Accelerating Python Performance with AOCL on AMD “Zen” Cores
Feb 11, 2026

Introduction
Python is one of the most popular languages for scientific computing, machine learning, and data analysis. However, performance can often be a bottleneck when working with large datasets or complex numerical computations. AMD addresses this challenge by providing Python users with a collection of Python libraries optimized with AMD Optimizing CPU Libraries (AOCL) – NumPy, SciPy, PyTorch, NumExpr and SciPy Sparse Extension.
AMD Optimizing CPU Libraries is a collection of highly tuned mathematical libraries designed to leverage the power of AMD “Zen” cores (e.g., higher count, increased memory bandwidth, larger cache, and AVX-512) that deliver accelerated performance on AMD EPYC™ and AMD Ryzen™ processors.
Our solution Python libraries with AOCL, brings the power of AOCL directly into the Python ecosystem through pre‑built, easy‑to‑install wheels. Designed for simplicity and performance, all libraries undergo extensive validation to guarantee a smooth, out‑of‑the‑box experience.
How are we better?
In this blog, we highlight our optimizations by running NPBench suite. This is a comprehensive benchmarking suite with a set of NumPy code samples representing a large variety of HPC, Data science and deep learning categories. A subset of benchmarks from the suite have been chosen for our tests with large input size (L). For SciPy, we select linalg.lstsq benchmark (lstsq source) as an example of the performance achievable with SciPy with AOCL.
Both NumPy and SciPy optimizations are driven by AOCL-BLAS and AOCL-LAPACK https://www.amd.com/en/developer/aocl.html.
The histograms in Figure 1 and Figure 2, compare the relative speedup of NumPy with AOCL against stock NumPy (i.e., using OpenBLAS as BLAS backend) for both single-threaded and multi-threaded. The baseline is set to 1.0 (stock performance). Higher bars indicate better performance gains.
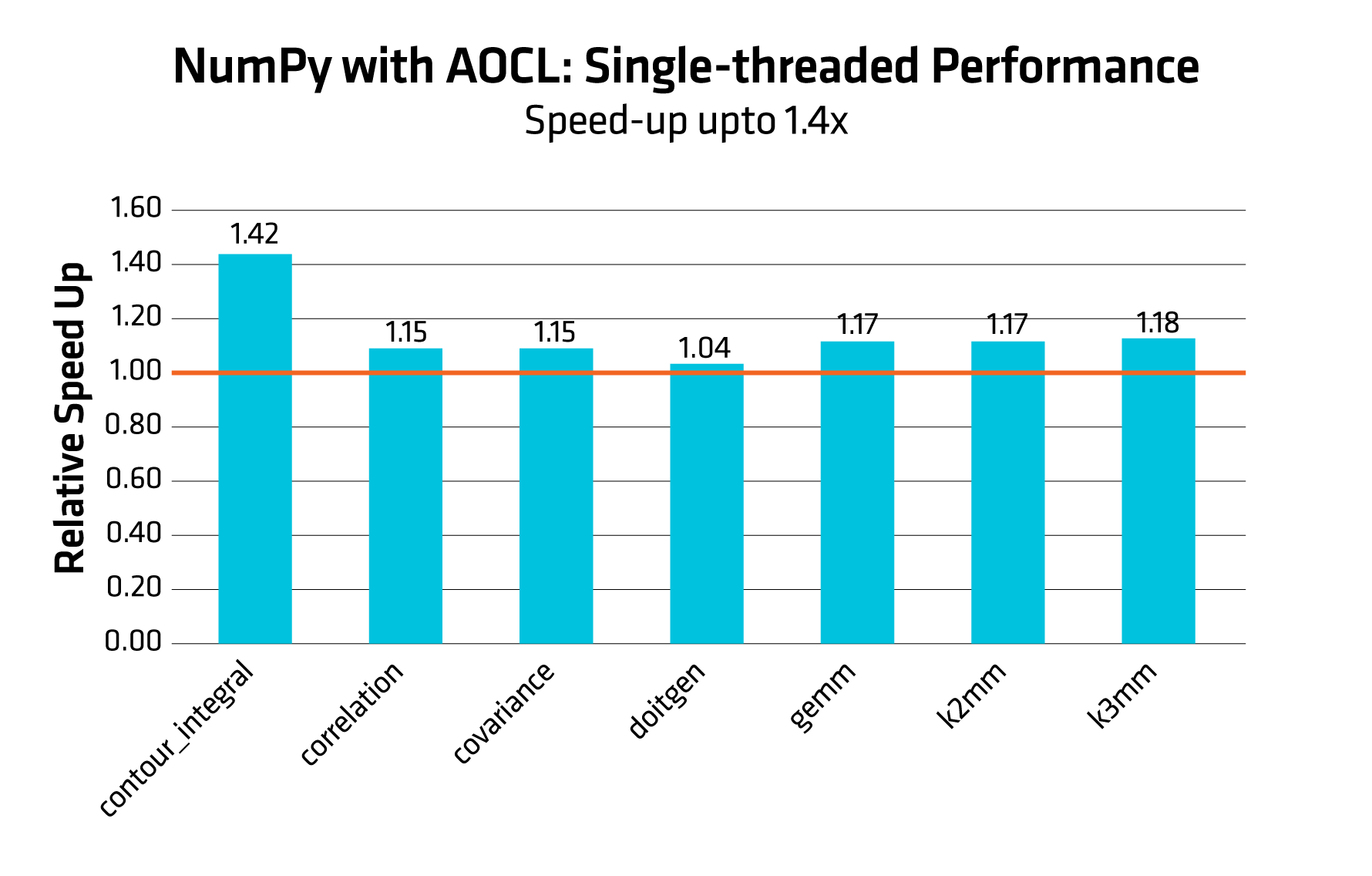
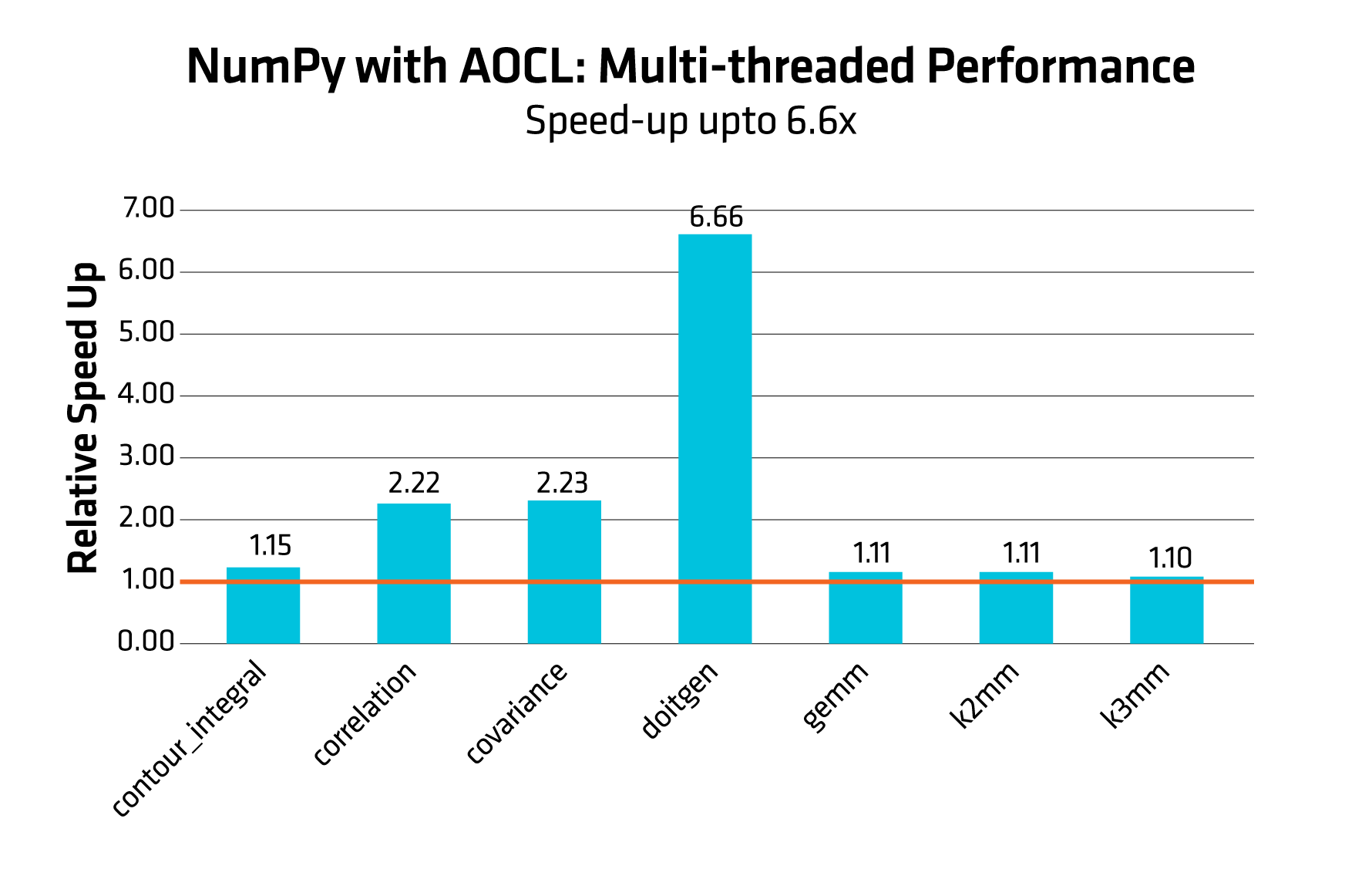
Performance results are based on validation with given tested configuration.
