Enabling the Future of AI: Introducing AMD ROCm 7 and AMD Developer Cloud
Jun 12, 2025

At a Glance:
- AMD ROCm™ 7 elevates AI with major performance boosts, distributed inference, enterprise solutions, and broader support across Radeon and Windows, all in collaboration with the open-source community.
- The AMD Developer Cloud offers instant, hardware-free access to AMD Instinct™ MI300 GPUs with pre-configured environments and complimentary credits, enabling seamless AI development and deployment.
- The expanding AMD AI ecosystem showcases real-world ROCm adoption for scalable, open AI innovation.
Developers first. That’s the mantra shaping everything we’re doing with ROCm™ 7 and the AMD Developer Cloud. Because at AMD, we’re not just building AI tools—we’re building them for you.
Whether you’re a grad student chasing your first LLM idea, a researcher tweaking next-gen attention mechanisms, or a team pushing production workloads at hyperscale, we want to make your life easier, faster, and just plain better. It’s ROCm everywhere and for everyone.
Over the past year, we have shifted our focus to enhancing our inference and training capabilities across key models and frameworks and expanding our customer base. Our commitment to supporting developers has resulted in improved out-of-the-box capabilities, streamlined setup processes, and increased community engagement. Consequently, our customers are deploying AI capabilities at an unprecedented pace, prompting us to accelerate our release cadence with new features. Leading models like llama 4, gemma 3, and Deepseek are now supported from day one, and our collaboration with the open-source community has never been stronger, underscoring our dedication to fostering an accessible and innovative AI ecosystem.
At Advancing AI 2025, we shared a vision. Not just about performance charts or speeds and feeds—but about accessibility and scalability. About putting MI300X-class GPUs in the hands of anyone with a GitHub ID. About installing ROCm with a simple pip install. About going from zero to Triton kernel notebook in minutes.
With ROCm 7 and the AMD Developer Cloud, that vision is real. It’s open, frictionless, and ready for you to build the future of AI—on your terms.
Let’s dive in.
ROCm 7: Accelerating Developer Enablement and AI Performance at Scale
With ROCm 7.0, AMD is accelerating AI innovation at every layer—from algorithms to infrastructure—bringing real competition and openness back to the software stack. ROCm 7.0 is built to meet the expanding needs of generative AI and HPC workloads while transforming the developer experience through accessibility, efficiency, and a vibrant community collaboration.
We are thrilled to announce that ROCm 7, with its exciting new capabilities and enhancements, will become generally accessible in Q3 2025. Here's a sneak peek into the remarkable features that are coming your way:
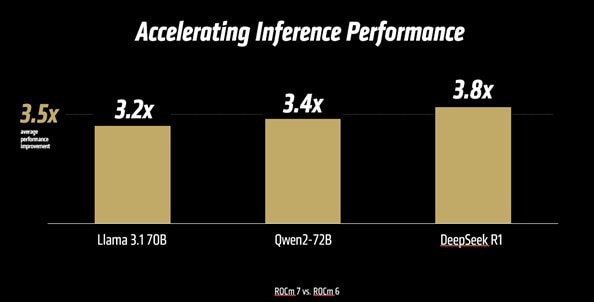
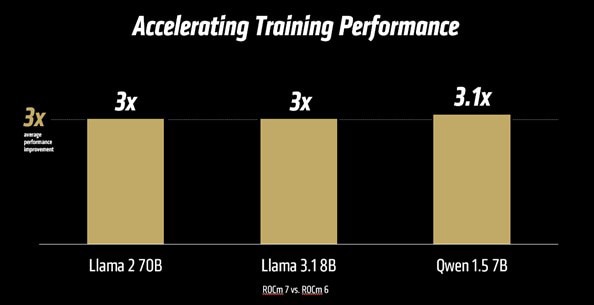
- Performance Uplift: ROCm 7 delivers a powerful leap in performance, boasting over 3.5X the inference capability and 3X the training prowess compared to the previous ROCm 6 release. This achievement stems from advances in usability, performance, and support for lower precision data types like FP4 and FP6. Further enhancements in communication stacks have optimized GPU utilization and data movement.
