ZenDNN 5.2.1: Deepening Quantization and Expanding the AI Inference Frontier on AMD EPYC™ CPUs
Apr 24, 2026

With ZenDNN 5.2, we redefined what x86 CPUs could achieve in AI inference, delivering a major step up in performance, a seamless vLLM plugin, and a completely re-engineered runtime. That release was about laying a new foundation. ZenDNN 5.2.1 is about building on it. This incremental release sharpens the quantization story, extends the ecosystem reach, and pushes the performance envelope further, all without breaking a single line of your existing code.
The headline: quantization on AMD EPYC™ processors just got significantly more capable. With asymmetric INT4 Weight-Only Quantization (WOQ), INT8 dynamic quantization through vLLM, and fused RMSNorm kernels, ZenDNN 5.2.1 turns the experimental quantization support from 5.2 into a production-grade pipeline. And we've expanded vLLM compatibility all the way to version 0.18.0, helping ensure alignment with the rapidly evolving open-source inference ecosystem.
Why This Matters: From Experimental to Production-Ready
ZenDNN 5.2 introduced quantization as an experimental capability. With 5.2.1, we're maturing that story across multiple dimensions:
- Smaller Models, Same Intelligence: Asymmetric 4-bit WOQ allows more aggressive model compression while preserving accuracy, enabling production deployment of quantized LLMs on CPU infrastructure.
- Dynamic Quantization at Serving Time: The new INT8 dynamic quantization path integrates directly with the vLLM serving engine. This means you can now serve dynamically quantized models through vLLM with the zentorch plugin, enabling lower latency and higher throughput at inference time.
- Agentic AI at Scale: With vLLM support now spanning versions 0.15.0 through 0.18.0, developers building autonomous AI agents can stay on the latest vLLM releases while continuing to benefit from ZenDNN acceleration. The expanded compatibility window helps ensure your agentic workloads aren't locked to a stale framework version.
- Accuracy You Can Verify: The integration with the open-source LM Evaluation Harness framework provides standardized accuracy benchmarking, giving teams the confidence to deploy quantized models knowing they meet quality thresholds.
What's Under the Hood?
ZenDNN 5.2.1 builds on the modular multi-backend architecture introduced in 5.2, extending it with deeper quantization paths and kernel-level optimizations across the ZenDNN runtime.
ZenDNN Core Runtime Enhancements
At the foundation layer, the ZenDNN runtime introduces several key capabilities:
- Asymmetric U4 Quantization: New DLP-based asymmetric unsigned 4-bit (U4) weight-only quantization API support. Multiple quantization domains are dispatched according to zero-point (ZP) type, enabling finer-grained control over quantization behavior.
- Dynamic and Static Reorder Integration: Reorder operations are now tightly integrated with MatMul, including intrinsic support for dynamic quantization in the reorder API.
- Fused Normalization Kernels: Fused add + RMS normalization with BF16, backed by dedicated AVX-512 kernels.
- AutoTuner Binning: A new binning approach for kernel selection that improves dispatch accuracy across diverse workload shapes.
Key Highlights of the Update
- Expanded vLLM Support: The zentorch plugin now supports vLLM versions 0.15.0 to 0.18.0, maintaining the zero-code-change acceleration philosophy.
- Asymmetric Weight-Only Quantization: Complete TorchAO-based asymmetric WOQ implementation (
Int4WeightOnlyOpaqueTensorConfig), including bias support andInt4OpaqueTensorintegration, moving beyond the symmetric-only experimental support in 5.2. - INT8 Dynamic Quantization via vLLM: A new dynamic qlinear operator in the zentorch backend enables serving dynamically quantized models directly through the vLLM inference engine.
- Optimized RMSNorm:
RMSNorm.forwardis now patched to use optimized C++ kernels on CPU, complemented by fused add + RMS norm AVX-512 kernels at the ZenDNN runtime level. - WOQ Operator Fusions: Fusion support for quantized linear operators helps reduce overhead and improve end-to-end quantized inference throughput.
- Modernized Stack: Full support for PyTorch 2.11.0, TensorFlow 2.21.0, and Python 3.10–3.13. TensorFlow backward build compatibility now spans TF 2.16 through 2.21 from a single unified codebase.
- Accuracy Benchmarking: Integrated open-source LM Evaluation Harness framework support for standardized accuracy evaluation of quantized models.

