Day 0 Support for Qwen3-Coder-Next on AMD Instinct GPUs
Feb 04, 2026

We are excited to announce Day 0 support for Alibaba’s latest open-weights AI coding model Qwen3-Coder-Next on AMD Instinct™ MI300X/MI325X/MI350X/MI355X GPU. This technical blog presents a Day 0 deployment walkthrough for Alibaba's Qwen 3-Coder-Next model family on AMD Instinct MI300X GPU by leveraging AMD ROCm™ 7 software and vLLM upstream optimizations.
This deployment guide is designed for AI developers, system architects, and DevOps professionals who are building next-generation agentic workflows. By supporting the Qwen3-Coder-Next family on AMD Instinct GPUs, we enable developers to run massive 256k context windows and complex coding tasks with high efficiency.
Traditionally, deploying state-of-the-art coding models required trade-offs between parameter count and reasoning depth. Qwen3-Coder-Next breaks this barrier by delivering 80B-parameter performance with only 3B activated parameters. This provides:
- High Cost-Effectiveness: Reduces the hardware footprint needed for sophisticated coding agents.
- Production Stability: Solves the "hallucination in execution" problem through advanced reasoning and error recovery.
- Hardware Choice: Breaks vendor lock-in by providing a seamless, Day 0 pathway for running top-tier coding LLMs on the high-memory GPU architecture by AMD.
Model Overview
- Super-efficient with significant performance: With only 3B activated parameters (80B total parameters), it achieves performance comparable to models with 10–20x more active parameters, making it highly cost-effective for agent deployment.
- Advanced agentic capabilities: Through an elaborate training recipe, it excels at long-horizon reasoning, complex tool usage, and recovery from execution failures, ensuring robust performance in dynamic coding tasks.
- Versatile integration with real-world IDE: Its 256k context length, combined with adaptability to various scaffold templates, enables seamless integration with different CLI/IDE platforms (e.g., Claude Code, Qwen Code, Qoder, Kilo, Trae, Cline, etc.), supporting diverse development environments.
Run Qwen3-Coder-Next with vLLM on AMD Instinct GPUs
The integration of ROCm™ 7 software and vLLM allows users to fully exploit the 192GB HBM capacity of the MI300X GPU.
- Unmatched Context: Users can serve the full 256k context length on a single GPU using FP8 precision, a critical requirement for repo-level coding tasks that often exceed the memory limits of lesser hardware.
- Optimized Throughput: By leveraging tensor parallelism, developers can achieve the low-latency response times required for real-time IDE integrations like Claude Code or Trae.
Before you start, ensure you have access to Instinct GPUs and the ROCm drivers set up.
Step 1: Get Started with vLLM
You can install the latest vLLM Python wheel*,
uv venv
uv .venv/vin/activate
uv pip install vllm --extra-index-url https://wheels.vllm.ai/rocm/0.15.0/rocm700
*Requires Python 3.12, ROCm 7.0, glibc ≥ 2.35 (Ubuntu 22.04+)
Alternatively, you can use the latest pre-built vLLM upstream docker image,
docker run -it \
--entrypoint /bin/bash \
--device /dev/dri \
--device /dev/kfd \
--network=host \
--ipc=host \
--group-add video \
--security-opt seccomp=unconfined \
-v $(pwd):/workspace \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--name Qwen3-Coder-Next \
vllm/vllm-openai-rocm:v0.15.0
Step 2: Start vLLM serving
vllm serve Qwen/Qwen3-Coder-Next --tensor-parallel-size 2 --enable-auto-tool-choice --tool-call-parser qwen3_coder
For optimum performance, please use --tensor-parallel-size 4.
You can also run the FP8 verison with single GPU using the maximum context length thanks to 192GB HBM capacity on MI300X GPU.
vllm serve Qwen/Qwen3-Coder-Next-FP8 --tensor-parallel-size 1 --enable-auto-tool-choice --tool-call-parser qwen3_coder
Let us check the accuracy,
python -m lm_eval --model local-completions \
--model_args '{"model": "Qwen/Qwen3-Coder-Next", "base_url": "http://localhost:8000/v1/completions", "num_concurrent": 256, "max_retries": 10, "max_gen_toks": 2048}' \
--tasks gsm8k \
--batch_size auto \
--num_fewshot 5 \
--trust_remote_code
The accuracy looks good.
