visual effects—that align with our design goals. This is great for making sure you like what changes the model suggests.
- Agent to Automate: Finally, we activate the Agent to automatically refactor and extend the codebase, improving gameplay and tailoring the experience to our preferences. In this case, we wanted to add fun colors to the game.

Figure 4: Customized Asteroids Game using Qwen3-Coder
To see the full tutorial where we walk through a hands-on scenario showing how easy it is to build a custom version of the Asteroids game using Lemonade Server on a Ryzen AI PC with the Continue extension for VS Code see the guide here.
Bonus Content: We’ve also released a fun application that fully integrates Lemonade Server called Infinity Arcade, which easily creates retro-style games in minutes. Check it out here: https://infinity-arcade.app/
LLaMA 4 Scout 109B: On-Device Chatbot
BADGES: STX-Halo
AMD Ryzen™ AI Max+ 395 (128GB) is designed to manage demanding AI workloads locally with its substantial RAM and dedicated processing units. It efficiently runs models of various sizes, from compact 1B parameter models to large-scale systems like Mistral Large, utilizing llama.cpp and flexible GGUF quantization.
One of the largest models we’ve been exploring is Meta’s LLaMA 4 Scout 109B, a Mixture of Experts (MoE) model. While only 17B parameters are active during inference, the full 109B must reside in memory—making the Ryzen™ AI Max+ 395’s 128GB RAM essential. This setup enables performance even with models of this scale.
We use LLaMA 4 Scout 109B as a general-purpose assistant because it includes vision and MCP support. It handles image analysis, document interaction, and code generation with strong performance across these different tasks. Open WebUI is a great app for experiencing all these technologies in one place.
For more information on using Lemonade with Open WebUI, see the following resources:
Conclusion
As we wrap up our exploration of using Lemonade to run LLMs locally, it's clear that this tool is a game-changer for developers and tech enthusiasts alike. With its robust features and user-friendly interface, Lemonade improves the development process, making it more efficient and enjoyable. Whether you're a seasoned developer or just starting out, this tool offers something for everyone.
The integration capabilities, combined with its powerful debugging and testing tools, ensure that your projects are not only completed faster but also with higher quality. The community support and regular updates further enhance its appeal, keeping you at the forefront of technology.
The possibilities are just beginning—and they’re already in your hands. Happy coding!
You can reach out to us at lemonade@amd.com if you have any questions or feedback, we’d love to hear about the things you’re working on and how Lemonade can best serve you.
Until next time, you can:
- Try out Lemonade Server at https://lemonade-server.ai
- Star our GitHub
- Learn more on our YouTube channel
- Read about using Lemonade Server with MCP and agents
- Subscribe to the Ryzen AI Newsletter to stay up to date on the latest software releases and open-source projects features.


Related Blogs
-
What to Expect at AMD Advancing AI 2026
Get a preview of AMD Advancing AI 2026, including key themes, sessions, and innovations shaping the future of AI. Discover how industry leaders are coming together to explore real-world use cases and strategies for scaling AI across the enterprise.
July 14, 2026
-
LogsLop: A Tiny Summarization Tool for Enormous Log Files — ROCm Blogs
LogsLop deduplicates repetitive log lines so humans and LLMs can find failures in enormous log files.
July 13, 2026
-
Announcing the ROCm Certification Program
Build AI and HPC expertise on AMD Instinctt™ GPUs. Earn the ROCmt™ Certification with hands-on, production-ready skills.
July 13, 2026
-
Serving NVFP4 Models on AMD Instinct™ MI355 Accelerators — ROCm Blogs
Learn how to serve NVFP4 models on AMD Instinct™ MI355 using an emulation pipeline in vLLM — no format conversion needed.
July 12, 2026
-
Towards Feature Complete Triton Support in JAX-Triton — ROCm Blogs
Learn what new features were added to JAX-Triton and how that could help you write or reuse more efficient and readable GPU kernels in JAX.
July 07, 2026
-
RDC and RocProfiler Compared to DCGM for Commonly Used Metrics — ROCm Blogs
Learn how CLI commands and Python code help you evaluate app performance without a profiler, with examples explaining what each metric means.
July 06, 2026
-
AMD Ryzen™ AI Developer Platform: Open, Ready, and Built for AI
Meet the AMD Ryzen™ AI Developer Platform: open, AI-first, and ready to help developers build, test, and deploy AI workloads.
July 06, 2026
-
Accelerating Large-Scale LLM Inference on AMD Instinct MI350X/MI355X with Eagle3 and AMD Quark — ROCm Blogs
Learn how the AMD Quark team enables Eagle3 speculative decoding for Kimi-K2.5 and MiniMax-M2.5 on AMD Instinct MI355X GPUs with ROCm, vLLM, and InferenceX.
July 02, 2026