Quantization Deep Dive:
Weight-only Quantization (WoQ): Asymmetric Support
One of the most impactful changes in ZenDNN 5.2.1 is the support for asymmetric Weight-Only Quantization. To understand why this matters, consider how quantization works: model weights are mapped from their original floating-point range to a smaller integer range. In symmetric quantization, this mapping is centered around zero. In asymmetric quantization, the mapping can be offset, allowing it to better capture the actual distribution of weight values, which, in practice, are rarely perfectly centered.
With ZenDNN 5.2.1, this is implemented through a complete TorchAO-based pipeline using Int4WeightOnlyOpaqueTensorConfig, including:
- Full asymmetric 4-bit weight representation with zero-point handling
- Bias support for asymmetric quantized operations
- Operator fusion for quantized linear layers, helping reduce memory traffic and kernel launch overhead
- Validation through the open-source LM Evaluation Harness framework to help ensure quantized model quality
INT8 Dynamic Quantization: Quantize at Serve Time
Beyond weight-only quantization, ZenDNN 5.2.1 introduces INT8 dynamic quantization that integrates directly into the vLLM serving pipeline. Unlike static quantization, dynamic quantization computes scale factors on the fly from the actual activation values at inference time. This makes it ideal for serving workloads where input distributions vary and you want quantization benefits without a separate offline quantization workflow.
The new dynamic qlinear operator in the zentorch backend makes this seamless: simply serve your model through vLLM with the zentorch plugin, and dynamic quantization is applied automatically where beneficial.
Running Quantized Models with vLLM and ZenTorch
For quantizing LLMs with TorchAO and executing the quantized model with vLLM-ZenTorch, please refer the section 2.6 of ZenDNN 5.2.1 user manual.
Performance: Quantized Inference on AMD EPYC™ CPUs
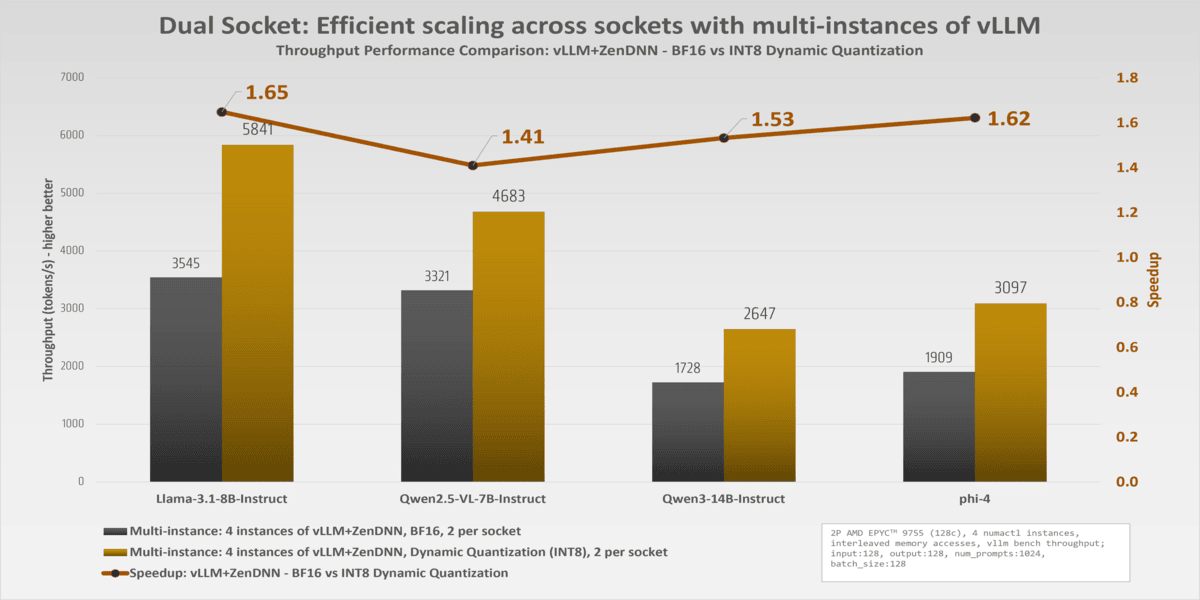
Note: Here, in each test case, we spawn 4 instances of vLLM, 2 on each socket and each instance accessing the cores in an interleaved fashion. The speedup graph speaks for itself showing the value proposition of INT8 Dynamic Quantization.