Image Zoom

Step 3: Let’s Try Coding
Agentic coding
Qwen3-Coder-Next excels in tool calling capabilities. You can simply define or use any tools as following example from https://huggingface.co/Qwen/Qwen3-Coder-Next#agentic-coding
Sample Output
Choice(finish_reason='tool_calls', index=0, logprobs=None, message=ChatCompletionMessage(content=None, refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[ChatCompletionMessageFunctionToolCall(id='chatcmpl-tool-a4c3ba14abecbb9f', function=Function(arguments='{"input_num": 1024}', name='square_the_number'), type='function')], reasoning=None, reasoning_content=None), stop_reason=None, token_ids=None)
Coding Capabilities
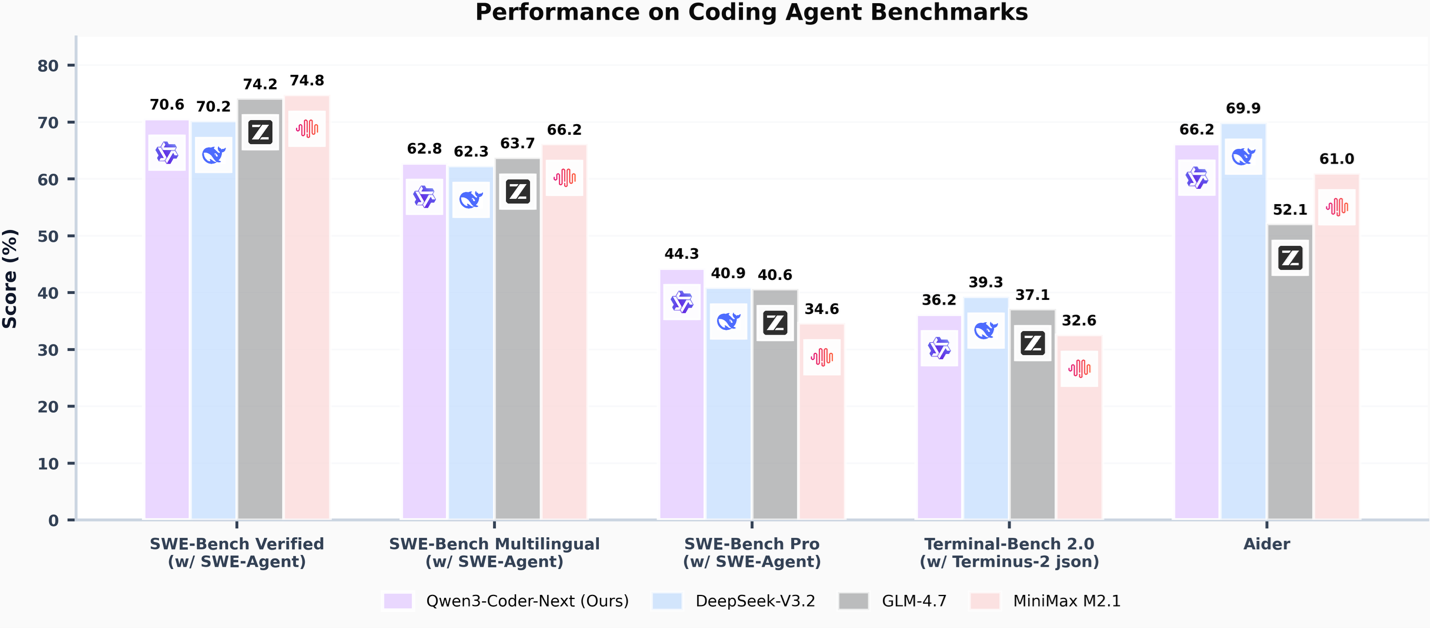
The Qwen3-Coder-Next model excels at coding across multiple languages and diverse tasks. We utilize a comprehensive evaluation set to rigorously measure its programming capabilities.
The Comprehensive testing script that evaluates Qwen3's coding capabilities across multiple domains:
- **Algorithm Implementation**: Binary search, sorting algorithms, data structures
- **Web Development**: React components, REST APIs, CSS layouts
- **Database Design**: SQL queries, schema design, normalization
- **System Design**: Architecture patterns, scalability concepts
- **Multiple Languages**: Python, JavaScript, SQL, C++, etc.

