Picard BAM Processing: AOCL as a Practical Option for Accelerating Picard Workflows
May 19, 2026

Introduction
In genomics research, processing billions of DNA sequence reads efficiently is critical. Modern genomics pipelines rely heavily on tools such as Picard and GATK to process large-scale sequencing datasets. Picard is widely used for manipulating high throughput sequencing data, including duplicate marking, sorting, and quality‑control metric collection, while GATK is commonly used downstream for variant discovery and genotyping workflows.
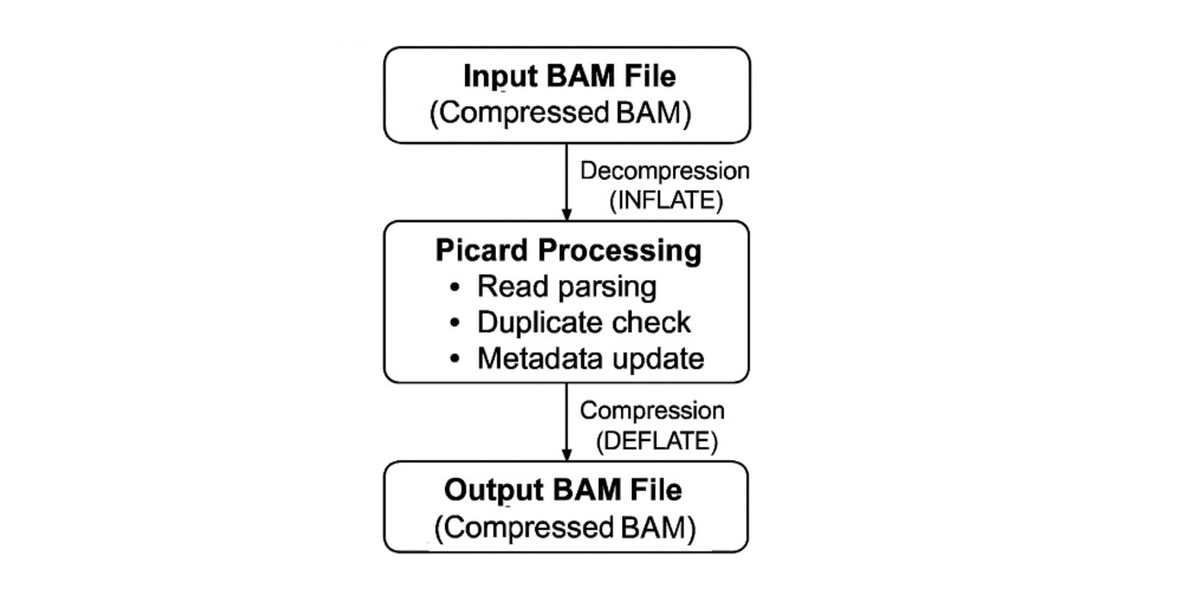
In a typical workflow, these tools operate on BAM (Binary Alignment/Map) files, which store sequencing reads aligned to a reference genome in a compressed binary format. Picard reads and decompresses input BAM files, analyzes alignment records to perform operations such as duplicate marking, and then compresses the processed data into output BAM files.
While Picard workflows are designed for correctness and reproducibility, runtime performance is often dominated by data compression and decompression during BAM read and write operations rather than by biological analysis.
This is where AMD Optimizing CPU Libraries (AOCL) can provide measurable benefits. AOCL‑Compression version 5.3 delivers highly optimized implementations of standard compression algorithms, leveraging AMD EPYC™ processor capabilities to accelerate compression related bottlenecks without requiring any code changes to existing pipelines.
This blog uses profiling driven analysis to understand where compression time is spent in Picard BAM workflows and to identify opportunities for runtime optimization. The evaluation is performed on a representative whole‑genome BAM dataset derived from the public NCBI SRA run SRR359032 (approximately 34.7 million reads, paired-end) and demonstrates how AMD AOCL‑Compression version 5.3 reduces compression overhead to improve overall performance.
