Introducing ReasonLite-0.6B: Curriculum Distillation for Lightweight High-Accuracy Math Reasoning
Jan 20, 2026

Blog Highlights
- Ultra-lightweight (0.6B params) math reasoning model delivering strong contest-level performance, reaching SOTA among same-parameter models
- 75.2% on AIME 2024, competitive with much larger models (e.g., Qwen3-8B).
- Two-stage distillation curriculum: short-CoT SFT for efficiency (Turbo), then long-CoT SFT for peak accuracy (final).
- Large-scale high-quality synthetic data: 343K problems → 9.1M teacher solutions → 6.1M curated question–solution pairs.
- Fully open-source release: model weights, dataset, and code.
Introduction
Large language models (LLMs) have made tremendous strides in problem-solving, especially in math and science. Recently, specialized reasoning models have pushed the frontier even further. OpenAI’s o1 series, for example, is designed to spend more time thinking, enabling it to solve complex problems far better than earlier generations. These powerful reasoning models open the door for AI to take on challenging tasks in education, science, and engineering.
However, state-of-the-art reasoning models typically have billions of parameters, making them expensive to deploy and fine-tune. Notably, DeepSeek-R1 and Qwen3 both leverage distillation when training smaller models, transferring strong reasoning capabilities into more efficient architectures.
We believe strong reasoning capabilities should not be limited to large, resource-intensive models. To address this challenge, we introduce ReasonLite, an ultra-lightweight math reasoning model with only 0.6 billion parameters. Despite its small size, ReasonLite achieves performance on par with models over 10x larger on challenging math benchmarks.
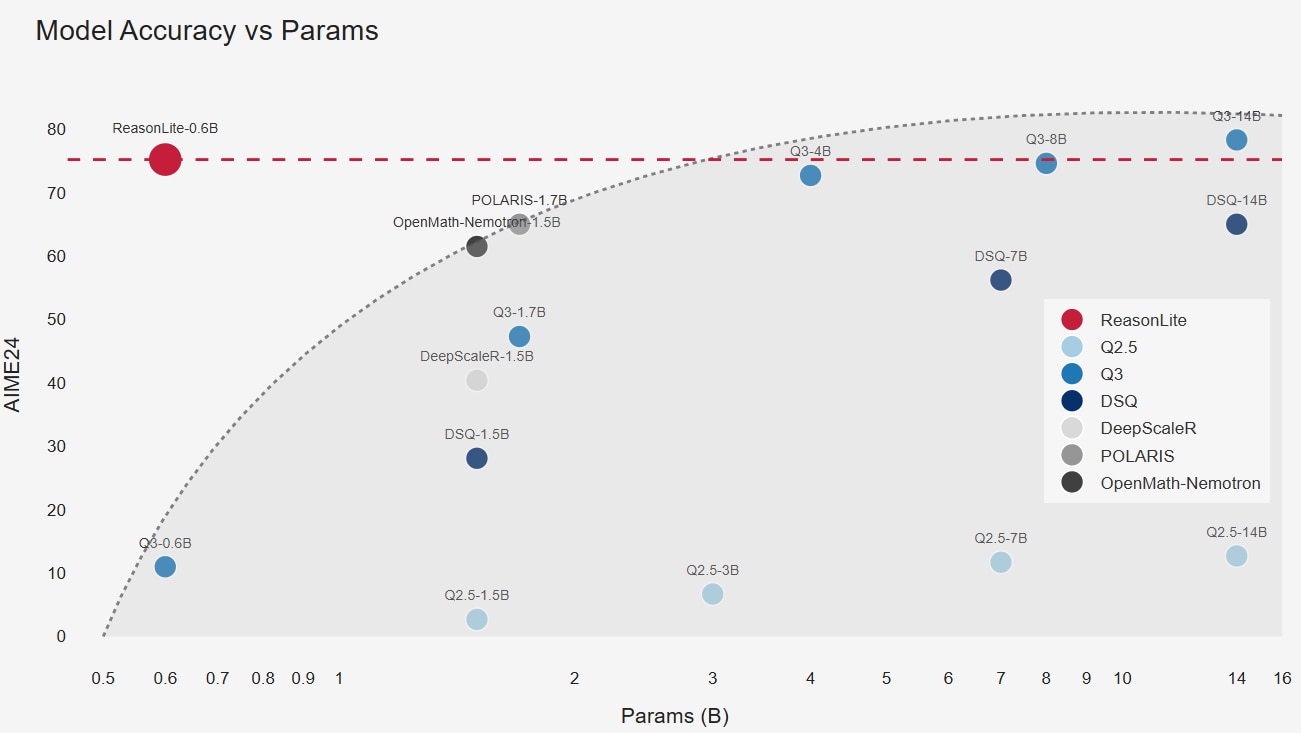