Accuracy: Quantized Inference on AMD EPYC CPUs
vLLM-zentorch quantization preserves model accuracy within tight margins of BF16. Quantized models are validated using LM Eval Harness with 5-shot prompting across GSM8K and ChartQA tasks. Dynamic quantization keeps losses under 2% across all tested models, with several matching or slightly exceeding BF16 accuracy. Asymmetric quantization shows similar resilience, with gains of up to 9% on certain vision-language tasks, making both approaches production-ready for accuracy-sensitive deployments.
| Model | Tasks (num_fewshots =5) |
Dynamic Quant Diff (baseline: BF16) |
Asymmetric Quant Diff (baseline: BF16) |
Llama-3.1-8B-Instruct |
GSM8K |
-2.06% |
-5.64% |
Qwen2.5-VL-7B-Instruct |
ChartQA |
-0.29% |
+9.18% |
Qwen3-14B-Instruct |
GSM8K |
+0.68% |
+0.85% |
phi-4 |
GSM8K |
+0.26% |
+0.18% |
Note: Negative (%) values indicate a drop in accuracy vs. the BF16 baseline; positive (%) values indicate an accuracy gain vs. the BF16 baseline.
TensorFlow Ecosystem: Broader Compatibility
On the TensorFlow side, zentf 5.2.1 upgrades to TensorFlow 2.21.0 and offers a significant quality-of-life improvement: backward build compatibility from TF 2.16 through TF 2.21 from a single unified codebase. The ./configure script auto-detects the installed TensorFlow version and applies the matching build configuration, no manual intervention required. This means teams running different TensorFlow versions across their infrastructure can build from one source tree, simplifying CI/CD pipelines and reducing maintenance burden.
Conclusion: Quantization as a First-Class Citizen
ZenDNN 5.2 laid the architectural foundation. ZenDNN 5.2.1 builds the quantization story on top of it — moving from experimental INT4 support to a mature pipeline spanning asymmetric WOQ, INT8 dynamic quantization, operator fusion, and accuracy validation through open-source LM Evaluation Harness.
Our Ongoing Commitment to the Ecosystem Our upstream-first philosophy continues. The optimizations in ZenDNN 5.2.1, from fused RMSNorm AVX-512 kernels to dynamic quantization paths, are being fed back into the core PyTorch. The expanded vLLM compatibility (now through 0.18.0) helps ensure that as the open-source inference ecosystem evolves, AMD EPYC™ CPU users are never left behind.
Run More with Less The practical impact of quantization is straightforward: models that previously required BFloat16 precision (and the memory footprint that comes with it) can now run in INT4 or INT8 with low to minimal accuracy loss (Table-1). This enables larger models on the same hardware, or the same models with significantly higher throughput. For organizations already running AMD EPYC™ infrastructure, ZenDNN 5.2.1 can extract high AI value from every rack without additional hardware investment.
Call to Action We encourage you to experience these gains firsthand. Download the updated AMD ZenDNN Plugin for PyTorch (zentorch) and AMD ZenDNN Plugin for TensorFlow (zentf) (either via pip install or from GitHub), explore our latest optimizations on GitHub, and join us in pushing the boundaries of what the x86 architecture can achieve with quantized AI inference.
Try it today:
- Download: Visit our GitHub Repository
- Documentation: Read the full ZenDNN 5.2.1 Release Notes
We'd love to hear about your performance gains — open an issue or start a discussion on our GitHub pages!
Acknowledgements
AMD team members who contributed to this effort: Sobhee Shailen, Arjit Mukhopadhyay, Avinash Chandra Pandey, Naveen Thangudu, Yogesh Vidhya Muthu, and team.
Footnotes
ZD-061: Results based on AMD Internal Testing as of 4/23/2026.
Workload Configurations: native vllm 0.18.0+cpu, ZenDNN 5.2.1, PyTorch 2.10.0+cpu, input:128, output:128, batch:128, prompts: 1024, 4 instances at BF16 and INT8 dynamic quantization
2P AMD EPYC 9755 reference system, 256 total cores, 3072GB 24x128GB DDR5-6400, BIOS RVOT1004C, Ubuntu 22.04 LTS 5.15.0-170-generic, SMT=off, Mitigations=off, Power Determinism
Results:
Model BF16 INT8 Normalized
Llama-3.1-8B-Instruct 3544.799 5841.422 1.648
Qwen2.5-VL-7B-Instruct 3321.174 4683.07 1.41
Qwen3-14B-Instruct 1727.804 2647.277 1.532
phi-4 1909.157 3096.547 1.622
Results may vary due to factors including system configurations, software versions, and BIOS settings.