Where Picard Spends Its Time
The Picard MarkDuplicates workflow was analyzed to understand execution time distribution during whole genome BAM processing. The profiling was used to identify dominant runtime contributors during normal Picard execution.
CPU profiling using perf top shows that a large fraction of execution time is spent in compression-related routines rather than in Picard’s duplicate-detection logic. The most CPU‑intensive functions correspond to core, vectorized DEFLATE and INFLATE primitives used during BAM file read and write operations. This clearly indicates that BAM I/O specifically compression and decompression are a dominant contributor to overall runtime in Picard BAM processing. Contributor to overall runtime:
Baseline Performance with Default Compression
The first evaluation was performed using Picard MarkDuplicates using the default compression setting (compression level 5) on a production whole genome public NCBI SRR359032 BAM file.
For these baseline measurements, no external compression libraries were preloaded, and USE_JDK_DEFLATER and USE_JDK_INFLATER were enabled so that all BAM I/O flows through the standard zlib path used by the JDK. All other Picard parameters were left at their defaults.
Compression and decompression in this baseline configuration operate in a single‑threaded manner per BAM stream. Picard itself processes records sequentially through the input and output streams, and no explicit multi‑threaded compression is enabled by default.
The baseline execution was performed as follows:
# Run Picard with baseline configuration (compression level 5)
java -Xmx<HEAP_SIZE> -jar picard.jar MarkDuplicates \
USE_JDK_DEFLATER=true \
USE_JDK_INFLATER=true \
INPUT=<input.bam> \
OUTPUT=<output.bam> \
METRICS_FILE=<metrics.txt> \
OPTICAL_DUPLICATE_PIXEL_DISTANCE=2500 \
CREATE_INDEX=true \
TMP_DIR=/tmp
The workflow was completed in 5.12 minutes. This runtime includes reading and decompressing the input BAM file, detecting duplicates, writing the output BAM file, and creating the BAM index.
How AOCL Makes Picard Faster
AMD AOCL-Compression library accelerates Picard BAM workflows by optimizing the core DEFLATE and INFLATE routines that dominate BAM read and write operations. AOCL uses modern x86 SIMD instructions to speed up checksum calculations, hashing, and data comparisons, while also reducing unnecessary work during match searching in the compression pipeline. These optimizations significantly lower CPU overhead during BAM I/O, allowing Picard to spend less time compressing data and more time on actual genomic analysis, all without requiring any changes to Picard code, configuration, or output format.
The underlying optimizations are available in the AMD AOCL‑Compression codebase, within the algos/zlib implementation.
Using AOCL with PICARD
To enable AOCL, the AOCL-Compression libraries were made available at runtime by updating the library path and preloading AOCL’s libz.so/libaocl_compression.so. This allows Picard to use AOCL for BAM compression without code changes.
All other Picard settings were kept identical to the baseline to isolate the impact of compression optimization.
# Download and install AOCL-Compression 5.3
# Set environment variables and Run Picard with AOCL acceleration
LD_PRELOAD=/path/to/libaocl_compression.so \
java -Xmx<HEAP_SIZE> -jar picard.jar MarkDuplicates \
USE_JDK_DEFLATER=true \
USE_JDK_INFLATER=true \
INPUT=<input.bam> \
OUTPUT=<output.bam> \
METRICS_FILE=<metrics.txt> \
OPTICAL_DUPLICATE_PIXEL_DISTANCE=2500 \
CREATE_INDEX=true \
TMP_DIR=/tmp
The USE_JDK_DEFLATER and USE_JDK_INFLATER flags remain enabled (same as the baseline) so that BAM I/O continues to flow through the JDK compression path, which is where the preloaded AOCL library is resolved at runtime.