As shown in Figure 1, it reaches 75.2% accuracy on AIME 2024, comparable to Qwen3-8B in our evaluation, while using ~13x fewer parameters. This approach effectively extends the scaling behavior of reasoning models, demonstrating that with the right supervision and training recipe, small models can achieve surprisingly strong reasoning performance. To our knowledge, ReasonLite is the best-performing model of this scale on math reasoning tasks. And importantly, we are releasing everything open-source: the model weights, the training code, the synthetic datasets, and the data generation pipeline are all openly available for the community.
Method
The key to ReasonLite’s performance is a high-quality data distillation pipeline paired with a two-stage training recipe. In short, we use a stronger teacher model to generate large-scale, detailed solutions for math problems, and then train a much smaller student model on these reasoning traces. Below, we describe how we constructed the dataset and how training proceeds in two stages.
High-quality synthetic data
Training a strong math specialist requires high-quality data. We therefore leverage a powerful teacher model to synthesize a large number of high-quality reasoning examples—an approach commonly referred to as data distillation. Our dataset construction pipeline consists of four steps:
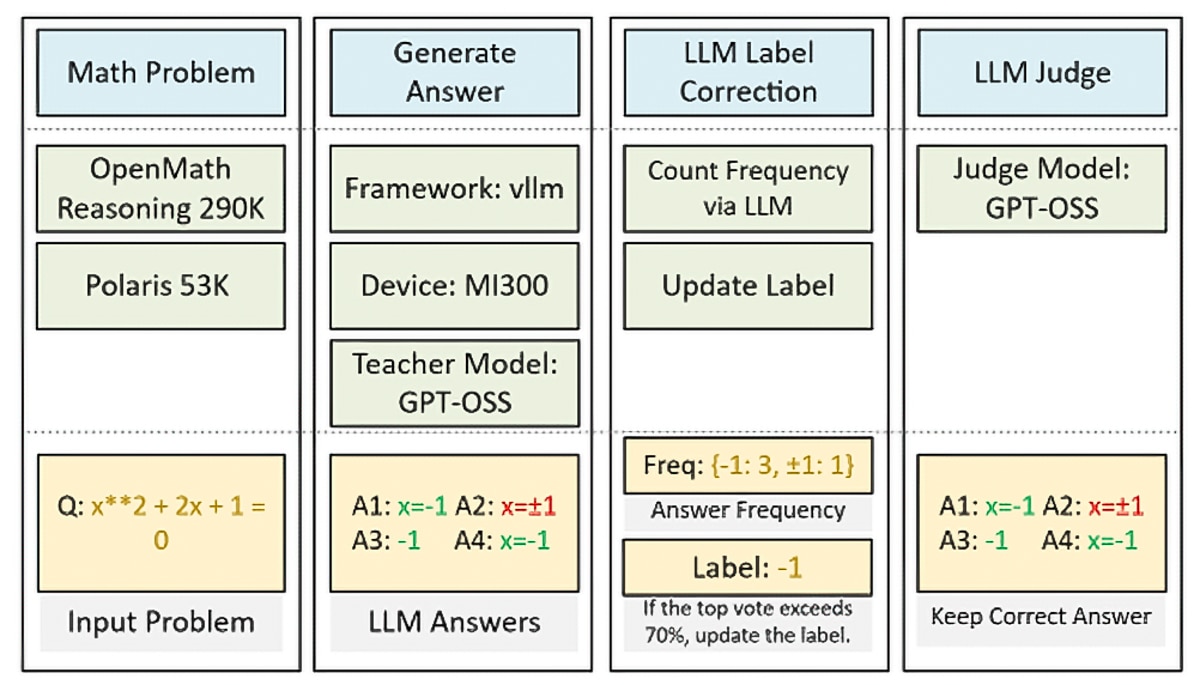
- Collect real problems
We curated 343K math problems from open sources, including the Polaris dataset and NVIDIA’s OpenMathReasoning dataset. The problems span high-school contest math to more advanced competition-level questions. - Generate solutions with a teacher model
