Accelerating LLM Startup on AMD Ryzen AI with Two-Phase Custom Op Initialization
May 21, 2026

On-device LLM inference with AMD Ryzen™ AI processors splits the workload across the NPU and integrated GPU: the NPU handles compute-intensive prefill with up to 50 TOPS of AI Engine performance, while the iGPU handles the memory-bound decode phase. This hybrid execution model, built atop ONNX Runtime and the AMD custom operator library, delivers low time-to-first-token (TTFT) and high tokens-per-second (TPS) — but it introduces a hidden startup cost.
Before a single token can be generated, the inference runtime must create and configure every NPU custom operator — including layer normalization, quantized matrix multiplication, multi-head attention, and fused MLP blocks. Each operator must read its configuration from the model graph, allocate device memory on the NPU, set up accelerator kernels, and transfer model weights. For a multi-layer transformer model, this means many operator initializations run sequentially on a single thread.
In this blog, we describe a two-phase deferred initialization technique that separates model-reading work from device-setup work, running them on different threads to eliminate cross-domain CPU cache pollution. The result is a meaningful reduction in model load time. We achieved up to 10× faster LLM initialization (from ~10s to ~1s) [i]— as measured on Qwen3-4B running on AMD Ryzen™ AI — with zero impact on inference correctness.
The Problem: Cross-Domain Cache Thrashing
Understanding the bottleneck requires looking at what happens inside each operator’s constructor during model loading.
Image Zoom
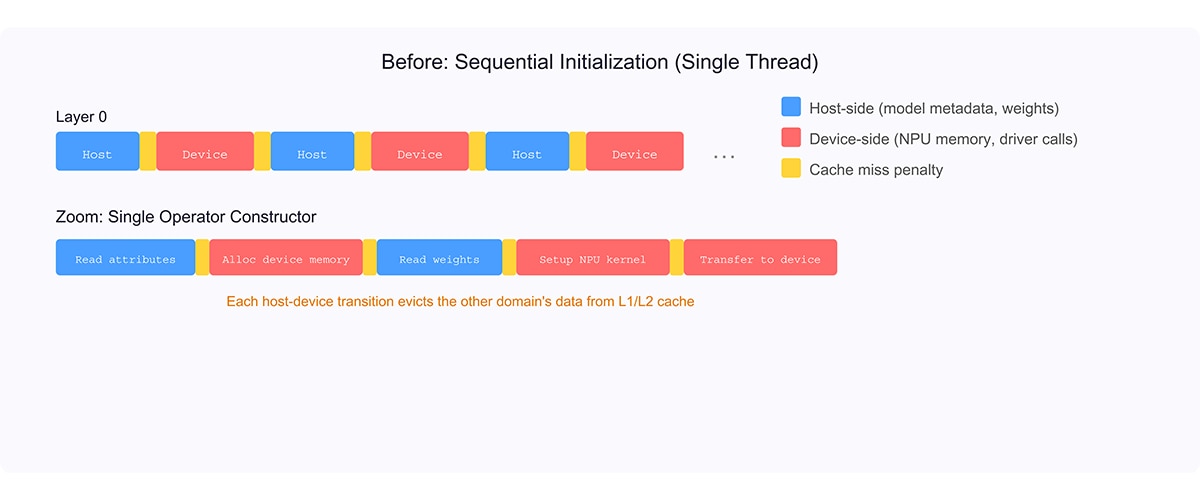
In the original implementation, a single operator constructor performed both host-side work (reading model attributes and weight tensors from the ONNX graph) and device-side work (allocating NPU memory, creating accelerator kernels, transferring weights to the device). These two workloads operate on fundamentally different memory regions:
- Host-side model access touches the inference runtime’s internal data structures — model metadata, parsed attributes, and weight tensor memory pools managed by ONNX Runtime.
- Device-side NPU setup transitions into kernel mode via the NPU driver, working with device memory allocation, accelerator kernel configuration, and host-to-device data transfers.
When these two domains alternate on the same thread, each transition evicts the previous domain’s hot data from the CPU’s L1 and L2 caches. For a multi-layer transformer — each layer containing multiple custom operators for normalization, attention, and MLP — this means many cache-thrashing transitions during a single model load.
Key Insight: The performance bottleneck is not raw computation but cross-domain CPU cache pollution. Host-side model reads and device-side driver calls work on disjoint memory regions. Interleaving them on one thread forces the CPU to repeatedly evict and reload cache lines, turning what should be streaming memory access into random access patterns.