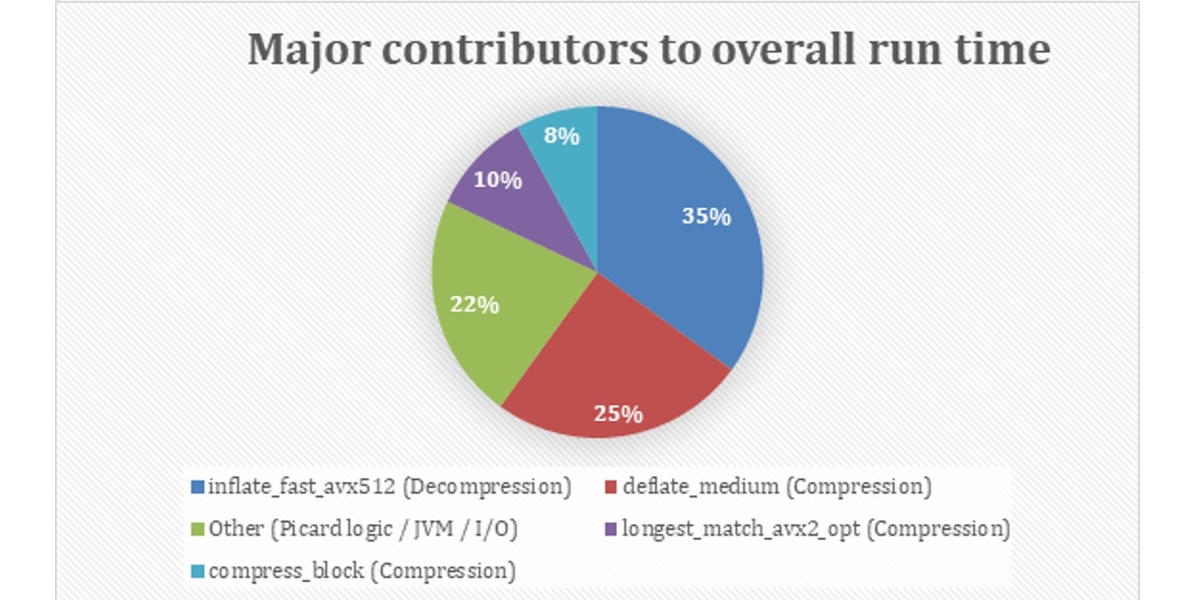
In our profiling runs, the following AOCL‑optimized routines were observed as dominant hotspots(dataset‑dependent):
- inflate_fast_avx512: ~30-35%
- deflate_medium: ~20-25%
- longest_match_avx2_opt: ~10–12%
- compress_block: ~8%
These results confirm that AOCL is actively handling both BAM decompression during input reading and BAM compression during output writing.
Runtime Improvement with AOCL
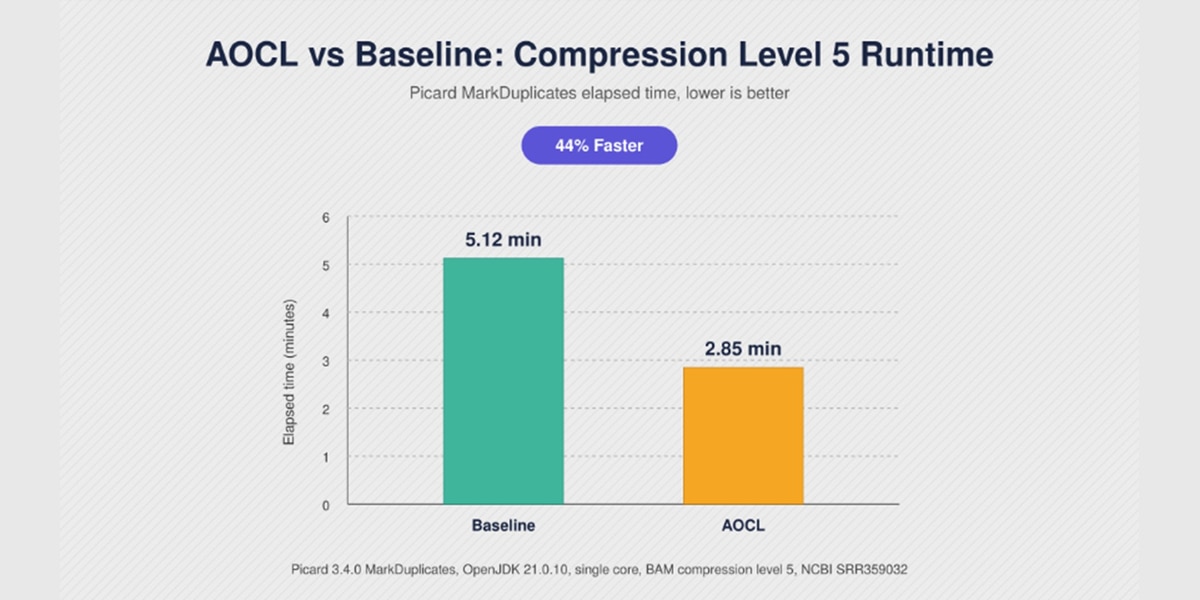
The performance impact of AOCL‑Compression was evaluated using a representative same production whole genome SRR359032 BAM file. At the default compression level (level 5), AOCL reduces overall runtime from 5.12 minutes to 2.85 minutes, delivering an ~44% reduction in elapsed time¹ while processing the same input data.