We used a strong GPT-OSS 120B reasoning model as the teacher. For each problem, we prompted the teacher to produce step-by-step solutions under two configurations: a medium-length reasoning mode and a high-depth (more elaborate) reasoning mode. This produced an initial pool of approximately 9.1M AI-generated solutions. - Filter and vote for reliable pseudo-labels
Through case analysis, we found that the original labels in the raw datasets are not always correct. To obtain reliable supervision, we adopted a majority-voting strategy: we asked the teacher to solve each problem multiple times and treated the most frequently occurring final answer as the pseudo-label. When the winning answer exceeded a predefined confidence threshold (i.e., the majority share was sufficiently high), we considered the teacher confident and replaced the original label with the pseudo-label. We then kept only instances where the final answer and label were consistent. We used an LLM to (i) aggregate answers across multiple samples and (ii) verify consistency between the label and the generated answers. - Curate the final dataset
After filtering, we obtain a cleaned corpus of approximately 6.1M high-quality question–solution pairs. We further stratify the dataset by reasoning depth, yielding roughly 4.3M examples with short CoT and 1.8M examples with long CoT.
Two-Stage Training
We adopt a two-stage distillation strategy to progressively build the model’s mathematical reasoning capability. This curriculum-style training balances efficiency and performance by first learning from concise reasoning traces and then refining with more detailed solutions:
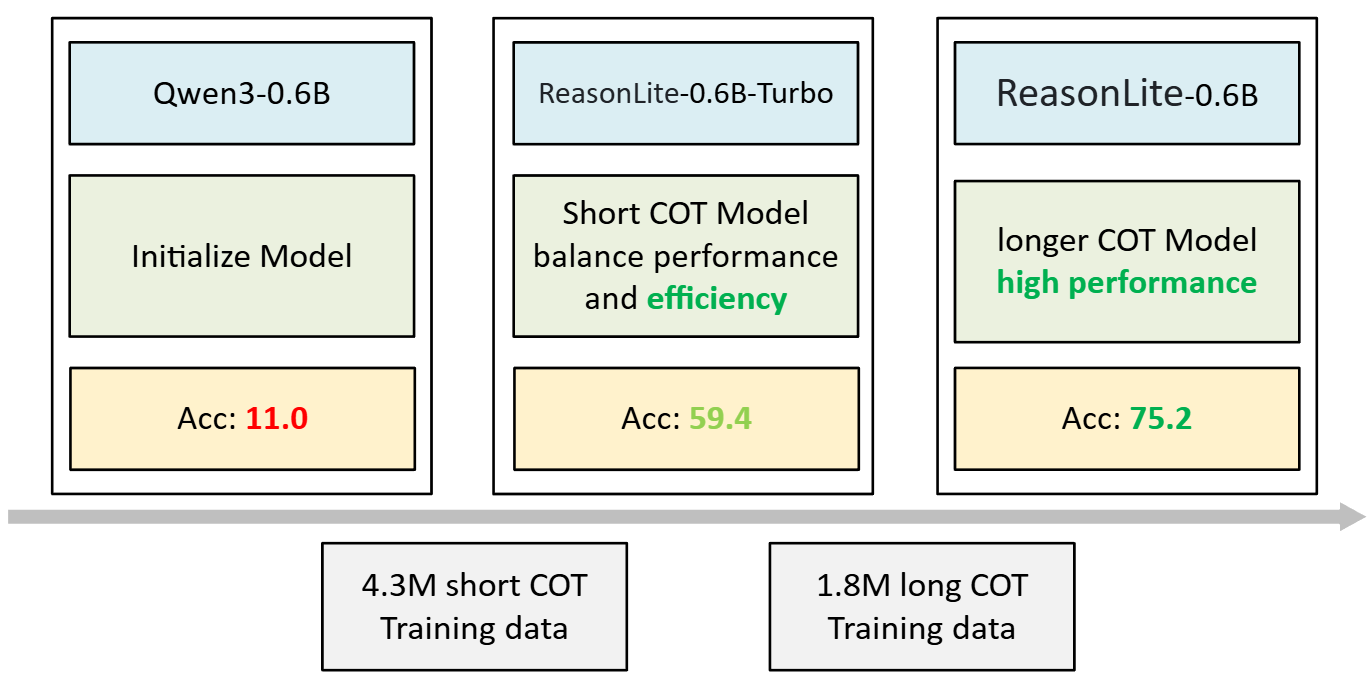
- Stage 1 – Shorter reasoning, efficiency-focused