- Distributed Inference: ROCm 7 introduces a robust approach to distributed inference, leveraging collaboration with the open-source ecosystem, including frameworks like SGLang, vLLM, and llm-d. By embracing an open strategy, ROCm 7 is built alongside these partners, co-developing shared interfaces and primitives to enable efficient distributed inference on AMD platforms.
- Enterprise AI Solutions: ROCm Enterprise AI debuts as a robust MLOps platform designed for seamless AI operations in enterprise settings. It includes tools for model fine-tuning with industry-specific data and integration with both structured and unstructured workflows, facilitated by partnerships within our ecosystem for developing reference applications like chatbots and document summarizations.
- ROCm on Radeon and Windows: Expanding the ROCm experience beyond the cloud, ROCm 7 supports development on Ryzen laptops and workstations, enabling consistent innovation from cloud to client. With expected availability from 2H 2025, ROCm will feature in major distributions, positioning Windows as a first-class, fully supported OS, ensuring portability and efficiency on home and enterprise setups.
Partnering to Power the Open AI Ecosystem
Featured ROCm Ecosystem Partners:
- Meta – Running ranking, recommendation, and content generation workloads on AMD Instinct GPUs, including Llama models supported by ROCm improvements.
- Microsoft - Instinct MI300X is now powering both proprietary and open-source models in production on Azure.
- Red Hat® OpenShift® AI – Enabling scalable LLM inference and AI operations with ROCm on Red Hat OpenShift AI for hybrid cloud environments.
- Cohere – Deploying the 104B-parameter Command R+ model on AMD Instinct GPUs using vLLM and ROCm for enterprise-grade inference.
This deep partner collaboration ensures developers have access to best-in-class tooling, continuous performance improvements, and an open environment to iterate and deploy rapidly.
AMD Developer Cloud: Frictionless Access to World-Class Compute
Complementing ROCm 7 is the AMD Developer Cloud, now broadly available to the global developer and open-source communities. This fully managed environment provides instant access to AMD Instinct MI300X GPUs—with zero hardware investment or local setup required.
Highlights of the AMD Developer Cloud:
- Zero-Setup Environment: Launch cloud-based Jupyter Notebooks instantly—no installation needed. Easy setup with just Github or an email address.
- Pre-Installed Docker Containers and Flexibility: Docker containers preloaded with popular AI software, minimizing setup time, while giving developers the flexibility to customize code to fit their specific needs.
- Seeding MI350 systems on Day-0 with the ecosystem including vVLLM, SGLang, HAO AI lab, Stanford AI Lab.
- Day-0 support includes Instinct MI350 Cis for PyTorch and Triton CL.
- Scalable Compute Options:
- Small: 1x MI300X GPU (192 GB GPU memory)
- Large: 8x MI300X GPUs (1536 GB GPU memory)
- Complimentary Developer Credits: Apply for 25 complimentary cloud to start—with up to 50 additional hours available through programs like the ROCm Star Developer Certificate.
Whether you're fine-tuning LLMs, benchmarking inference performance, or building a scalable inference stack, the AMD Developer Cloud gives you the tools and flexibility to get started instantly—and grow without limits.
Powered by an Expanding AI Ecosystem
What sets the AMD Developer Cloud apart is not just its infrastructure—but the vibrant ecosystem that supports and scales with it.

Developer Cloud Ecosystem Highlights:
- OpenAI, Midjourney, and Hugging Face: These leading AI innovators are working with AMD to accelerate inference and training workflows, showing real-world readiness and performance at scale.
- Red Hat® OpenShift® AI + AMD: Delivering Kubernetes-native AI lifecycle management and secure hybrid cloud support via ROCm on OpenShift AI.
- Berkeley Sky Computing Lab & vLLM: Collaborating with AMD to advance distributed inference using AMD Instinct GPUs and the ROCm stack.
