Empowering Local AI: AMD Radeon™ AI PRO R9700 Workstations Arrive July 23
Jul 17, 2025

As AI inference grows more memory-intensive and model complexity continues to increase, developers are seeking hardware that can handle these demands locally - without compromising on performance or flexibility. From large language models to generative pipelines, modern AI workloads require GPUs with both high compute capability and ample VRAM.
To meet this demand, AMD is pleased to announce the upcoming availability of workstation systems featuring the AMD Radeon™ AI PRO R9700 - its most advanced professional graphics for local AI development and high-throughput inference. These GPUs will be available in pre-built workstation systems1 starting July 23, 2025, from select AMD hardware partners specializing in custom, high-performance computing solutions.

Memory-Bound Performance, Redefined
Built to accelerate medium to large AI models directly on local workstations, the AMD Radeon™ AI PRO R9700 combines 32GB of high-speed GDDR6 memory, advanced RDNA™ 4 architecture, and broad support for modern AI data types. With 64 Compute Units, 128 second-generation AI accelerators, and support for FP8, FP16, and INT8 precision, the R9700 delivers ample TOPS performance, and the versatility needed to tackle today’s most demanding AI workloads.
Unlike GPUs restricted by smaller memory buffers, the R9700 can run large models entirely in VRAM - eliminating the need to fall back on system RAM and enabling faster inference, higher throughput, and broader model compatibility. In real-world scenarios like high-token-count LLM prompts and instruction-tuned models, it delivers up to 5x the performance of 16GB-class GPUs, setting a new bar for memory-bound AI performance in professional workstations2.
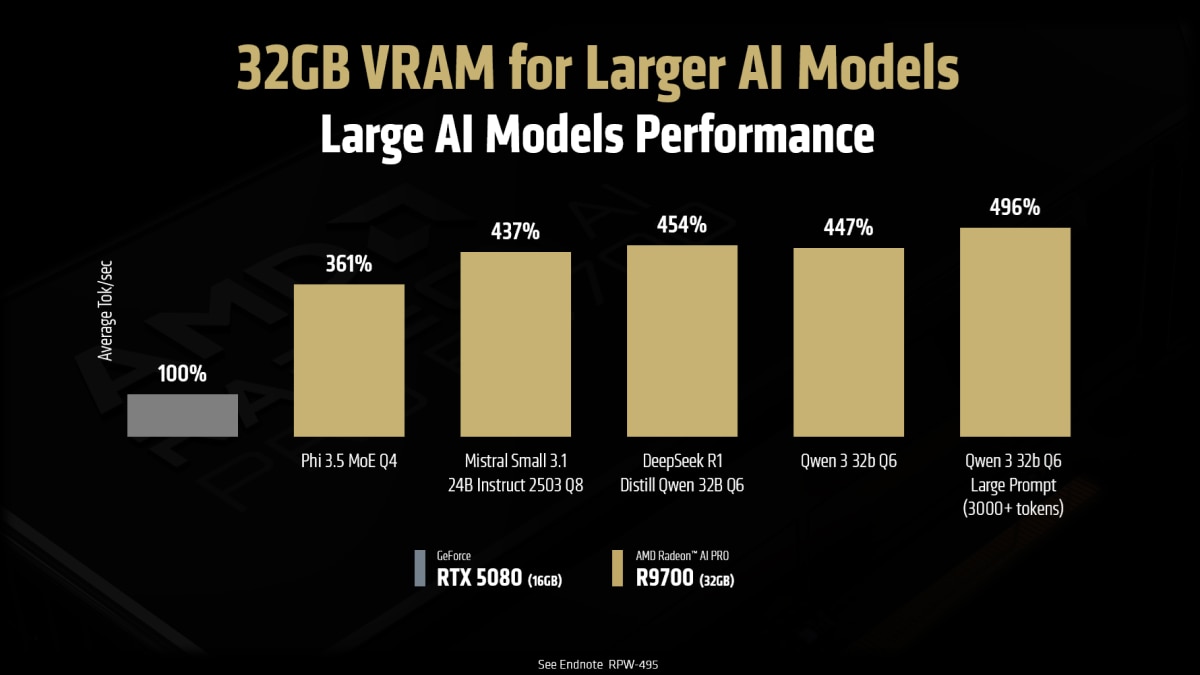
Purpose-Built for AI Professionals
Engineered for AI-first professionals who demand more than consumer-class hardware can offer, the AMD Radeon AI PRO R9700 excels in natural language processing, text-to-image generation, generative design, and other high-complexity tasks that require large models or memory-intensive pipelines. Whether running production-scale inference, performing local fine-tuning, or supporting multi-modal workflows, the Radeon AI PRO R9700 provides the capacity and speed to keep workloads fully local - improving performance, reducing latency, and providing greater data security.