We initialize from Qwen3-0.6B and perform supervised fine-tuning (SFT) on the 4.3M short-CoT subset, whose solutions contain more concise reasoning steps and are therefore easier and faster for the model to learn. This stage produces ReasonLite-0.6B-Turbo and delivers a substantial jump in performance: AIME24 accuracy improves from 11% (baseline) to 57.1%. Notably, the resulting model generates shorter CoT and tends to be more efficient at inference. - Stage 2 – Longer reasoning, performance-focused
Starting from the Stage 1 checkpoint, we further fine-tune on the 1.8M long-CoT subset, which contains more complex, in-depth solution traces. This phase encourages deeper reasoning and improves robustness in the hardest problems. The final model, ReasonLite-0.6B, achieves 75.2% accuracy on AIME24, boosting performance from 57.1% to 75.2% by distilling the most elaborate reasoning patterns into the student model.
Performance
We evaluate ReasonLite on a set of challenging math reasoning benchmarks. As shown in Figure 1, ReasonLite-0.6B boosts the performance of a 0.6B model on AIME24 from 11.0% to 75.2%. Remarkably, it reaches accuracy comparable to Qwen3-8B while using more than 10x fewer parameters. This result highlights how effective our distillation and curriculum training are at transferring strong reasoning ability into a compact model.
Figure 4 compares model performance under different reasoning compute budgets. The results reveal a clear trade-off between efficiency and accuracy. ReasonLite-0.6B-Turbo tends to generate shorter outputs, which helps it better balance performance and inference efficiency. In contrast, ReasonLite-0.6B produces longer, more detailed reasoning traces and achieves higher peak performance. Overall, the ReasonLite family pushes the scaling behavior of reasoning models to a new level, demonstrating that high-quality reasoning supervision can unlock substantial gains beyond what parameter count alone would suggest.