- Cohere and Modular Inc: Deploying enterprise LLMs and building optimized AI infrastructure on ROCm-powered AMD hardware.
These collaborations demonstrate that the AMD Developer Cloud is more than a compute platform—it’s a launchpad for next-generation AI innovation. From enterprise adoption to open-source experimentation, the growing network of AMD partners is actively shaping the tools and services available to every cloud user.


Related Blogs
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026
-
Introducing Instella-MoE: A State-of-the-Art Fully Open Mixture-of-Experts Language Model — ROCm Blogs
Explore Instella-MoE-16B-A3B, AMD’s fully open 16B MoE LLM with 2.8B active params per token, trained on AMD Instinct™ MI300 & MI325 GPUs.
July 23, 2026
-
Enabling Language-specific Reasoning in Multilingual Models with Reinforcement Learning — ROCm Blogs
Learn how to train multilingual reasoning models with reinforcement learning and extend context windows on AMD Instinct GPUs.
July 23, 2026
-
Agentic AI Workflows Simplified
Rocm.AI simplifies how developers build and serve with ROCm on AMD GPU’s
July 23, 2026
-
AMD Launches Helios™: The Highest Performing Rackscale AI Infrastructure Solution
AMD launches Helios, an open rack-scale AI platform connecting 72 AMD Instinct™ MI455X GPUs for frontier AI inference and training
July 23, 2026
-
Agentic AI: AMD EPYC™ 9005 CPUs Wins Today, EPYC 9006, formerly code-named “Venice”, Takes It to a New Level
AMD EPYC 9006 Series Server CPUs deliver up to 256 cores, faster memory and I/O, and a strong foundation for enterprise AI workloads, helping advance your data center for the agentic era.
July 23, 2026
-
AI Networking Built for Scale
AMD AI networking unifies front-end, scale-up, and scale-out infrastructure to accelerate training, inference, and agentic AI.
July 23, 2026
-
AMD Helios™: Resilient Scale-Up Networking for AI
Discover how AMD Helios™ delivers resilient scale-up networking for production AI with UALoE, AFM, AFOS, and vPods.
July 23, 2026








Footnotes
- MI300-080 - Testing by AMD Performance Labs as of May 15, 2025, measuring the inference performance in tokens per second (TPS) of AMD ROCm 6.x software, vLLM 0.3.3 vs. AMD ROCm 7.0 preview version SW, vLLM 0.8.5 on a system with (8) AMD Instinct MI300X GPUs running Llama 3.1-70B (TP2), Qwen 72B (TP2), and Deepseek-R1 (FP16) models with batch sizes of 1-256 and sequence lengths of 128-204. Stated performance uplift is expressed as the average TPS over the (3) LLMs tested.
Hardware Configuration
1P AMD EPYC™ 9534 CPU server with 8x AMD Instinct™ MI300X (192GB, 750W) GPUs, Supermicro AS-8125GS-TNMR2, NPS1 (1 NUMA per socket), 1.5 TiB (24 DIMMs, 4800 mts memory, 64 GiB/DIMM), 4x 3.49TB Micron 7450 storage, BIOS version: 1.8
Software Configuration(s)
Ubuntu 22.04 LTS with Linux kernel 5.15.0-119-generic
Qwen 72B and Llama 3.1-70B -
ROCm 7.0 preview version SW
PyTorch 2.7.0. Deepseek R-1 - ROCm 7.0 preview version, SGLang 0.4.6, PyTorch 2.6.0
vs.
Qwen 72 and Llama 3.1-70B - ROCm 6.x GA SW
PyTorch 2.7.0 and 2.1.1, respectively,
Deepseek R-1: ROCm 6.x GA SW
SGLang 0.4.1, PyTorch 2.5.0
Server manufacturers may vary configurations, yielding different results. Performance may vary based on configuration, software, vLLM version, and the use of the latest drivers and optimizations.