The Solution: Two-Phase Deferred Initialization
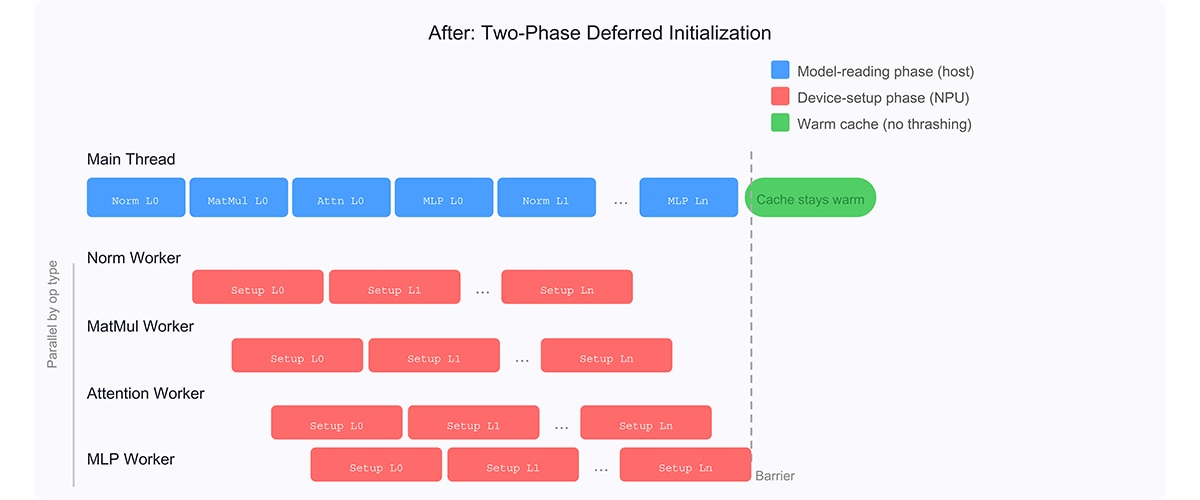
The core idea is simple: split each operator constructor into two phases, then batch all phase-1 work together before running phase-2 work on separate threads.
Phase 1: Model-Reading Phase (Main Thread)
The first phase runs in the operator constructor on the main thread — the only thread that has access to the ONNX Runtime model-reading API. This phase:
- Reads all ONNX node attributes (normalization parameters, matrix dimensions, attention head configuration, etc.)
- Extracts constant weight tensors from the ONNX graph
- Captures session configuration parameters
- Stores everything needed for phase 2 into local state
Phase 2: Device-Setup Phase (Background Thread)
The second phase performs all NPU device work, with no access to the model-reading API:
- Creates NPU accelerator kernels for each operation type
- Allocates device memory buffers on the NPU
- Formats and transfers model weights to device memory
- Sets up kernel execution shapes and parameters
Image Zoom
Grouped Thread Pool Design
A task pool manages one dedicated worker thread per operator type. This design satisfies two constraints:
- Same-type serialization: operators of the same type (e.g., all normalization layers) share per-type state and must not initialize concurrently. Each group’s worker thread processes its tasks in FIFO order.
- Cross-type parallelism: normalization, matrix multiplication, attention, and MLP operators operate on independent state and can initialize in parallel on separate threads.
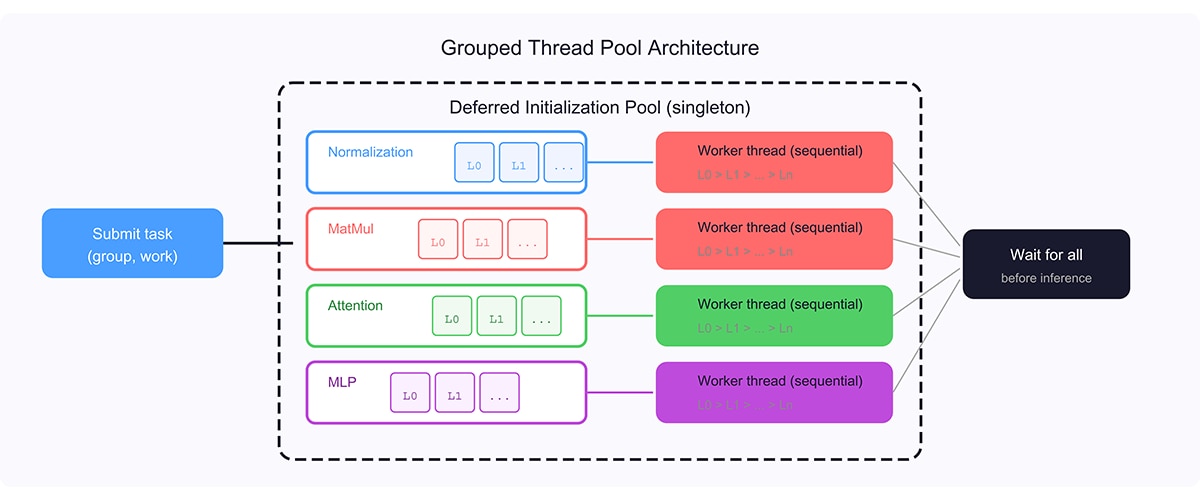
When deferred initialization is disabled (the default), each operator’s device-setup work runs inline in the constructor — preserving the original behavior. When enabled, the constructor only runs the model-reading phase and submits the device-setup phase to the pool. This makes the feature a zero-cost opt-in.