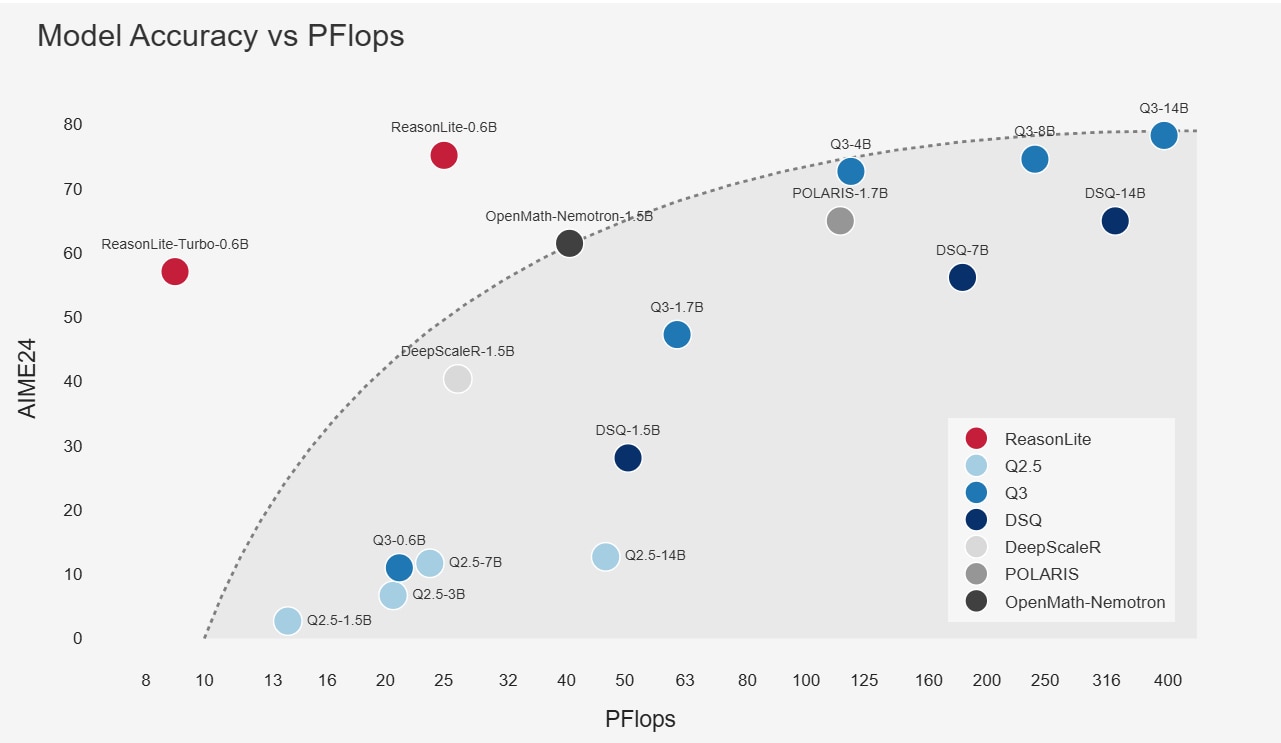
Table 1 reports results on additional benchmarks, including AMC23, AIME25, and AIME24, where ReasonLite achieves 95.2%, 62.9%, and 75.2% accuracy, respectively. We also observe that our model shows a larger improvement in pass@8 (success if any of 8 samples is correct) than many other baselines. One possible reason is that we rely purely on distillation and supervised fine-tuning rather than reinforcement learning, which may yield a more stable and generalizable training signal. Taken together, these results suggest that ReasonLite is one of the strongest math reasoning models in the 0.6B class to date, offering an unusually compelling accuracy–efficiency trade-off for practical deployment.