Figure 2 shows doitegen achieving a dramatic performance boost of 6.6x. Correlation and covariance also scale more than 2x while other benchmarks show modest gains. AOCL delivers excellent scalability and unlocks significant performance gains for compute-heavy and parallelizable workloads.
OpenMP is the threading model for AOCL-BLAS and AOCL-LAPACK libraries and thus parallelization for NumPy with AOCL and SciPy with AOCL can be controlled with OpenMP environment variable. Depending on the workload, you must set the required number of threads. For example, if you have access to 8 cores, set up the environment variable OMP_NUM_THREADS=8 in your run environment.
The optimal strategy of choosing OpenMP threads for best performance can vary between applications, and it is often worth experimenting with. More information on OpenMP thread placement strategies can be found at https://www.openmp.org/.
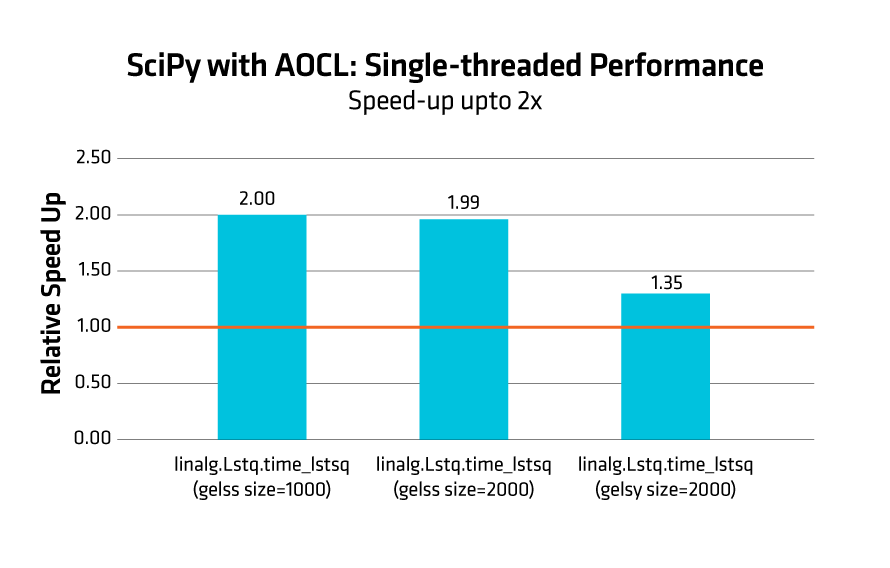
Figure 3 report the comparison for linalg.lstsq benchmark achieving a performance uplift up to 2x for SciPy with AOCL as compared to the stock SciPy implementation.