AOCL produced a ~3.5 % smaller output BAM than the baseline (2.68 GiB vs 2.78 GiB at compression level 5), delivering improvements in both runtime and compressed size.
Test Environment
All benchmarks in this study were executed on an AMD EPYC processor based system using a controlled and consistent test environment.
Hardware and System Configuration
- Processor: AMD EPYC ™ 9755 (128 cores) processor
- Cores per Socket: 128
- Simultaneous Multithreading (SMT): Disabled
- CPU Frequency: Up to 4.0 GHz (boost enabled)
- Operating System: Ubuntu 24.04 LTS
- CPU Governor: Performance
Software and Benchmark Configuration
- Picard: Version 3.4.0 (picard.jar)
- Java Runtime: OpenJDK 21.0.10 (64‑bit)
- Dataset: NCBI SRA, accession SRR359032
- BAM Compression Level: 5 (default)
The same hardware, operating system, Picard version, and input dataset were used for all benchmark runs to ensure a fair comparison.
Practical Takeaways
Profiling and benchmark results show that AMD AOCL-Compression 5.3 is a practical way to accelerate Picard BAM processing at the default compression level. With compression level 5, AOCL reduces overall runtime without requiring any changes to Picard configuration, workflow logic, or output format, making it easy to adopt in existing pipelines.
Because compression and decompression dominate Picard runtime during BAM read and write operations, optimizing the compression layer with AOCL provides consistent end‑to‑end performance improvements while preserving identical analysis results.
As a result, optimizations at the compression layer can benefit not only MarkDuplicates but also a broader class of Picard‑based and related genomics preprocessing workflows that rely heavily on BAM I/O.
References
- Picard Tools
- SAM/BAM Format Specification
- AOCL Compression Library
- GATK (Genome Analysis Toolkit)
- AOCL Developer Portal
Footnotes
Endnotes
¹ Performance Disclosure
Performance results are based on testing as of May 2026 and may not reflect all publicly available updates. See "Test Environment" section for complete system configuration and test methodology.
Benchmark Summary:
- Baseline: 5.12 minutes
- AOCL-Optimized (AOCL-Compression 5.3): 2.85 minutes
- Performance Improvement: 44% reduction in elapsed time
- Test Dataset: NCBI SRA accession SRR359032(~34.7 million reads paired-end)
- Compression Level: 5 (default), AOCL optimizations may result in <1% variation in compression ratio
- Test Platform: AMD EPYC™ 9755 processor, Ubuntu 24.04 LTS, Picard 3.4.0, OpenJDK 21.0.10
Results may vary based on system configuration, workload characteristics, dataset size, and software versions.
COPYRIGHT NOTICE
©2026 Advanced Micro Devices, Inc. All Rights Reserved.
AMD, the AMD Arrow logo, EPYC, AOCL, and combinations thereof are trademarks of Advanced Micro Devices, Inc.