Correctness Guarantees
Correctness is ensured through three mechanisms:
1. Lazy Barrier at First Inference
Every operator’s compute method checks whether background initialization has completed before executing any NPU work. A one-shot barrier guarantees this check happens exactly once, blocking the first inference call until all background setup finishes.
2. Per-Group Sequential Execution
Each operator type group has exactly one worker thread. Tasks within a group run in FIFO order, so per-type shared state is never accessed concurrently by operators of the same type.
3. Opt-in Activation
The feature is entirely opt-in via an environment variable. When not enabled, the code path is identical to the original sequential implementation. This allows safe rollout and side-by-side comparison.
Why Cache Separation Matters More Than Parallelism
Although the per-type worker threads run concurrently, profiling shows that the majority of the speedup comes from the first change: running all model-reading phases consecutively on the main thread. This keeps the inference runtime’s data structures hot in the L1/L2 cache across all operator constructions, instead of evicting them with every device driver call.
The additional parallelism between operator types provides a secondary benefit by overlapping device driver latency across groups. But the dominant effect is the elimination of cache pollution — not the parallel execution itself.
Summary
Model initialization is a critical but often overlooked component of the user experience for on-device LLM inference. On AMD Ryzen™ AI PCs, where NPU custom operators must configure hardware resources via the device driver, initialization time can dominate the gap between application launch and first-token generation.
The two-phase deferred initialization technique addresses this by recognizing that model-reading and device-setup are fundamentally incompatible with cache neighbors. By separating them into distinct execution phases on distinct threads, we eliminate cross-domain cache pollution and achieve up to 10× faster operator initialization (from ~10s to ~1s) — as measured on Qwen3-4B running on AMD Ryzen™ AI — all with zero impact on inference correctness.
[1] tested on HP OmniBook 7 Aero Laptop 13-bg1xxx with AMD Ryzen AI 7 H 350 w/Radeon 860M, 32GB memory


Related Blogs
-
Train and Run Models on AMD GPUs with Unsloth
Train, fine-tune, run AI models with Unsloth on AMD GPUs across Windows, WSL and Linux, with native inference for leading models.
July 20, 2026
-
Microsoft Azure Expanding AI Infra Choice with AMD Helios™
Microsoft and AMD expand Azure AI infrastructure with AMD Instinct MI455X and Helios, delivering more choice, scale, and efficiency.
July 20, 2026
-
Open Standards, Real Solutions: AMD at SIGGRAPH 2026
AMD heads to DigiPro and SIGGRAPH 2026 to discuss open standards, production technology, and the fine art of Gaussian splatting.
July 17, 2026
-
FastFlowLM Joins AMD to Advance AI Inference
The FastFlowLM team has joined AMD, marking another key step in AMD’s strategy to advance AI performance and efficiency across the stack.
July 17, 2026
-
Running Cloud Agents? Your Most Important Upgrade Could be an AMD Zen 5 CPU
As agents begin navigating applications, coordinating tools and completing real work, the local CPU is becoming a critical part of the AI execution pipeline.
July 16, 2026
-
From Vector Search to Agentic RAG: Building an Enterprise Research Analyst with hipVS — ROCm Blogs
Learn how to build an agentic RAG research assistant using hipVS GPU-accelerated vector search on AMD Instinct GPUs, with multi-query decomposition, parallel retrieval, and cited sources synthesis.
July 14, 2026
-
When a Faster Kernel Doesn’t Speed Up Serving: Profiling FP8 KV Cache on AMD Instinct MI308X — ROCm Blogs
Learn how a 34% faster FP8 KV cache kernel delivered 0% E2E speedup, and how profiling attribution exposed the hidden dtype-cast cost on MI308X.
July 14, 2026
-
What to Expect at AMD Advancing AI 2026
Get a preview of AMD Advancing AI 2026, including key themes, sessions, and innovations shaping the future of AI. Discover how industry leaders are coming together to explore real-world use cases and strategies for scaling AI across the enterprise.
July 14, 2026