AOCL + Python = Secret behind the Speedup’s
Now that we have explored the performance gains, let us break down what is driving them! At the heart of these improvements are AOCL’s highly optimized kernels - specifically tuned for AMD architecture. By selectively leveraging AVX‑512 instructions, AOCL achieves maximum vectorization and throughput. Even the kernel dimensions are thoughtfully designed to align with AMD Zen cores.
Further, extensive low-level optimizations are crafted that include – loop optimizations for better instruction scheduling, branch prediction to minimize pipeline stalls/ full utilization of CPU pipelines, data prefetching for tactfully reducing read/write latencies.
As we step deeper, AOCL employs cache blocking techniques tailored specifically for Zen architecture to ensure fewer access to slower memory; computations stay closer to the CPU, flowing smoothly through the cache hierarchy. This reduces bottlenecks and helps workloads scale more gracefully as complexity increases.
To sum up, the architectural, microarchitectural, and memory‑level optimizations come together to deliver what users experience: lower latency and higher throughput compared to generic upstream implementations.
Quick Setup Made Simple: Install with Wheel Files
Each wheel can be installed using pip by downloading the given version from Python libraries with AOCL .
As we provide AOCL‑enabled wheels for each Python library, users can benefit from the optimizations without making any changes to their code.
Environment setup and Installation
We recommend using the Python virtual environments or Conda for good environment isolation. In this blog, we use the conda environment that can be created / activated as follows:
conda create -n <env_name> python=<version>
Follow the steps below to download and install the wheel (as an example):
- Download the wheel from Python libraries with AOCL
- Install required wheel –
pip3 install /path/to/numpy*.whl
For detailed instructions, please refer to https://docs.amd.com/r/en-US/57404-AOCL-user-guide/AOCL-User-Guide
Conclusion
AOCL brings hardware‑aware intelligence to Python workloads, unlocking the full potential of AMD Zen architecture, making computations faster and more efficient experiences.
If you are building data‑heavy, compute‑intensive, or performance‑sensitive applications, now is the perfect time to take advantage of what AOCL offers.
Give it a try - and feel the difference!


Related Blogs
-
The Journey Begins: AMD, SUSE and Rancher Government Solutions (RGS) Team Up on Initial Validation of Enterprise AI Blueprints
AMD, SUSE, and RGS are delivering a secure, open AI platform to accelerate private, sovereign, and enterprise AI deployments.
July 22, 2026
-
Kimi Code in MXFP4 on AMD GPUs
Discover how ATOM accelerates Kimi K2.5, K2.6, and K2.7-Code inference with optimized serving on AMD Instinct™ GPUs.
July 21, 2026
-
AMD Data Intelligence Platform: Open Modular Blueprint
See how AMD built OPTIMA, an open data intelligence platform that connects enterprise data for AI agents, analytics, and automation.
July 21, 2026
-
Rebuilding Agentic AI for AMD GPU
AMD and Moonshot AI built an agentic AI serving stack that optimizes KV cache, scheduling, and GPU performance on AMD Instinct™ GPUs
July 21, 2026
-
Efficient MiniMax-M3 Inference on AMD Instinct GPUs with ATOM and ATOMesh — ROCm Blogs
Serve and benchmark MiniMax-M3 on AMD Instinct MI355X GPUs using ATOM and ATOMesh with EAGLE3 speculative decoding.
July 20, 2026
-
Train and Run Models on AMD GPUs with Unsloth
Train, fine-tune, run AI models with Unsloth on AMD GPUs across Windows, WSL and Linux, with native inference for leading models.
July 20, 2026
-
Microsoft Azure Expanding AI Infra Choice with AMD Helios™
Microsoft and AMD expand Azure AI infrastructure with AMD Instinct MI455X and Helios, delivering more choice, scale, and efficiency.
July 20, 2026
-
GEAK V3: Agent-Driven, Repository-Level GPU Kernel Optimization across HIP, Triton, and FlyDSL on AMD GPUs — ROCm Blogs
Explore GEAK v3: agent-driven, repository-level GPU kernel optimization across HIP, Triton, and FlyDSL on AMD Instinct™ GPUs.
July 19, 2026