Picard and GATK are developed by the Broad Institute and are subject to their respective licenses.
OpenJDK and Java are trademarks or registered trademarks of Oracle Corporation and/or its affiliates.
Ubuntu is a registered trademark of Canonical Ltd.
Other product names used in this publication are for identification purposes only and may be trademarks of their respective companies.
Certain AMD technologies may require third-party enablement or activation. Supported features may vary by operating system. Please confirm with the system manufacturer for specific features.
Footnotes
Endnotes
¹ Performance Disclosure
Performance results are based on testing as of May 2026 and may not reflect all publicly available updates. See "Test Environment" section for complete system configuration and test methodology.
Benchmark Summary:
- Baseline: 5.12 minutes
- AOCL-Optimized (AOCL-Compression 5.3): 2.85 minutes
- Performance Improvement: 44% reduction in elapsed time
- Test Dataset: NCBI SRA accession SRR359032(~34.7 million reads paired-end)
- Compression Level: 5 (default), AOCL optimizations may result in <1% variation in compression ratio
- Test Platform: AMD EPYC™ 9755 processor, Ubuntu 24.04 LTS, Picard 3.4.0, OpenJDK 21.0.10
Results may vary based on system configuration, workload characteristics, dataset size, and software versions.
COPYRIGHT NOTICE
©2026 Advanced Micro Devices, Inc. All Rights Reserved.
AMD, the AMD Arrow logo, EPYC, AOCL, and combinations thereof are trademarks of Advanced Micro Devices, Inc.
Picard and GATK are developed by the Broad Institute and are subject to their respective licenses.
OpenJDK and Java are trademarks or registered trademarks of Oracle Corporation and/or its affiliates.
Ubuntu is a registered trademark of Canonical Ltd.
Other product names used in this publication are for identification purposes only and may be trademarks of their respective companies.
Certain AMD technologies may require third-party enablement or activation. Supported features may vary by operating system. Please confirm with the system manufacturer for specific features.


Related Blogs
-
Open Standards, Real Solutions: AMD at SIGGRAPH 2026
AMD heads to DigiPro and SIGGRAPH 2026 to discuss open standards, production technology, and the fine art of Gaussian splatting.
July 17, 2026
-
From Pixels to Predictions: Edge AI Pipeline Acceleration
Learn how AMD Vitis™ AI & AMD Vitis Video Analytics SDK (VVAS) use Gstreamer to build real-time Edge AI pipelines on AMD Versal™ AI Edge Series Gen 2.
July 16, 2026
-
Multi-Accelerator Support for AIMs and AMD Solution Blueprints — ROCm Blogs
Deploy and run AIMs and AMD Solution Blueprints across AMD Instinct™ GPUs, AMD EPYC™ CPUs, and AMD Radeon™ GPUs
July 15, 2026
-
ROCm 7.14: TheRock Goes Production and Expands AMD’s AI Software Platform — ROCm Blogs
Explore what's new in ROCm 7.14: TheRock goes production, expanded hardware support, stronger AI frameworks, and enhanced profiling tools.
July 14, 2026
-
What to Expect at AMD Advancing AI 2026
Get a preview of AMD Advancing AI 2026, including key themes, sessions, and innovations shaping the future of AI. Discover how industry leaders are coming together to explore real-world use cases and strategies for scaling AI across the enterprise.
July 14, 2026
-
LogsLop: A Tiny Summarization Tool for Enormous Log Files — ROCm Blogs
LogsLop deduplicates repetitive log lines so humans and LLMs can find failures in enormous log files.
July 13, 2026
-
Announcing the ROCm Certification Program
Build AI and HPC expertise on AMD Instinctt™ GPUs. Earn the ROCmt™ Certification with hands-on, production-ready skills.
July 13, 2026
-
Serving NVFP4 Models on AMD Instinct™ MI355 Accelerators — ROCm Blogs
Learn how to serve NVFP4 models on AMD Instinct™ MI355 using an emulation pipeline in vLLM — no format conversion needed.
July 12, 2026