The AMD Radeon AI PRO R9700 is fully compatible with the AMD ROCm™ open software platform, giving developers access to a robust, scalable environment for AI and high-performance computing. With support for leading frameworks like PyTorch, ONNX Runtime, and TensorFlow, ROCm allows users to build, test, and deploy AI models efficiently on local workstations powered by the R9700. The combination of 32GB of VRAM, RDNA™ 4 architecture, and ROCm 6.4.1 enables accelerated performance across inference, fine-tuning, and custom model workflows - making the Radeon AI PRO R9700 a compelling solution for AI professionals who value performance, flexibility, and open standards.
Thanks to its compact dual-slot design, PCIe® 5.0 interface, and blower-style cooling solution, the Radeon AI PRO R9700 is ready for multi-GPU workstation deployments. Unlike consumer GPUs with axial fan designs - often unsuitable for dense configurations - the R9700’s blower design ensures efficient front-to-back airflow, allowing multiple cards to operate reliably in close-proximity, high-performance systems. This makes it easy to deploy parallel inference pipelines, expand memory capacity across GPUs, and support larger concurrent model workloads -empowering enterprises to build reliable, high-throughput AI infrastructure fully on-premises.
Get Hands-On with Radeon AI PRO R9700 via Radeon Test Drive
Developers interested in evaluating the Radeon™ AI PRO R9700 for local AI workloads will soon be able to access it through the Radeon Test Drive program. Designed to help technical users explore AMD’s AI-capable workstation GPUs, the program offers hands-on access to ROCm 6.4.1 environments powered by AMD Radeon™ PRO GPUs -hosted on high-performance partner workstations. Whether you're benchmarking frameworks like PyTorch or evaluating local LLM inference, Radeon Test Drive is a fast, risk-free way to get started. Apply now to request access: www.amd.com/en/developer/resources/cloud-access.html
Coming Soon: Standalone R9700 Cards Arriving This Quarter
The standalone Radeon™ AI PRO R9700 graphics cards will be available later in Q3 2025 from leading AMD add-in board (AIB) partners. Additional details on partner availability and pricing will be announced in the coming weeks.
To learn more about the AMD Radeon™ AI PRO R9700, visit:
Footnotes
- Radeon™ PRO W6000 and W7000 Series and Radeon™ AI PRO R9000 Series graphics cards (and later models) are not designed nor recommended for datacenter usage. Use in a datacenter setting may adversely affect manageability, efficiency, reliability, and/or performance. GD-239a.
- Testing as of May 2025 by AMD. Average tokens per second of three runs, dropping edge cases where the model starts spiraling (more than 2k thinking tokens) to standardize response length. No speculative decode. All tests conducted on LM Studio 0.3.15 (Build 11). Vulkan Llama.cpp 1.28 used for AMD, NVIDIA-recommended CUDA 12 llama.cpp 1.30 with Flash Attention used for NVIDIA. Short Prompt: "How long would it take for a ball dropped from 10 meter height to hit the ground?“ Long Prompt: “Summarize the following in exactly five lines: [Insert Scene 1 Act 1 of Romeo and Juliet]”, Models tested: Phi 3.5 MoE Q4 K M, Mistral Small 3.1 24B Instruct 2503 Q8, DeepSeek R1 Distill Qwen 32B Q6, Qwen 32b Q6 System specifications: AMD Ryzen™ 9 7900X, 32GB DDR5 RAM 6000 MT/s, Windows 11 PRO 24H2, AMD Radeon™ AI PRO R9700 32GB using Adrenalin 25.6.1 RC vs AMD Ryzen™ 9 7900X, 32GB DDR5 RAM 6000 MT/s, Windows 11 PRO 24H2 with NVIDIA GeForce RTX 5080 and GeForce 576.4 drivers. Performance may vary. RPW-495.