Summary
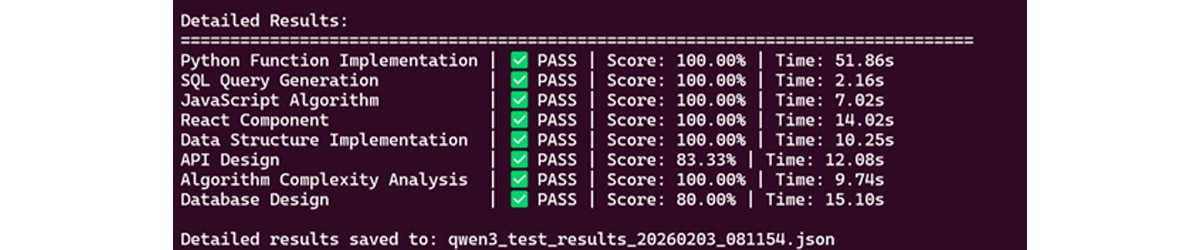
This blog presents the Day 0 support for Alibaba's Qwen3-Coder-Next model family on the AMD Instinct GPUs. It demonstrates exceptional coding capabilities across multiple programming languages and domains great success rate across 8 comprehensive tests.
By following this guide, you have learned how to deploy Qwen3-Coder-Next using vLLM to utilize specialized tool-calling parsers for agentic tasks and measure accuracy and coding capability across diverse coding domains including SQL, React, and System Design.
This enablement ensures that your development team can immediately start building robust, agent-led coding platforms on the latest AMD hardware.
Subsequent posts will deep-dive into kernel-level profiling, custom attention implementations, and ongoing collaboration between AMD ROCm software stack and Qwen model optimizations. Stay tuned.
Acknowledgements
AMD team members who contributed to this effort: Yi Gan, Hattie Wu, and the Qwen team.
Additional Resources
- Join AMD AI Developer Program to access AMD developer cloud credits, expert support, exclusive training, and community.
- Visit the ROCm AI Developer Hub for additional tutorials, open-source projects, blogs, and other resources for AI development on AMD GPUs.
- Explore AMD ROCm Software.
- Learn more about AMD Instinct GPUs.
- Download the model and code



Related Blogs
-
What to Expect at AMD Advancing AI 2026
Get a preview of AMD Advancing AI 2026, including key themes, sessions, and innovations shaping the future of AI. Discover how industry leaders are coming together to explore real-world use cases and strategies for scaling AI across the enterprise.
July 14, 2026
-
LogsLop: A Tiny Summarization Tool for Enormous Log Files — ROCm Blogs
LogsLop deduplicates repetitive log lines so humans and LLMs can find failures in enormous log files.
July 13, 2026
-
Announcing the ROCm Certification Program
Build AI and HPC expertise on AMD Instinctt™ GPUs. Earn the ROCmt™ Certification with hands-on, production-ready skills.
July 13, 2026
-
Serving NVFP4 Models on AMD Instinct™ MI355 Accelerators — ROCm Blogs
Learn how to serve NVFP4 models on AMD Instinct™ MI355 using an emulation pipeline in vLLM — no format conversion needed.
July 12, 2026
-
Towards Feature Complete Triton Support in JAX-Triton — ROCm Blogs
Learn what new features were added to JAX-Triton and how that could help you write or reuse more efficient and readable GPU kernels in JAX.
July 07, 2026
-
RDC and RocProfiler Compared to DCGM for Commonly Used Metrics — ROCm Blogs
Learn how CLI commands and Python code help you evaluate app performance without a profiler, with examples explaining what each metric means.
July 06, 2026
-
AMD Ryzen™ AI Developer Platform: Open, Ready, and Built for AI
Meet the AMD Ryzen™ AI Developer Platform: open, AI-first, and ready to help developers build, test, and deploy AI workloads.
July 06, 2026
-
Accelerating Large-Scale LLM Inference on AMD Instinct MI350X/MI355X with Eagle3 and AMD Quark — ROCm Blogs
Learn how the AMD Quark team enables Eagle3 speculative decoding for Kimi-K2.5 and MiniMax-M2.5 on AMD Instinct MI355X GPUs with ROCm, vLLM, and InferenceX.
July 02, 2026