| Model | Parameters | AMC23 avg@16 | AMC23 pass@8 | AIME25 avg@16 | AIME25 pass@8 | AIME24 avg@16 | AIME24 pass@8 |
| Qwen2.5-14B | 14B | 58.3 | 82.3 | 12.3 | 32.3 | 12.7 | 32.4 |
| Deepseek-R1-Distill-Qwen-14B | 14B | 93.9 | 98.7 | 50.2 | 71 | 65 | 83 |
| Qwen3-0.6B | 0.6B | 52.7 | 85 | 16 | 33 | 11 | 31.5 |
| Qwen3-1.7B | 1.7B | 83.4 | 96.3 | 36 | 55.1 | 47.3 | 73.9 |
| Qwen3-4B | 4B | 96.1 | 100 | 63.5 | 85.4 | 72.7 | 85.1 |
| Qwen3-8B | 8B | 94.8 | 100 | 68.3 | 84.2 | 74.6 | 85 |
| Qwen3-14B | 14B | 98.6 | 98.7 | 71.5 | 84.1 | 78.3 | 88.4 |
| DeepscaleR-1.5B | 1.5B | 83.8 | 95 | 29 | 48.9 | 40.4 | 69 |
| POLARIS-1.7B-Preview | 1.7B | 92.2 | 97.4 | 52.3 | 80.2 | 65 | 76.7 |
| OpenMath-Nemotron-1.5B | 1.5B | 88.8 | 96.7 | 39.8 | 65.8 | 61.5 | 81.3 |
| ReasonLite-0.6B-Turbo | 0.6B | 81.6 | 99.3 | 42.7 | 69.2 | 57.1 | 79.6 |
| ReasonLite-0.6B | 0.6B | 95.2 | 100 | 62.9 | 84.1 | 75.2 | 90.2 |
Table 1: benchmark result
Conclusion
In this blog, we introduced ReasonLite, a 0.6B math reasoning model trained purely with high-quality data distillation and supervised fine-tuning. With a carefully curated synthetic dataset and a two-stage curriculum, ReasonLite-0.6B achieves 75.2% accuracy on AIME24, delivering performance competitive with much larger models while remaining lightweight and efficient. These results show that strong reasoning performance does not require large parameter. With carefully designed distillation and training strategies, small models can learn complex reasoning patterns and achieve an excellent accuracy–efficiency trade-off, making ReasonLite well suited for practical and resource-constrained deployment. We release ReasonLite fully open-source, including model checkpoints, training code, datasets, and the data generation pipeline, and invite the community to explore, fine-tune, and build upon it for efficient reasoning applications.
Looking ahead, ReasonLite provides a strong foundation for further improvements, such as integrating reinforcement learning, stronger verifiers, or domain-specific supervision to push reasoning performance even further while preserving efficiency.
Additional Resources
- Model: https://huggingface.co/amd/ReasonLite-0.6B
- Code: https://github.com/AMD-AGI/ReasonLite
- Dataset: https://huggingface.co/datasets/amd/ReasonLite-Dataset



Related Blogs
-
Kimi Code in MXFP4 on AMD GPUs
Discover how ATOM accelerates Kimi K2.5, K2.6, and K2.7-Code inference with optimized serving on AMD Instinct™ GPUs.
July 21, 2026
-
AMD Data Intelligence Platform: Open Modular Blueprint
See how AMD built OPTIMA, an open data intelligence platform that connects enterprise data for AI agents, analytics, and automation.
July 21, 2026
-
Rebuilding Agentic AI for AMD GPU
AMD and Moonshot AI built an agentic AI serving stack that optimizes KV cache, scheduling, and GPU performance on AMD Instinct™ GPUs
July 21, 2026
-
Efficient MiniMax-M3 Inference on AMD Instinct GPUs with ATOM and ATOMesh — ROCm Blogs
Serve and benchmark MiniMax-M3 on AMD Instinct MI355X GPUs using ATOM and ATOMesh with EAGLE3 speculative decoding.
July 20, 2026
-
Train and Run Models on AMD GPUs with Unsloth
Train, fine-tune, run AI models with Unsloth on AMD GPUs across Windows, WSL and Linux, with native inference for leading models.
July 20, 2026
-
Microsoft Azure Expanding AI Infra Choice with AMD Helios™
Microsoft and AMD expand Azure AI infrastructure with AMD Instinct MI455X and Helios, delivering more choice, scale, and efficiency.
July 20, 2026
-
GEAK V3: Agent-Driven, Repository-Level GPU Kernel Optimization across HIP, Triton, and FlyDSL on AMD GPUs — ROCm Blogs
Explore GEAK v3: agent-driven, repository-level GPU kernel optimization across HIP, Triton, and FlyDSL on AMD Instinct™ GPUs.
July 19, 2026
-
Open Standards, Real Solutions: AMD at SIGGRAPH 2026
AMD heads to DigiPro and SIGGRAPH 2026 to discuss open standards, production technology, and the fine art of Gaussian splatting.
July 17, 2026