Footnotes
- Radeon™ PRO W6000 and W7000 Series and Radeon™ AI PRO R9000 Series graphics cards (and later models) are not designed nor recommended for datacenter usage. Use in a datacenter setting may adversely affect manageability, efficiency, reliability, and/or performance. GD-239a.
- Testing as of May 2025 by AMD. Average tokens per second of three runs, dropping edge cases where the model starts spiraling (more than 2k thinking tokens) to standardize response length. No speculative decode. All tests conducted on LM Studio 0.3.15 (Build 11). Vulkan Llama.cpp 1.28 used for AMD, NVIDIA-recommended CUDA 12 llama.cpp 1.30 with Flash Attention used for NVIDIA. Short Prompt: "How long would it take for a ball dropped from 10 meter height to hit the ground?“ Long Prompt: “Summarize the following in exactly five lines: [Insert Scene 1 Act 1 of Romeo and Juliet]”, Models tested: Phi 3.5 MoE Q4 K M, Mistral Small 3.1 24B Instruct 2503 Q8, DeepSeek R1 Distill Qwen 32B Q6, Qwen 32b Q6 System specifications: AMD Ryzen™ 9 7900X, 32GB DDR5 RAM 6000 MT/s, Windows 11 PRO 24H2, AMD Radeon™ AI PRO R9700 32GB using Adrenalin 25.6.1 RC vs AMD Ryzen™ 9 7900X, 32GB DDR5 RAM 6000 MT/s, Windows 11 PRO 24H2 with NVIDIA GeForce RTX 5080 and GeForce 576.4 drivers. Performance may vary. RPW-495.


Related Blogs
-
Train and Run Models on AMD GPUs with Unsloth
Train, fine-tune, run AI models with Unsloth on AMD GPUs across Windows, WSL and Linux, with native inference for leading models.
July 20, 2026
-
Microsoft Azure Expanding AI Infra Choice with AMD Helios™
Microsoft and AMD expand Azure AI infrastructure with AMD Instinct MI455X and Helios, delivering more choice, scale, and efficiency.
July 20, 2026
-
GEAK V3: Agent-Driven, Repository-Level GPU Kernel Optimization across HIP, Triton, and FlyDSL on AMD GPUs — ROCm Blogs
Explore GEAK v3: agent-driven, repository-level GPU kernel optimization across HIP, Triton, and FlyDSL on AMD Instinct™ GPUs.
July 19, 2026
-
Open Standards, Real Solutions: AMD at SIGGRAPH 2026
AMD heads to DigiPro and SIGGRAPH 2026 to discuss open standards, production technology, and the fine art of Gaussian splatting.
July 17, 2026
-
FastFlowLM Joins AMD to Advance AI Inference
The FastFlowLM team has joined AMD, marking another key step in AMD’s strategy to advance AI performance and efficiency across the stack.
July 17, 2026
-
Running Cloud Agents? Your Most Important Upgrade Could be an AMD Zen 5 CPU
As agents begin navigating applications, coordinating tools and completing real work, the local CPU is becoming a critical part of the AI execution pipeline.
July 16, 2026
-
From Vector Search to Agentic RAG: Building an Enterprise Research Analyst with hipVS — ROCm Blogs
Learn how to build an agentic RAG research assistant using hipVS GPU-accelerated vector search on AMD Instinct GPUs, with multi-query decomposition, parallel retrieval, and cited sources synthesis.
July 14, 2026
-
When a Faster Kernel Doesn’t Speed Up Serving: Profiling FP8 KV Cache on AMD Instinct MI308X — ROCm Blogs
Learn how a 34% faster FP8 KV cache kernel delivered 0% E2E speedup, and how profiling attribution exposed the hidden dtype-cast cost on MI308X.
July 14, 2026