ZD-062: Results based on AMD Internal Testing as of 4/23/2026.
Workload Configurations: ZenDNN 5.2.1, PyTorch 2.10.0+cpu, LM Eval Harness with 5-shot prompting across GSM8K and ChartQA tasks, Baseline BF16, Dynamic and asymmetric quantization INT8
2P AMD EPYC 9645 reference system, 192 total cores, 3072GB 24x128GB DDR5-6400, BIOS RVOT1004C, Ubuntu 22.04 LTS 5.15.0-170-generic, SMT=off, Mitigations=off, Power Determinism
Results:
Model Tasks DynQuantDiff AsymmQuantDiff
Llama-3.1-8B-Instruct -0.021 -0.056
Qwen2.5-VL-7B-Instruct -0.003 0.092
Qwen3-14B-Instruct 0.007 0.009
phi-4 0.003 0.002
Results may vary due to factors including system configurations, software versions, and BIOS settings.
Footnotes
ZD-061: Results based on AMD Internal Testing as of 4/23/2026.
Workload Configurations: native vllm 0.18.0+cpu, ZenDNN 5.2.1, PyTorch 2.10.0+cpu, input:128, output:128, batch:128, prompts: 1024, 4 instances at BF16 and INT8 dynamic quantization
2P AMD EPYC 9755 reference system, 256 total cores, 3072GB 24x128GB DDR5-6400, BIOS RVOT1004C, Ubuntu 22.04 LTS 5.15.0-170-generic, SMT=off, Mitigations=off, Power Determinism
Results:
Model BF16 INT8 Normalized
Llama-3.1-8B-Instruct 3544.799 5841.422 1.648
Qwen2.5-VL-7B-Instruct 3321.174 4683.07 1.41
Qwen3-14B-Instruct 1727.804 2647.277 1.532
phi-4 1909.157 3096.547 1.622
Results may vary due to factors including system configurations, software versions, and BIOS settings.
ZD-062: Results based on AMD Internal Testing as of 4/23/2026.
Workload Configurations: ZenDNN 5.2.1, PyTorch 2.10.0+cpu, LM Eval Harness with 5-shot prompting across GSM8K and ChartQA tasks, Baseline BF16, Dynamic and asymmetric quantization INT8
2P AMD EPYC 9645 reference system, 192 total cores, 3072GB 24x128GB DDR5-6400, BIOS RVOT1004C, Ubuntu 22.04 LTS 5.15.0-170-generic, SMT=off, Mitigations=off, Power Determinism
Results:
Model Tasks DynQuantDiff AsymmQuantDiff
Llama-3.1-8B-Instruct -0.021 -0.056
Qwen2.5-VL-7B-Instruct -0.003 0.092
Qwen3-14B-Instruct 0.007 0.009
phi-4 0.003 0.002
Results may vary due to factors including system configurations, software versions, and BIOS settings.


Related Blogs
-
The Importance of Open Ecosystems for Agentic AI Deployment
Enterprise agents need access to applications and data across the business. Open ecosystems help prevent AI vendor lock-in from standing in their way
July 30, 2026
-
Advancing AI 2026 Developer Sessions
See how Advancing AI 2026 brought together 2,000+ developers for workshops, technical sessions, and hands-on demos.
July 30, 2026
-
Closing the GPU Cluster Validation Gap: A Kubernetes-Native Approach with CVF — ROCm Blogs
Learn how to validate AMD GPU clusters end-to-end with CVF: hardware acceptance, mesh bandwidth, RDMA, and RCCL testing in one pipeline.
July 28, 2026
-
AMD GPU Operator v1.5.0: DRA Support, Automated GPU Node Recovery, and Expanded Kubernetes Infrastructure Control — ROCm Blogs
Discover how AMD GPU Operator v1.5.0 improves GPU scheduling, automates node recovery, and expands Kubernetes control.
July 27, 2026
-
Kimi-K3 on AMD Instinct GPUs
Day 0 support for Kimi-K3 on AMD Instinct MI355X GPUs with validated TP8 setups.
July 27, 2026
-
Attention Decode on AMD MI450 GPUs: A Gluon Kernel Optimization Guide — ROCm Blogs
Learn how to design a high-performance attention decode kernel on AMD MI450 GPUs using Gluon.
July 26, 2026
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026
-
Run Hugging Face Models
Launch Hugging Face models instantly with One-Click notebooks on AMD GPUs.
July 23, 2026