- MI300-081 - Testing conducted by AMD Performance Labs as of May 15, 2025, to measure the training performance (TFLOPS) of ROCm 7.0 preview version software, Megatron-LM, on (8) AMD Instinct MI300X GPUs running Llama 2-70B (4K), Qwen1.5-14B, and Llama3.1-8B models, and a custom docker container vs. a similarly configured system with AMD ROCm 6.0 software.
Hardware Configuration
1P AMD EPYC™ 9454 CPU, 8x AMD Instinct MI300X (192GB, 750W) GPUs, American Megatrends International LLC BIOS version: 1.8, BIOS 1.8.
Software Configuration
Ubuntu 22.04 LTS with Linux kernel 5.15.0-70-generic
ROCm 7.0., Megatron-LM, PyTorch 2.7.0
vs.
ROCm 6.0 public release SW, Megatron-LM code branches hanl/disable_te_llama2 for Llama 2-7B, guihong_dev for LLama 2-70B, renwuli/disable_te_qwen1.5 for Qwen1.5-14B, PyTorch 2.2.
Server manufacturers may vary configurations, yielding different results. Performance may vary based on configuration, software, vLLM version, and the use of the latest drivers and optimizations.
Footnotes
- MI300-080 - Testing by AMD Performance Labs as of May 15, 2025, measuring the inference performance in tokens per second (TPS) of AMD ROCm 6.x software, vLLM 0.3.3 vs. AMD ROCm 7.0 preview version SW, vLLM 0.8.5 on a system with (8) AMD Instinct MI300X GPUs running Llama 3.1-70B (TP2), Qwen 72B (TP2), and Deepseek-R1 (FP16) models with batch sizes of 1-256 and sequence lengths of 128-204. Stated performance uplift is expressed as the average TPS over the (3) LLMs tested.
Hardware Configuration
1P AMD EPYC™ 9534 CPU server with 8x AMD Instinct™ MI300X (192GB, 750W) GPUs, Supermicro AS-8125GS-TNMR2, NPS1 (1 NUMA per socket), 1.5 TiB (24 DIMMs, 4800 mts memory, 64 GiB/DIMM), 4x 3.49TB Micron 7450 storage, BIOS version: 1.8
Software Configuration(s)
Ubuntu 22.04 LTS with Linux kernel 5.15.0-119-generic
Qwen 72B and Llama 3.1-70B -
ROCm 7.0 preview version SW
PyTorch 2.7.0. Deepseek R-1 - ROCm 7.0 preview version, SGLang 0.4.6, PyTorch 2.6.0
vs.
Qwen 72 and Llama 3.1-70B - ROCm 6.x GA SW
PyTorch 2.7.0 and 2.1.1, respectively,
Deepseek R-1: ROCm 6.x GA SW
SGLang 0.4.1, PyTorch 2.5.0
Server manufacturers may vary configurations, yielding different results. Performance may vary based on configuration, software, vLLM version, and the use of the latest drivers and optimizations. - MI300-081 - Testing conducted by AMD Performance Labs as of May 15, 2025, to measure the training performance (TFLOPS) of ROCm 7.0 preview version software, Megatron-LM, on (8) AMD Instinct MI300X GPUs running Llama 2-70B (4K), Qwen1.5-14B, and Llama3.1-8B models, and a custom docker container vs. a similarly configured system with AMD ROCm 6.0 software.
Hardware Configuration
1P AMD EPYC™ 9454 CPU, 8x AMD Instinct MI300X (192GB, 750W) GPUs, American Megatrends International LLC BIOS version: 1.8, BIOS 1.8.
Software Configuration
Ubuntu 22.04 LTS with Linux kernel 5.15.0-70-generic
ROCm 7.0., Megatron-LM, PyTorch 2.7.0
vs.
ROCm 6.0 public release SW, Megatron-LM code branches hanl/disable_te_llama2 for Llama 2-7B, guihong_dev for LLama 2-70B, renwuli/disable_te_qwen1.5 for Qwen1.5-14B, PyTorch 2.2.
Server manufacturers may vary configurations, yielding different results. Performance may vary based on configuration, software, vLLM version, and the use of the latest drivers and optimizations.